机器学习与数据科学 基于R的统计学习方法(基础部分)
1.1 机器学习的分类
监督学习:线性回归或逻辑回归,
非监督学习:是K-均值聚类, 即在数据点集中找出“聚类”。 另一种常用技术叫做主成分分析(PCA) , 用于降维,
算法的评估方法也不尽相同。 最常用的方法是将均方根误差(RMSE) 的值降到最小, 这一数值用于评价测试集的预测
结果是否准确。 RMSE评价法会在第7章进行更深入的解释。 另一种常用的评估方法是AUC, 即ROC曲线下的面积。
1.8 使用R包
有大量的通用包(当前大约是7000个) , 其中很多涉及有用的统计方法, 也有特定领域的包: 金融、 天文学、 分子生物学、 生态学等。
1. 你可以用下面给出的R脚本来找到当下可用的R包数目:
> dim(available.packages())
2. 一旦找到了满足你需求的R包, 你需要在本地配置中安装它。 例如, 这是安装lubridate包的命令:
> install.packages("lubridate")
3. 一个包只能安装一次。 安装完成后, 你需要做的是用library()把它加载到内存中。 library()函数用来加载基础R配置中未包括的函数库(函数和数据集的集合) 。
> library(lubridate)
4. 你应该去访问CRAN上该R包的页面来下载参考手册和任何可能有帮助的简介
5. 举个例子, 基础R包含有stats包, 里面有常用算法, 例
如: lm()用来拟合一个简单的线性回归模型, glm()用来拟合广义的线性模型; 如逻辑回归: hclust()用来做聚类分析, kmeans()用来做k均值聚类, prcomp()用来做基本的组成成分分析; 还有其他很多功能。
除此之外, 还有许多机器学习的附加包可以补充基础R包的功能。例如, class包中的knn()用来做k最近邻算法, tree包中的tree()用于拟合分类树或是回归树, randomForest包中的randomForest()用来实现随机树算法, e1071包中的svm()用来实现支持向量机, 还有很多其他功能。
6. 为了找到其他满足机器学习需求的R包, 你可以使用谷歌。 例如,你想寻找用来实现进化算法的包, 可以搜索“R中的进化算法”。 结果会告诉你参考DEoptim包, 这个包中含有你需要的机器学习算法。
1.9 数据集
1. 书中使用的大多数数据集都是R软件在安装时自带的
2. 你将在RStudio的Workspace标签页看到数据集的名称
data(package="plyr")
要查看某个数据集中的更多内容, 你可以使用在数据集名称前面加? 的命令
> ? airquality
你可以使用以下命令来将某个数据集加载到内存中:
> data(iris)
第2章连接数据
1. 很多机器学习和数据分析讨论的前提是你已经有干净的数据, 可以直接把它们应用在探索性数据分析工具中, 然后选择一个合适的机器学习模型。 遗憾的是, 这种情况很少发生, 更多的时候, 你需要定位数据, 确定它使用了哪种格式, 找到一个有连接数据功能的R包, 最后, 连接数据并把它读入R数据框(data frame)
2. 数据是属于同一群体的定性或定量的变量的值; 是你感兴趣的一组对象的集合, 其中的一个变量是对一项的特征的度量。

2.1 管理你的工作目录
1. 工作目录用于储存各种组成你项目的文件,包括数据文件、 R脚本、 图表文件、 RDATA文件, 也包含你分析得出的文件(Word、 PowerPoint等格式)。 有些人使用工作目录下的“data”子文件夹来存储这些数据文件。
2. R有两条命令来管理工作目录: getwd()用于检索目前的工作目录, setwd()用于创建新的工作目录。 在打开RStudio时, 你可以在R控制台中用setwd()函数来创建工作目录,
3. 相对路径 绝对路径
4. 管理工作目录的另一个方法是使用RStudio的功能: Session -> Set Working Directory -> Choose Directory来指向你需要的目录。
1.
2.2 数据文件的种类

2.3 数据的来源
访问San Francisco Data网站(data.sfgov.org) , 上
面包含了大量的市政数据集。 要用到的Parking Meter数据集, 包含了多方面的仪表特征。 目标是直接从网站上下载CSV文件格式的数据集。为此, 我们将使用download.file()指令。
2.5 读取CSV文件
CSV文件的格式很简单:文件中的每一行代表了一个观测值, 每一列代表一个变量(潜在的特征变量)。
2.6 读取Excel文件
|
2007电子表格文件中读取数据的工具: |
|
read.xlsx()和read.xlsx2()函数。 read.xlsx2()函数通常能更快地处理大型电 |
|
子表格。 |
注:
|
还需要使用library()函数来加载xlsx包, 否则使用中会找不到 |
2.7 使用文件连接
从文本文件中按行读取数据是有意义的。为此, R有一个有用的函数readLines(), 可以和文件连接一同使用。
第3章 数据处理

