[离线计算-Spark|Hive] 数据近实时同步数仓方案设计
背景
最近阅读了大量关于hudi相关文章, 下面结合对Hudi的调研, 设计一套技术方案用于支持 MySQL数据CDC同步至数仓中,避免繁琐的ETL流程,借助Hudi的upsert, delete 能力,来缩短数据的交付时间.
组件版本:
- Hadoop 2.6.0
- Hive 1.1.0
- hudi 0.7.0
- spark 2.4.6
架构设计
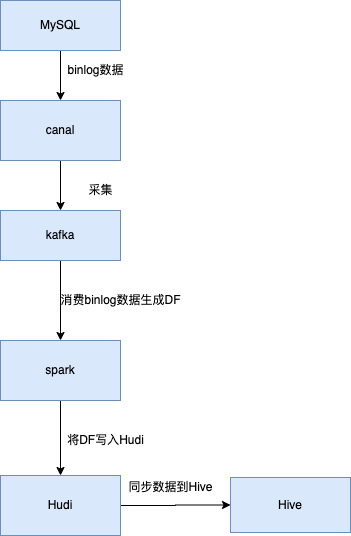
- 使用canal(阿里巴巴MySQL Binlog增量订阅&消费组件)dump mysql binlog 数据
- 采集后将binlog 数据采集到kafka中, 按照库名创建topic, 并按照表名将数据写入topic 固定分区
- spark 消费数据将数据生成DF
- 将DF数据写入hudi表
- 同步hudi元数据到hive中
写入主要分成两部分全量数据和增量数据:
历史数据通过bulkinsert 方式 同步写入hudi
增量数据直接消费写入使用hudi的upsert能力,完成数据合并
写入hudi在hdfs的格式如下:
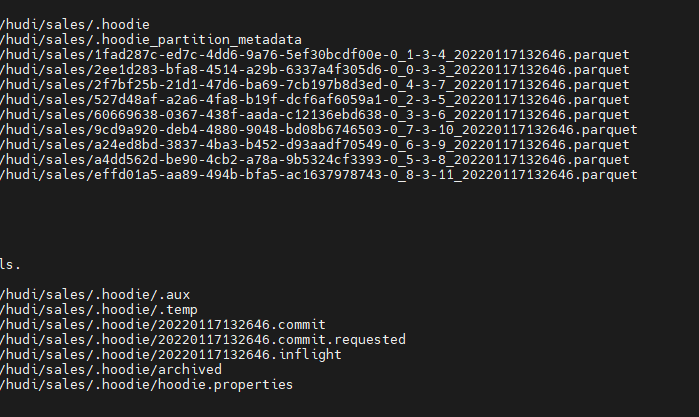
hudi
hudi 如何处理binlog upsert,delete 事件进行数据的合并?
upsert好理解, 依赖本身的能力.
针对mysql binlog的delete 事件,使用记录级别删除:
需要在数据中添加 '_HOODIE_IS_DELETED' 且值为true的列
需要在dataFrame中添加此列,如果此值为false或者不存在则当作常规写入记录
如果此值为true则为删除记录
示例代码如下:
StructField(_HOODIE_IS_DELETED, DataTypes.BooleanType, true, Metadata.empty());
dataFrame.write.format("org.apache.hudi")
.option("hoodie.table.name", "test123")
.option("hoodie.datasource.write.operation", "upsert")
.option("hoodie.datasource.write.recordkey.field", "uuid")
.option("hoodie.datasource.write.partitionpath.field", "partitionpath")
.option("hoodie.datasource.write.storage.type", "COPY_ON_WRITE")
.option("hoodie.datasource.write.precombine.field", "ts")
.mode(Append)
.save(basePath)
写入hudi及同步数据至hive,需要注意的事情和如何处理?
声明为hudi表的path路径, 非分区表 使用tablename/, 分区表根据分区路径层次定义/个数
在创建表时需添加 TBLPROPERTIES 'spark.sql.sources.provider'='hudi' 声明为datasource为hudi类型的表
hudi如何处理新增字段?
当使用Spark查询Hudi数据集时,当数据的schema新增时,会获取单个分区的parquet文件来推导出schema,若变更schema后未更新该分区数据,那么新增的列是不会显示,否则会显示该新增的列;若未更新该分区的记录时,那么新增的列也不会显示,可通过 mergeSchema来控制合并不同分区下parquet文件的schema,从而可达到显示新增列的目的
hudi 写入时指定mergeSchema参数 为true
spark如何实现hudi表数据的写入和读取?
Spark支持用户自定义的format来读取或写入文件,只需要实现对应的(RelationProvider、SchemaRelationProvider)等接口即可。而Hudi也自定义实现了 org.apache.hudi/ hudi来实现Spark对Hudi数据集的读写,Hudi中最重要的一个相关类为 DefaultSource,其实现了 CreatableRelationProvider#createRelation接口,并实现了读写逻辑
kyuubi
如何读取hudi表数据?
