【Hadoop 分布式部署 五:分布式部署之分发、基本测试及监控】
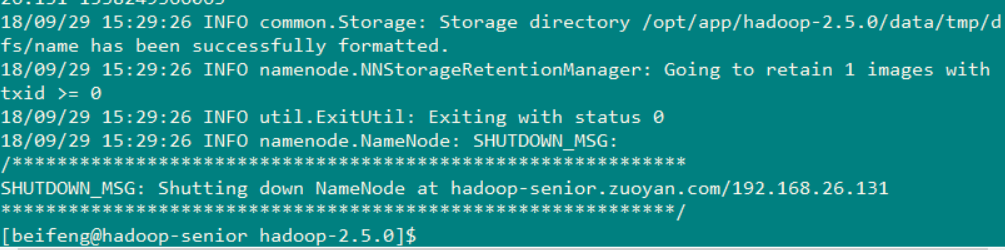
1.对 hadoop 进行格式化
到 /opt/app/hadoop-2.5.0 目录下 执行命令: bin/hdfs namenode -format
执行的效果图如下 ( 下图成功 格式化 不要没事格式化 )
2.启动dfs
执行命令(在 /opt/app/hadoop-2.5.0/目录下): sbin/start-dfs.sh
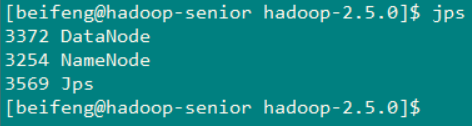
执行之后的效果就如下图 (可以看到 3个DataNode已经启动起来了,NameNode 和 secondarynamenode 也已经启动起来了)

然后在分别上这三台机器上查看一下启动情况
节点一(hadoop-senior.zuoayn.com)
节点二 (hadoop-senior02.zuoyan.com)
节点三(Hadoop-senior03.zuoyan.com)

