python测试开发django-23.admin列表页优化和排序
前言
列表页优化和排序
ModelAdmin
django的options.py里面 ModelAdmin类定义的参数可以设置admin后台列表页面,相关的参数如下
class ModelAdmin(BaseModelAdmin):
"""Encapsulate all admin options and functionality for a given model."""
list_display = ('__str__',) # 显示的字段
list_display_links = () # 可点击的链接字段
list_filter = () # 过滤器
list_select_related = False
list_per_page = 100 # 每页显示100条
list_max_show_all = 200
list_editable = () # 列表页 可编辑字段
search_fields = () # 搜索条件
date_hierarchy = None # 按时间分层
save_as = False
save_as_continue = True
save_on_top = False
paginator = Paginator
preserve_filters = True
inlines = []
排序字段
后台列表页面,如果想按某个字段排序,可以加个ordering参数,比如按创建时间(creat_time)降序
备注:ordering参数在BaseModelAdmin类里面,不在ModelAdmin类,ModelAdmin继承了BaseModelAdmin
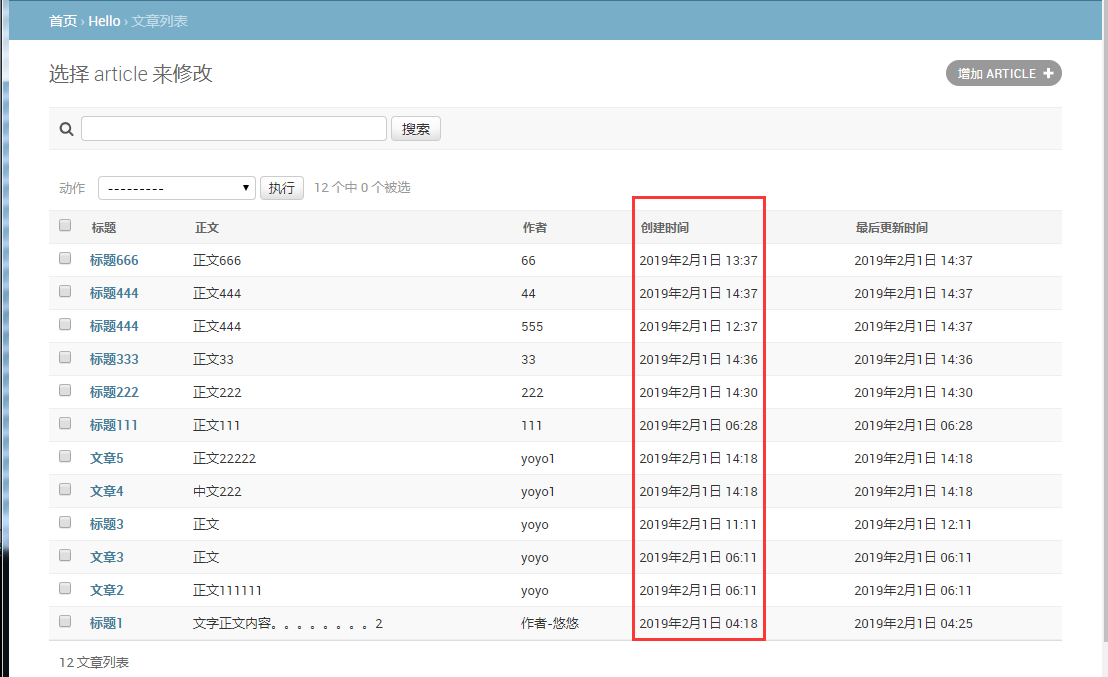
修改admin.py文件内容,加个ordering参数,create_time字段前面的-表示按降序
class ControlArticle(admin.ModelAdmin):
# 显示的字段
list_display = ('title', 'body', 'auth', 'create_time', 'update_time')
# 搜索条件
search_fields = ('title',)
# 按字段排序 -表示降序
ordering = ('-create_time',)
# 注册Article表
admin.site.register(models.Article, ControlArticle)