plyr、 dplyr、 reshape2、 stringr和lubridate这些包迟早都会用到,我们将在后面的小节中看到这些包的使用案例。
3.1 特征工程
特征工程(feature engineering) 用于识别在模型或者机器学习算法中使用的数据子集或者转换后的数据。 不同的学术分支使用不同的表述来描述同一个东西。 当描述输入到模型的数据子集时,统计学家使用“解释变量”“因变量”、 或者“预测因子”。 在另一方面,数据科学家使用“特征”。
3.2 数据管道
我建议把所有的代码片段都保存在一个主要的R脚本文件中或者工作目录下。这些脚本将成为数据管道的基础。数据管道(data pipeline) 是数据转换任务中决定性的一部分, 需获取原始数据集,然后把它们转换成适合机器学习的变换后数据集
3.3 数据采样
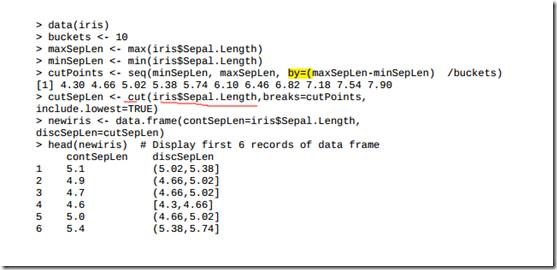
让我们使用iris数据集作为数据抽样的例子。用sample()函数来随机选择10行可重复的记录。生成的sample_index是一个整型向量, 包含了指向iris数据集中被选中的记录的索引。
> sample_index <-sample(1:nrow(iris), 10, replace=T)
3.4 修正变量名



3.5 创建新变量
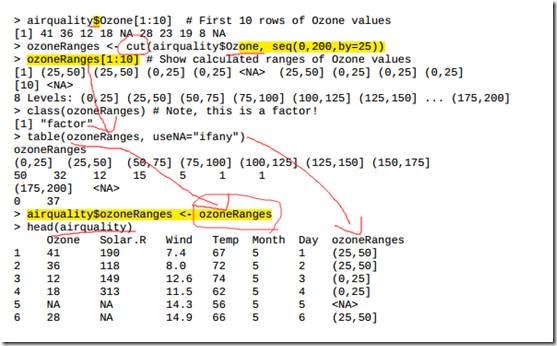
3.6 数值离散化
将一个连续值变量划分到区间中, 创建一个新因素变量的范围值,并将变量值分配到相应的范围中, 这整个过程叫做“离散化”
3.7 日期处理
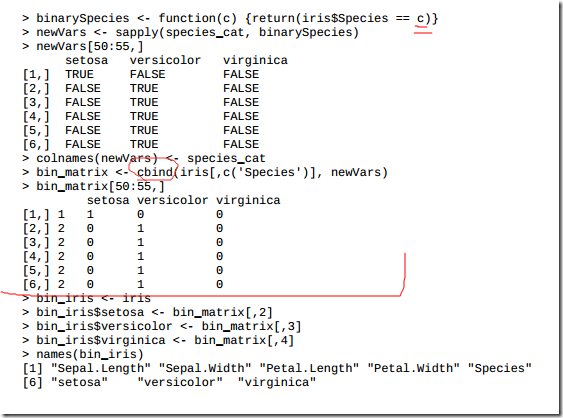
3.8 将类变量二值化
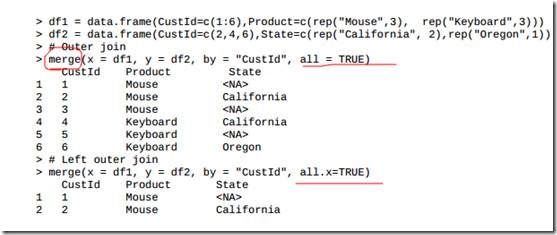
3.9 合并数据集
R中有非常有用的merge()函数, 可以基于公共变量将数据框合并到一起。 如果你熟悉SQL, 你可能已经猜到merge()和连接操作非常相似。 实际上确实如此, 不同的地方在于merge()不但可以执行内部和外部的连接, 而且可以进行左连接和右连
接。
merge()函数允许4种合并数据的方式:
内连接(inner join) : 只保留两个数据框中一致的行,指定参数
all=FALSE。
外连接(outer join) : 保留数据框中所有的行,指定all=TRUE。
左外连接(left outer join) : 包含数据框x的所有行加上数据框y中
能匹配到数据框x的所有数据, 指定all.x=TRUE。
右外连接(right outer join) : 包含数据框x的能匹配到数据框y的所
有数据, 加上数据框y中所有的行, 指定all.y=TRUE。
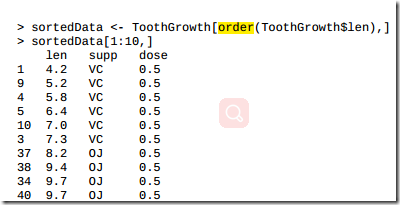
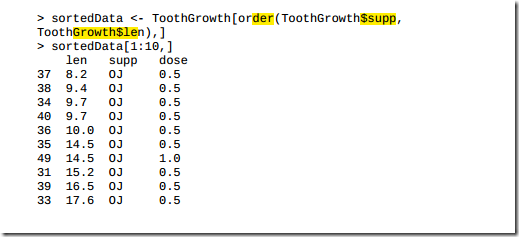
3.10 排列数据集
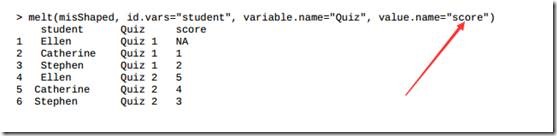
3.11 重塑数据集
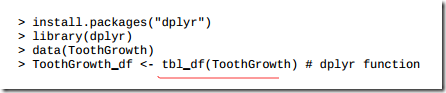
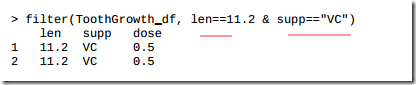
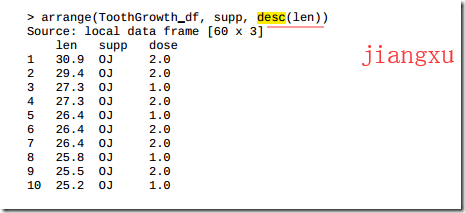
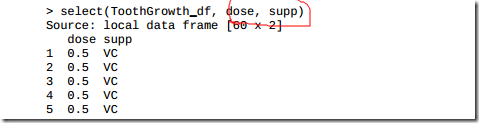
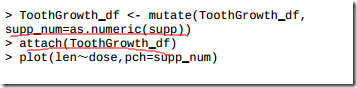
3.12 使用dplyr进行数据操作