可以看到 每个节点上执行的任务 都是我们当时设计的,我的这种情况是比较幸运的没有出现什么错误,都启动起来了,但是有的时候会出现
:Temporary failure in name resolutionop-senior02.zuoyan.com
:Temporary failure in name resolutionop-senior.zuoyan.com
出现这个原因是因为 拷贝虚拟机出现的问题 出现这种情况的原因 就是域名解析问题 机器重启 ,还有另一种方式解决
就是到每个机器上单独去启动 使用命令 :sbin/hadoop-daemon.sh start datanode
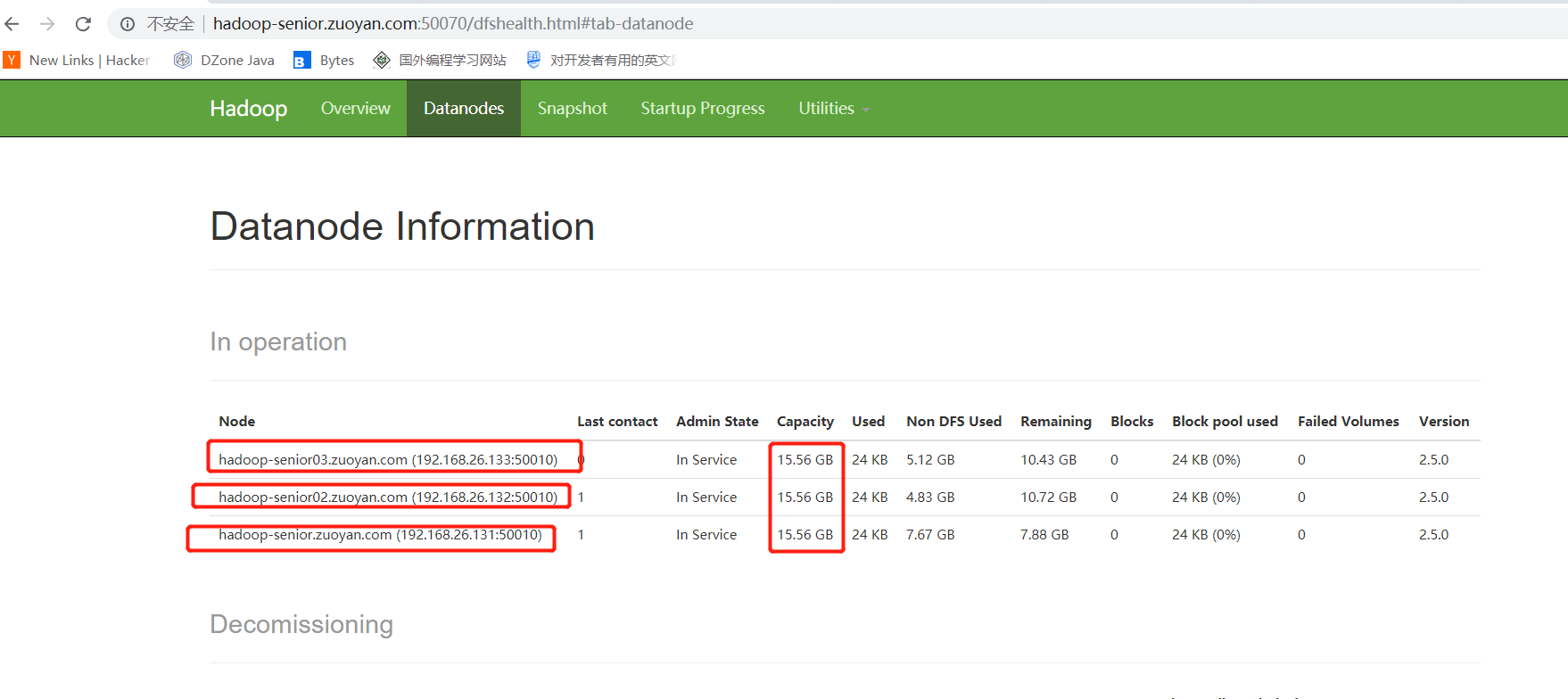
通过浏览器打开查看一下启动情况:
输入网址:http://hadoop-senior.zuoyan.com:50070(这里也就是第一个主机的ip地址,因为我映射到了windows的hosts中,所以也能通过这个主机名访问)
点击主页的 LiveNodes 就可以看见如下的界面
这个界面上显示的就是我们的节点
使用一些命令进行测试一下
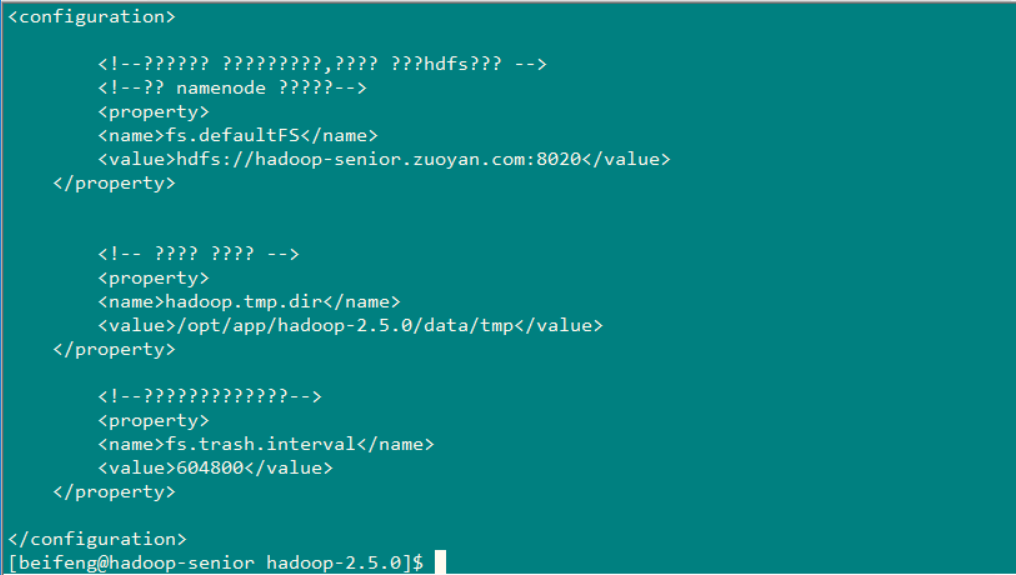
创建目录命令: bin/hdfs dfs -mkdir -p /user/beifeng/tmp/conf