刷新页面后,就是按时间降序了
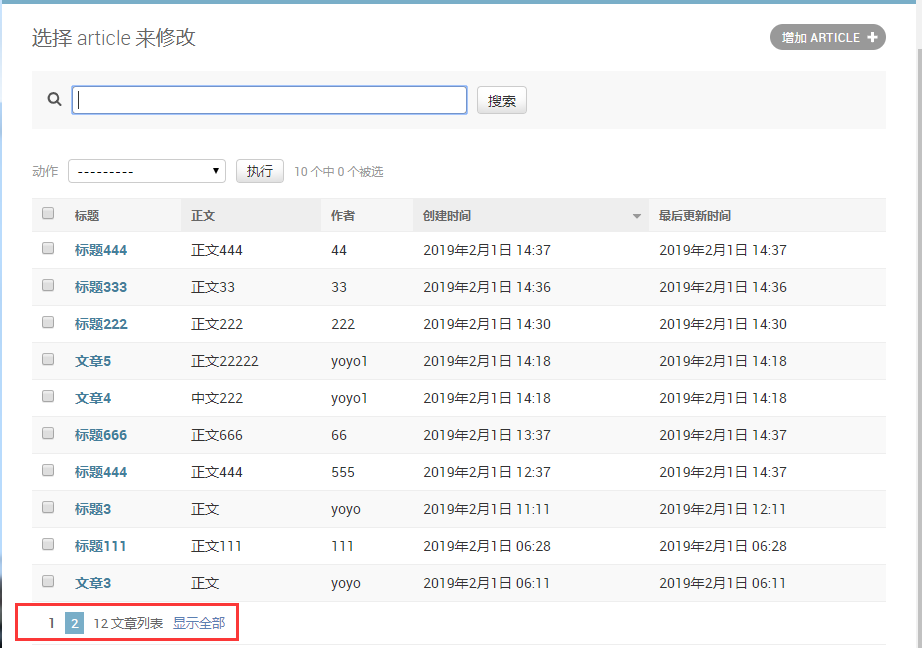
列表分页
列表页默认是设置的100个记录,我们也可以修改下设置成默认每页显示10个,设置list_per_page = 10
class ControlArticle(admin.ModelAdmin):
# 显示的字段
list_display = ('title', 'body', 'auth', 'create_time', 'update_time')
# 搜索条件
search_fields = ('title',)
# 按字段排序 -表示降序
ordering = ('-create_time',)
# 每页显示10条
list_per_page = 10
# 注册Article表
admin.site.register(models.Article, ControlArticle)
设置默认可编辑字段
有些字段如果想在列表页就能直接编辑,可以加个list_editable参数,这样无需进子页面,可以直接编辑列表页上的字段
如果有多个参数设置,元组里面逗号隔开就行,如 list_editable = ('body', 'auth', )
class ControlArticle(admin.ModelAdmin):
# 显示的字段
list_display = ('title', 'body', 'auth', 'create_time', 'update_time')
# 搜索条件
search_fields = ('title',)
# 按字段排序 -表示降序
ordering = ('-create_time',)
# 每页显示10条
list_per_page = 10
# 可编辑字段
list_editable = ('auth',)
# 注册Article表
admin.site.register(models.Article, ControlArticle)
注意:title是默认的link链接字段,这个不能添加到 list_editable里面,否则会报错
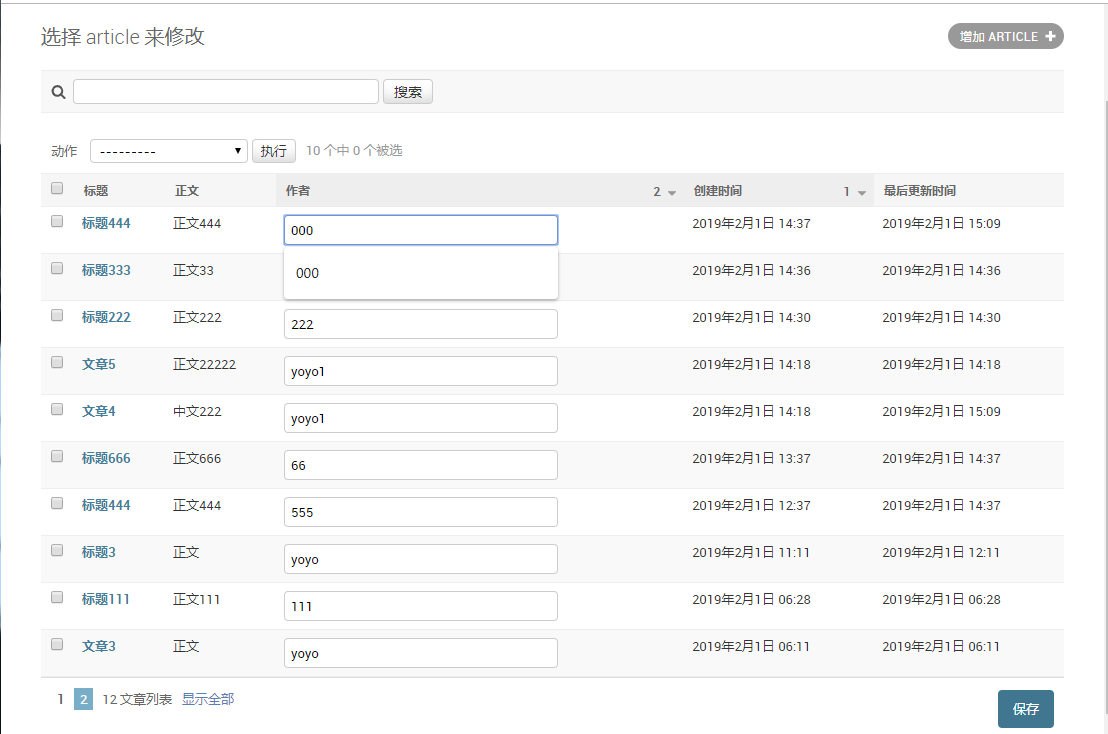
编辑完之后点右下角的保存即可, 这个功能用处不大,了解下即可
link链接
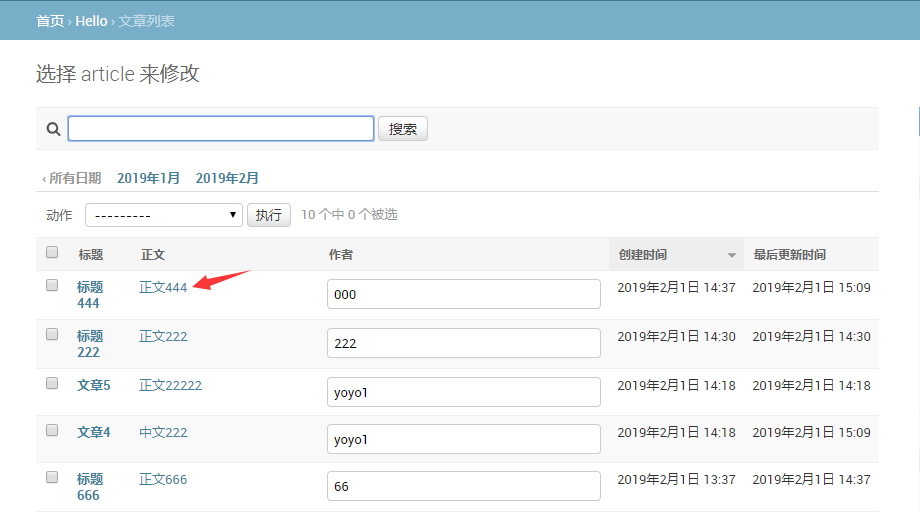
列表页默认点第一个字段可进入编辑页面,如果我们想增加其它的字段也能点击进编辑页面,设置list_display_links = ('title', 'body')