 、
、
3.13 处理缺失数据

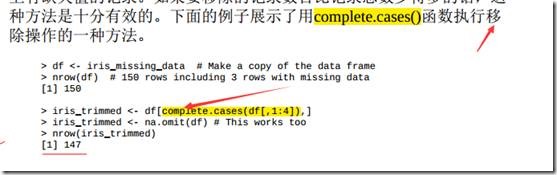
3.14 特征缩放
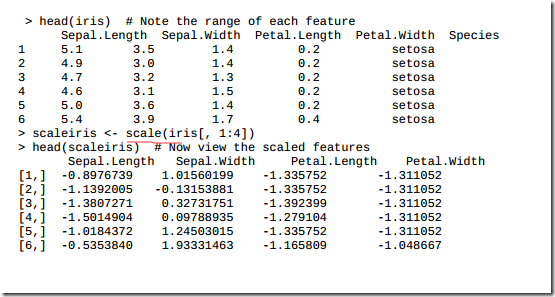
3.15 降维

快捷键
(1)清空控制台`Ct rl+L`
(2)清除变量历史记录 rm(list = ls())
比如,上图把p变量清除后,再执行就会提示
Error: object 'p' not found
(3)按Ctrl+C键,中断R正在运行的程序而不退出R软件
(4)使用快捷键这种方法,仅在RStudio中可以使用。首先选中要注释掉的行,然后按 Ctrl+shift+C ,这样就注释掉了。这其实和单行注释的方法一样,只不过RStudio帮我们简化而已。如果要取消注释的话, 依然是先选中,然后按快捷键 Ctrl+shift+C 即可。
https://technicspub. com/analytics/
上传了本书中使用的所有R源代码和注释。 同时也收录了所有的图表(很多是彩色的)
很多流行的R博客(rbloggers) 的内容: www.r-bloggers.com
变量的命名:首字母小写,第二个单词字母大写 lineCnt
数组 向量
基本语法
if(){
}
While(1){
}
For(; ;){
}
break continue
一些重要的网址收藏在R语言中,分享下
http://www.bio-info-trainee.com/2297.html (重要)
http://www.bio-info-trainee.com/2535.html
http://www.360doc.com/content/17/0906/17/41791033_685047297.shtml
R语言基础视频: https://www.imooc.com/learn/546
机器学习与数据科学 基于R的统计学习方法(基础部分)的更多相关文章
- R学习:《机器学习与数据科学基于R的统计学习方法》中文PDF+代码
当前,机器学习和数据科学都是很重要和热门的相关学科,需要深入地研究学习才能精通. <机器学习与数据科学基于R的统计学习方法>试图指导读者掌握如何完成涉及机器学习的数据科学项目.为数据科学家 ...
- (数据科学学习手札43)Plotly基础内容介绍
一.简介 Plotly是一个非常著名且强大的开源数据可视化框架,它通过构建基于浏览器显示的web形式的可交互图表来展示信息,可创建多达数十种精美的图表和地图,本文就将以jupyter notebook ...
- (数据科学学习手札41)folium基础内容介绍
一.简介 folium是js上著名的地理信息可视化库leaflet.js为Python提供的接口,通过它,我们可以通过在Python端编写代码操纵数据,来调用leaflet的相关功能,基于内建的osm ...
- (数据科学学习手札45)Scala基础知识
一.简介 由于Spark主要是由Scala编写的,虽然Python和R也各自有对Spark的支撑包,但支持程度远不及Scala,所以要想更好的学习Spark,就必须熟练掌握Scala编程语言,Scal ...
- 数据科学VS机器学习
数据科学是一个范围很广的学科.机器学习和统计学都是数据科学的一部分.机器学习中的学习一词表示算法依赖于一些数据(被用作训练集)来调整模型或算法的参数.这包含了许多的技术,比如回归.朴素贝叶斯或监督聚类 ...
- 2017数据科学报告:机器学习工程师年薪最高,Python最常用
2017数据科学报告:机器学习工程师年薪最高,Python最常用 2017-11-03 11:05 数据平台 Kaggle 近日发布了2017 机器学习及数据科学调查报告,针对最受欢迎的编程语言.不同 ...
- R数据科学-2