使用网易开源的kyuubi
kyuubi架构图:
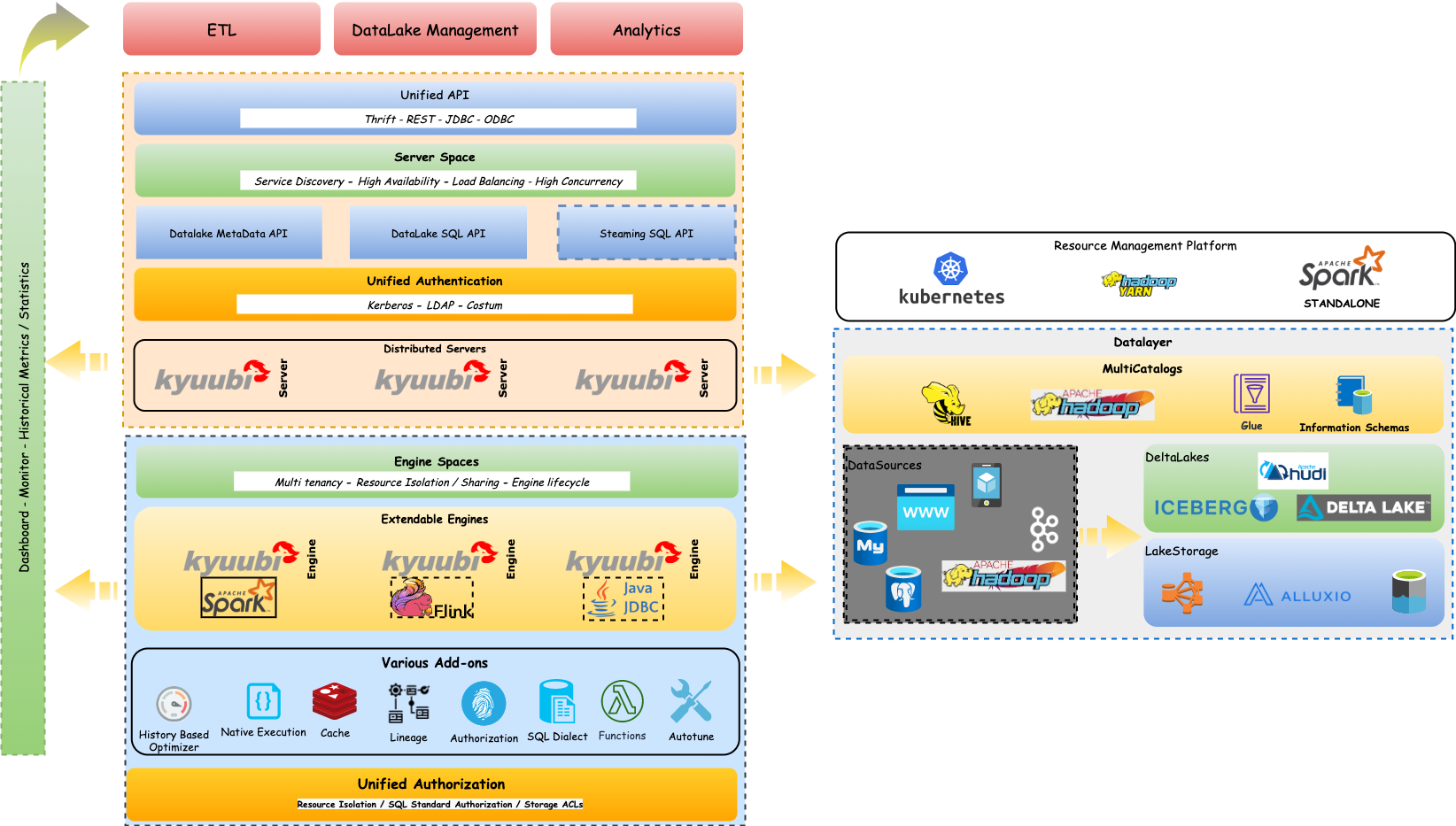
支持HiveServer2 Thrift API协议,可以通过beeline 连接
hive: beeline -u jdbc:hive2://ip:10000 -n userName -p
kyuubi: beeline -u jdbc:hive2://ip:8333 -n userName -p
hudi 元数据使用hive metastore
spark来识别加载hudi表
实现hudi表与hive表关联查询
kyuubi 支持SparkContext的动态缓存,让用户不需要每次查询都动态创建SparkContext。作为一个应用在yarn 上一直运行,终止beeline 连接后,应用仍在运行,下次登录,使用SQL可以直接查询
总结
本文主要针对hudi进行调研, 设计MySQL CDC 近实时同步至数仓中方案, 写入主要利用hudi的upsert以及delete能力. 针对hudi 表的查询,引入kyuubi 框架,除 了增强平台 spark sql作为即席查询服务的能力外,同时支持查询hudi表,并可以实现hudi表与hive表的联合查询, 同时对原有hive相关服务没有太大影响.