class ControlArticle(admin.ModelAdmin):
# 显示的字段
list_display = ('title', 'body', 'auth', 'create_time', 'update_time')
# 搜索条件
search_fields = ('title',)
# 按字段排序 -表示降序
ordering = ('-create_time',)
# 每页显示10条
list_per_page = 10
# 可编辑字段
list_editable = ('auth',)
# 设置哪些字段可以点击进入编辑界面
list_display_links = ('title', 'body')
# 注册Article表
admin.site.register(models.Article, ControlArticle)
这样点标题和正文都能进编辑页面了
过滤器
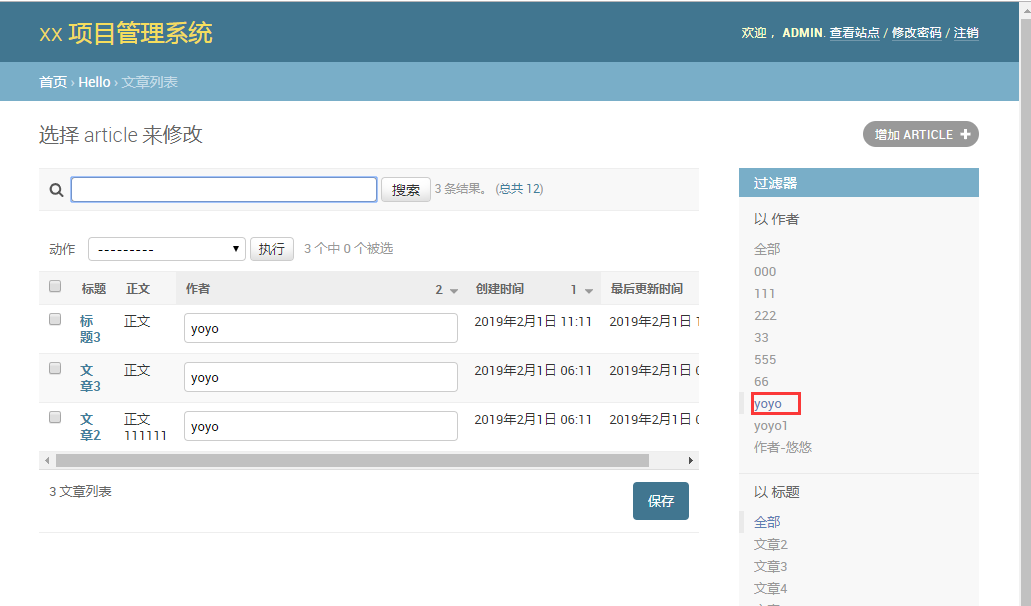
如果想快速方便找到作者对应的文字,可以添加过滤器,显示到列表页面右边,如设置list_filter = ('auth', 'title')
class ControlArticle(admin.ModelAdmin):
# 显示的字段
list_display = ('title', 'body', 'auth', 'create_time', 'update_time')
# 搜索条件
search_fields = ('title',)
# 按字段排序 -表示降序
ordering = ('-create_time',)
# 每页显示10条
list_per_page = 10
# 可编辑字段
list_editable = ('auth',)
# 设置哪些字段可以点击进入编辑界面
list_display_links = ('title', 'body')
# 过滤器
list_filter = ('auth', 'title')
# 注册Article表
admin.site.register(models.Article, ControlArticle)
显示效果如下,点右侧作者名称,快速找到相关内容
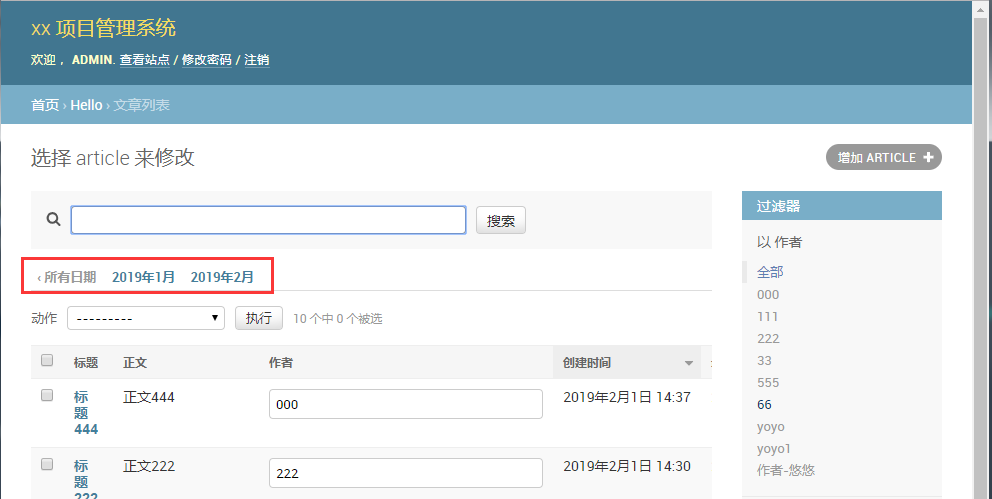
按时间分层
date_hierarchy参数默认为None,设置一个时间字段,可以按时间分层删选