上传文件命令: bin/hdfs dfs -put /etc/hadoop/*.-site.xml /user/beifeng/tmp/conf

读取文件命令: bin/hdfs dfs -text /user/beifeng/tmp/conf/core-site.xml (下图就是成功的读取出来了)
3.启动yarn
(在/opt/app/hadoop-2.5.0 的目录下 ) 使用命令: sbin/start-yarn.sh

在启动yarn的时候我的出先了一个问题 就是resourcemanager 启动不起来 不论是在 第一个节点上看,还是在第二个节点上看 都没有resourcemanager

日志信息如下

最终在开源中国上查找到了解决方案
Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
4.测试Mapreduce程序
首先创建一个目录用来存放输入数据 命令: bin/hdfs dfs -mkdir -p /user/beifeng/mapreduce/wordcount/input

上传文件到文件系统上去 命令:bin/hdfs dfs -put /opt/modules/hadoop-2.5.0/wc.input /user/beifeng/mapreduce/wordcount/input

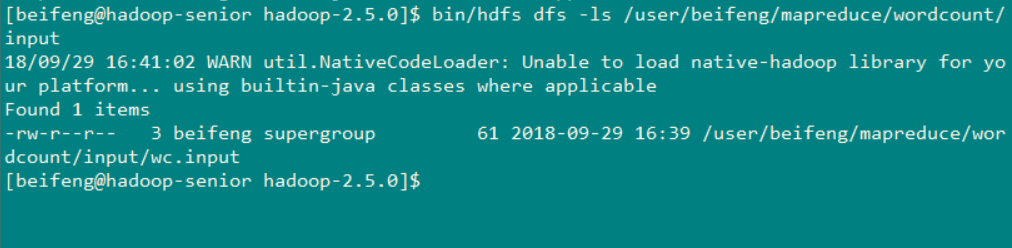
使用命令查看一下文件是否上传成功 命令:bin/hdfs dfs -ls /user/beifeng/mapreduce/wordcount/input (可以看到wc.input 已经在这个目录下)
完成准备工作之后 就开始使用 yarn 来运行wordcount 程序
命令: bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/beifeng/mapreduce/wordcount/input /user/beifeng/mapreduce/wordcount/output
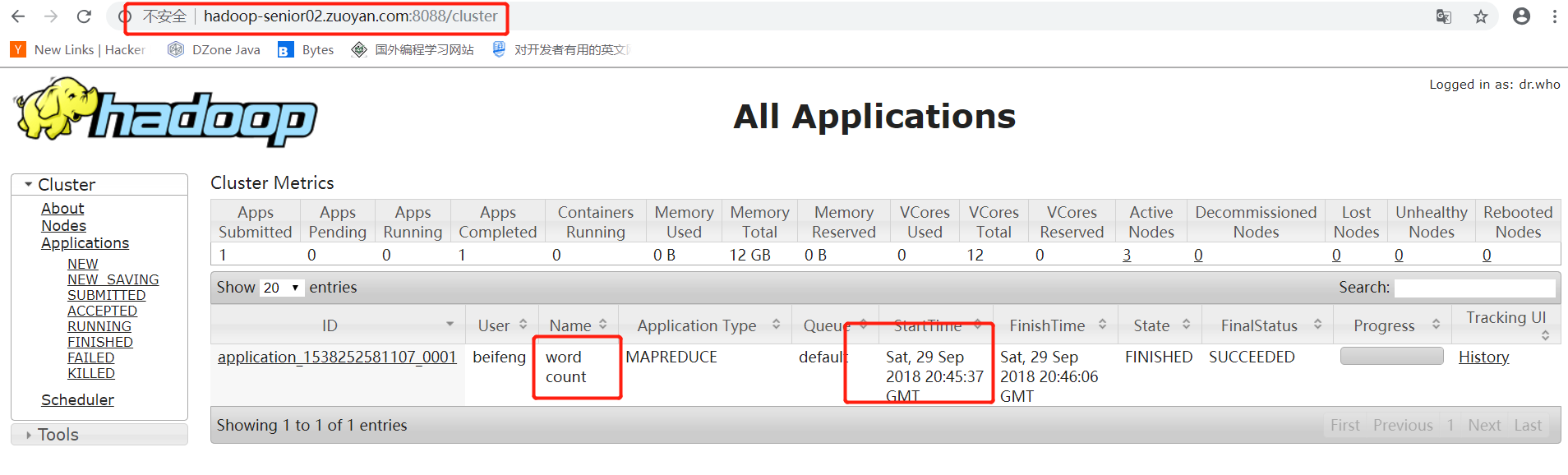
程序已经开始在机器上运行了

