Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
本集群搭建案例,以3节点为例进行搭建,角色分配如下:
hdp-node- NameNode SecondaryNameNode ResourceManager
hdp-node- DataNode NodeManager
hdp-node- DataNode NodeManager
2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
▨ Vmware 12.0
▨ Centos 7.0 64bit
3网络环境准备
▨ 采用NAT方式联网
▨ 网关地址:192.168.33.1
▨ 3个服务器节点IP地址:192.168.33.101、192.168.33.102、192.168.33.103
▨ 子网掩码:255.255.255.0
4服务器系统设置
▨ 添加HADOOP用户
▨ 为HADOOP用户分配sudoer权限
▨ 同步时间
▨ 设置主机名
◈ hdp-node-01
◈ hdp-node-02
◈ hdp-node-03
▨ 配置内网域名映射:
◈ 192.168.33.101 hdp-node-01
◈ 192.168.33.102 hdp-node-02
◈ 192.168.33.103 hdp-node-03
▨ 配置ssh免密登陆
▨ 配置防火墙
5JDK环境安装
▨ 上传jdk安装包
▨ 规划安装目录 /home/hadoop/apps/jdk_1.7.65
▨ 解压安装包
▨ 配置环境变量 /etc/profile
6HADOOP安装部署
▨ 上传HADOOP安装包
▨ 规划安装目录 /home/hadoop/apps/hadoop-2.6.5
▨ 解压安装包 tar –zxvf hadoop-2.6.5 –C apps/
▨ 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk1..0_45
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-node-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/HADOOP/apps/hadoop-2.6.5/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp-node-01:50090</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi salves
hdp-node-02
hdp-node-03
7启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
查看集群状态
jps
bin/hdfs dfsadmin -report
8测试——运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.5.jar wordcount /wordcount/input /wordcount/output
9HDFS使用
1、查看集群状态
命令: hdfs dfsadmin –report
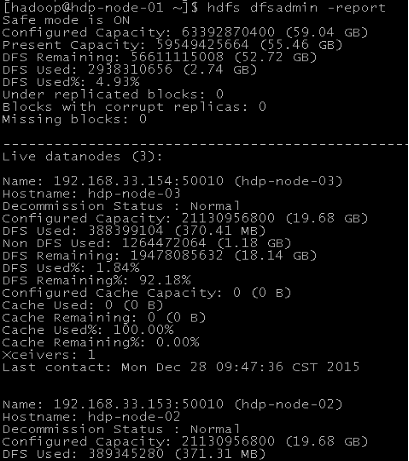
可以看出,集群共有3个datanode可用
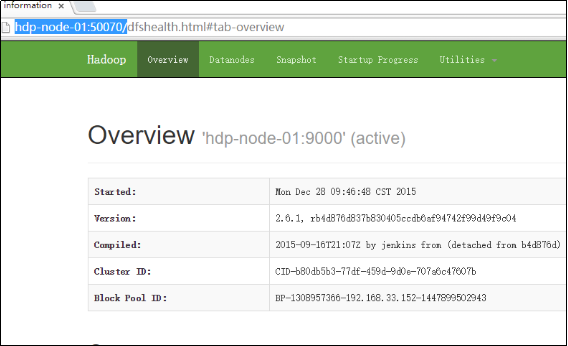
也可打开web控制台查看HDFS集群信息,在浏览器打开http://hdp-node-01:50070/
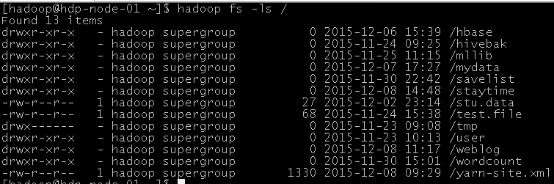
2、上传文件到HDFS
▣ 查看HDFS中的目录信息
命令: hadoop fs –ls /
▣ 上传文件
命令: hadoop fs -put ./ scala-2.10.6.tgz to /

出处:http://www.cnblogs.com/jerehedu/
版权声明:本文版权归烟台杰瑞教育科技有限公司和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
技术咨询:

Java+大数据开发——Hadoop集群环境搭建(一)的更多相关文章
- Java+大数据开发——Hadoop集群环境搭建(二)
1. MAPREDUCE使用 mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 2. Demo开发--wo ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- 配置本地无密码 SSH登录远程服务器
下面这幅图简单来说就是你本地有一把钥匙,服务器也有一把钥匙,当登录的时候本地的钥匙与服务器的进行对比,通过算法的判定,监测是否具有权限的用户 第一步,在本地配置这把钥匙生成私钥与公钥: 打开.ssh目 ...
- Inno Setup 系列之安装、卸载前检测进程运行情况并关闭相应进程
需求 最近用 Inno Setup 做一个exe,可是在安装之前要停止正在运行的相应进程或者在卸载之前要停止正在运行的相应进程,可是发现它自身的方法不能满足要求,最后经过度娘的耐心帮助下终于在网上找到 ...
- python 全栈开发,Day117(popup,Model类的继承,crm业务开发)
昨日内容回顾 第一部分:权限相关 1. 权限基本流程 用户登录成功后获取权限信息,将[权限和菜单]信息写入到session. 以后用户在来访问,在中间件中进行权限校验. 为了提升用户体验友好度,在后台 ...
- vijos 1128 N个数选K个数 (DFS )
从 n 个整数中任选 k 个整数相加,可分别得到一系列的和 要求你计算出和为素数共有多少种 IN4 33 7 12 19 OUT1 # include <iostream> # inclu ...
- Spring的控制反转和依赖注入
Spring的官网:https://spring.io/ Struts与Hibernate可以做什么事? Struts, Mvc中控制层解决方案 可以进行请求数据自动封装.类型转换.文件上传.效验… ...
- Shiro介绍
前言 本文主要讲解的知识点有以下: 权限管理的基础知识 模型 粗粒度和细粒度的概念 回顾URL拦截的实现 Shiro的介绍与简单入门 一.Shiro基础知识 在学习Shiro这个框架之前,首先我们要先 ...
- POJ - 1185 敌兵炮阵
POJ - 3254 中文题.. 思路:这题可把我恶心坏了,我刚开始的思路其实是正确的... 首先我想开个dp[i][s1][s2]保存到 i行 为止当前行状态为s1,上一行状态为s2 的最大个数,然 ...
- Mistwald POJ
一开始看不出来是快速幂矩阵的题目 先要把整个地图离散化为1,2,3,4,.... 连成一个有向图 邻接矩阵的平方意为:假如a->b 且b->c 那么一次平方后 a->c ...
- PyCharm 和 IntelliJ IDEA的破解激活
本教程对jetbrains全系列可用,例如:IDEA.WebStorm.phpstorm.clion等 PyCharm激活: 方法一: server选项里边输入 http://elporfirio. ...
- 洛谷 [P1024]一元三次方程求解【二分答案】
题目链接:https://www.luogu.org/problemnew/show/P1024 题目描述 有形如:ax3+bx2+cx+d=0 这样的一个一元三次方程.给出该方程中各项的系数(a,b ...