参考
- https://blog.csdn.net/weixin_38166318/article/details/111825032
- https://blog.csdn.net/qq_37933018/article/details/120864648
- https://cxymm.net/article/qq_37933018/120864648
- https://www.jianshu.com/p/a271524adcc3
- https://jishuin.proginn.com/p/763bfbd65b70
[离线计算-Spark|Hive] 数据近实时同步数仓方案设计的更多相关文章
- 大数据分析处理框架——离线分析(hive,pig,spark)、近似实时分析(Impala)和实时分析(storm、spark streaming)
大数据分析处理架构图 数据源: 除该种方法之外,还可以分为离线数据.近似实时数据和实时数据.按照图中的分类其实就是说明了数据存储的结构,而特别要说的是流数据,它的核心就是数据的连续性和快速分析性: 计 ...
- 性能优化之永恒之道(实时sql优化vs业务字段冗余vs离线计算)
在项目中,随着时间的推移,数据量越来越大,程序的某些功能性能也可能会随之下降,那么此时我们不得不需要对之前的功能进行性能优化.如果优化方案不得当,或者说不优雅,那可能将对整个系统产生不可逆的严重影响. ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
一.概述 根据之前的凡技术必登其官网的原则,我们当然先得找到它的官网:http://hadoop.apache.org/ 1.什么是hadoop 先看官网介绍: The Apache™ Hadoop® ...
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- Spark大数据针对性问题。
1.海量日志数据,提取出某日访问百度次数最多的那个IP. 解决方案:首先是将这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中.注意到IP是32位的,最多有个2^32个IP.同样可以采 ...
- 剖析Elasticsearch集群系列之三:近实时搜索、深层分页问题和搜索相关性权衡之道
转载:http://www.infoq.com/cn/articles/anatomy-of-an-elasticsearch-cluster-part03 近实时搜索 虽然Elasticsearch ...
- 大数据-06-Spark之读写Hive数据
简介 Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据.Hive本身不存储数据,它完全依赖HDFS和MapReduce.这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询 ...
- 通过Flink实现个推海量消息数据的实时统计
背景 消息报表主要用于统计消息任务的下发情况.比如,单条推送消息下发APP用户总量有多少,成功推送到手机的数量有多少,又有多少APP用户点击了弹窗通知并打开APP等.通过消息报表,我们可以很直观地看到 ...
- 教你如何成为Spark大数据高手?
教你如何成为Spark大数据高手? Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么如何成为Spark大数据高手?下面就来个深度教程. Spark ...
随机推荐
- 瑞芯微rk356x板子快速上手
@ 目录 rk3568 CPU GPU NPU VPU 一.编译环境要求 二.编译前准备 0)开发板型号 1)安装第三方编译工具 2)设置adb路径 3)安装USB驱动DriverAssitant_v ...
- 使用CyFES对配体运动轨迹进行数据透视
技术背景 如果我们有一个蛋白质X和一个配体Y,那么可以对这个X+Y的体系跑一段长时间的分子动力学模拟,以观测这个体系在不同结合位点下的稳定性.类似于前面一篇博客中计算等高面的方法,我们可以计算轨迹的K ...
- MFC连接Access2007数据库
// TODO: 在此添加额外的初始化代码 //初始化ADO环境 if (!AfxOleInit()) { AfxMessageBox(L"OLE初始化失败"); return F ...
- 树莓派CM4(四):树莓派镜像替换内核
树莓派镜像替换内核 1. 为什么要替换内核 树莓派官方提供的镜像中,自带的内核版本为6.6.31 然而github上提供的内核源码为6.6.40,有些微差别 此外,后续很有可能进行内核裁剪定制等工作, ...
- Seata 1.3.0 Oracle 回滚测试验证 报错 ORA-02289: 序列不存在
使用Seata 1.3.0版本,测试A服务调用B服务,且A方法中,手动写了一个异常,测试是否正常回滚(Mysql已经测试过) 发现报错:ORA-02289: 序列不存在 一看就是undo_log这张表 ...
- 15. 三数之和 Golang实现
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j.i != k 且 j != k ,同时还满足 nums[i] + nums ...
- Angular Material 18+ 高级教程 – CDK Drag and Drop
前言 CDK Drag and Drop 和 CDK Scrolling 都是在 Angular Material v7 中推出的. 它们有一个巧妙的共同点,那就是与 Material Design ...
- Windbg常用命令及分析套路
自己也在使用windbg分析问题,但是属于刚入门所以转发下大神的总结:https://www.cnblogs.com/fj365/p/13295453.html 常用 !threadpool 查看线程 ...
- Go runtime 调度器精讲(十一):总览全局
原创文章,欢迎转载,转载请注明出处,谢谢. 0. 前言 前面用了十讲介绍了 Go runtime 调度器,这一讲结合一些图在总览下 Go runtime 调度器. 1. 状态转换图 首先是 Gorou ...
- [Tkey] OSU!
更新的题解可看 此处 你说得对但是 恐怖日本病毒会自动向你的电脑中下载 OSU! 题意简述 一个 01 串,每个位置有 \(p_{i}\) 的概率为 \(1\),连续的 \(x\) 个 \(1\) 贡 ...