从WEB页面上看到的效果
最后在使用hdfs 的命令来查看一下 wordcount 统计的结果 命令 :bin/hdfs -dfs -text /user/beifeng/mapreduce/wordcount/output/part*

到此 配置结束,但是剩下的还有 环境问题解决 和 集群基础测试
【Hadoop 分布式部署 五:分布式部署之分发、基本测试及监控】的更多相关文章
- Hadoop生态圈-zookeeper完全分布式部署
Hadoop生态圈-zookeeper完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客部署是建立在Hadoop高可用基础之上的,关于Hadoop高可用部署请参 ...
- Hadoop 2.6.0分布式部署參考手冊
Hadoop 2.6.0分布式部署參考手冊 关于本參考手冊的word文档.能够到例如以下地址下载:http://download.csdn.net/detail/u012875880/8291493 ...
- Hadoop生态圈-phoenix完全分布式部署以及常用命令介绍
Hadoop生态圈-phoenix完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. phoenix只是一个插件,我们可以用hive给hbase套上一个JDBC壳,但是你 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 3-3 Hadoop集群完全分布式配置部署
Hadoop集群完全分布式配置部署 下面的部署步骤,除非说明是在哪个服务器上操作,否则默认为在所有服务器上都要操作.为了方便,使用root用户. 1.准备工作 1.1 centOS6服务器3台 手动指 ...
- Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署 前言 单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个n ...
- Hadoop安装-单机-伪分布式简单部署配置
最近在搞大数据项目支持所以有时间写下hadoop随笔吧. 环境介绍: Linux: centos7 jdk:java version "1.8.0_181 hadoop:hadoop-3.2 ...
- 一文搞定FastDFS分布式文件系统配置与部署
Ubuntu下FastDFS分布式文件系统配置与部署 白宁超 2017年4月15日09:11:52 摘要: FastDFS是一个开源的轻量级分布式文件系统,功能包括:文件存储.文件同步.文件访问(文件 ...
- 大型Java web项目分布式架构演进-分布式部署
http://blog.csdn.net/binyao02123202/article/details/32340283/ 知乎相关文章https://www.zhihu.com/question/2 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
随机推荐
- FILE文件删除操作(删除指定文件夹下所有文件和文件夹包括子文件夹下所有文件和文件夹),就是删除所有
2018-11-05 19:42:08开始写 选择 删除 1.FileUtils.java类 import java.io.File;//导入包 import java.util.List;//导入 ...
- python 之xml.etree.ElementTree
Element类型是一种灵活的容器对象,用于在内存中存储结构化数据. [注意]xml.etree.ElementTree模块在应对恶意结构数据时显得并不安全. 每个element对象都具有以下属性: ...
- ubuntu_python_environment
参考:http://blog.csdn.net/kingppy/article/details/13080919 参考:http://blog.csdn.net/zhaobig/article/det ...
- Java用Gson按照键值key排序json所有节点
<dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifa ...
- ltp-ddt的makefile结构
顶层makefile COMMON_TARGETS := pan utils COMMON_TARGETS += tools testcases/ddt COMMON_TARGET ...
- EDK II之DXE Core框架简介
本文旨在简单的介绍一下DXE阶段的工作原理: UDK2015的开源代码下载:https://github.com/tianocore/tianocore.github.io/wiki/EDK-II D ...
- SpringMVC学习笔记1
1:IntelliJ新建Maven工程 2:pom.xml文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmln ...
- 标准库 time
go语言的time包 1. 组成 time.Duration(时长,耗时) time.Time(时间点)time.C(放时间点的管道)[ Time.C:=make(chan time.Time) ]t ...
- springboot 项目pom.xml文件基本配置
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven ...
- linux下网卡bonding配置(转)
linux下网卡bonding配置 章节 bonding技术 centos7配置bonding centos6配置bonding 一.bonding技术 bonding(绑定)是一种linux系统 ...