R数据科学(R for Data Science) Part 2:数据处理 导入-->整理-->转换 ------------------第7章 使用tibble实现简单数据框------ ...
- R数据科学-1
R数据科学(R for Data Science) Part 1:探索 by: PJX for 查漏补缺 exercise: https://jrnold.github.io/r4ds-exercis ...
- R数据科学-3
R数据科学(R for Data Science) Part 3:编程 转换--可视化--模型 --------------第13章 使用magrittr进行管道操作----------------- ...
随机推荐
- oracle_sqlplus命令行乱码问题解决
在linux以及unix中,sqlplus的上下左右.回退无法使用,会出现乱码情况. 而rlwrap这个软件就是用来解决这个的. 首先下载rlwrap包:https://linux.linuxidc. ...
- Error: php71w-common conflicts with php-common-5.4.16-46.el7.x86_64
Centos7.3 阿里云主机 安装zabbix报错 问题: [root@lvhanzhi code]# yum install -y zabbix-web-mysql zabbix-agent ma ...
- topcoder srm 410 div1
problem1 link 不包含$gridConnections$ 的联通块一定是连在所有包含$gridConnections$的联通块中最大的那一块上. import java.util.*; i ...
- linux基础之程序包管理(rpm,yum)
一.rpm 安装:rpm { -i | --install } [ install-options ] PACKAGE_FILE... -v: 显示安装时的详细信息 -vv: 显示许多难以阅读的调试信 ...
- mysql的数据类型- 特别是表示日期/时间的数据类型: 参考: http://www.cnblogs.com/bukudekong/archive/2011/06/27/2091590.html
通常认为: 日期 就是 年-月-日: 时间就是: 小时:分钟:秒 要严格区分"日期"和 "时间"的 说法. 日期就是日期, 时间就是时间, 两者是不同的!! 日 ...
- MyEclipse代码编辑器中汉字太小的解决办法(中文看不清)
问题描述:新安装的myeclipse 2014,代码编辑器中汉字很小看不清 解决办法:调整字体即可.通过菜单Windows——Preferences,输入font过滤选择Colors and Font ...
- Asp.Net 之 DropDownList的使用
这里不细说,直接上案例 <td style="width: 30px;" align="right"> 年月: </td> <td ...
- SQLServer2014 安装错误:等待数据库引擎恢复句柄失败
查了很多资料最后靠百度百科里的一票报道彻底解决困难.在次发表一下以便给后人排忧解难 已下为百度连接 https://jingyan.baidu.com/article/7908e85cb24c19af ...
- [exceltolist] - 一个excel转list的工具
https://github.com/deadzq/cp-utils-excelreader <(感谢知名网友的帮助) https://sargeraswang.com/blog/2018/1 ...
- IAR8.11.1安装与破解教程
IAR 8.11.1的安装与破解 1.IAR的安装 (1) (2)然后选择自己的调试方式驱动(jtag与swd...) (3)选择路径,一直下一步就好 ...