class ControlArticle(admin.ModelAdmin):
# 显示的字段
list_display = ('title', 'body', 'auth', 'create_time', 'update_time')
# 搜索条件
search_fields = ('title',)
# 按字段排序 -表示降序
ordering = ('-create_time',)
# 每页显示10条
list_per_page = 10
# 可编辑字段
list_editable = ('auth',)
# 设置哪些字段可以点击进入编辑界面
list_display_links = ('title', 'body')
# 过滤器
list_filter = ('auth', 'title')
# 时间分层
date_hierarchy = 'create_time'
# 注册Article表
admin.site.register(models.Article, ControlArticle)
python测试开发django-23.admin列表页优化和排序的更多相关文章
- python测试开发django-36.一对一(OneToOneField)关系查询
前言 前面一篇在xadmin后台一个页面显示2个关联表(OneToOneField)的字段,使用inlines内联显示.本篇继续学习一对一(OneToOneField)关系的查询. 上一篇list_d ...
- python测试开发django-rest-framework-63.基于函数的视图(@api_view())
前言 上一篇讲了基于类的视图,在REST framework中,你也可以使用常规的基于函数的视图.它提供了一组简单的装饰器,用来包装你的视图函数, 以确保视图函数会收到Request(而不是Djang ...
- python测试开发django-197.django-celery-beat 定时任务
前言 django-celery-beat 可以支持定时任务,把定时任务写到数据库. 接着前面这篇写python测试开发django-196.python3.8+django2+celery5.2.7 ...
- python测试开发django-16.JsonResponse返回中文编码问题
前言 django查询到的结果,用JsonResponse返回在页面上显示类似于\u4e2d\u6587 ,注意这个不叫乱码,这个是unicode编码,python3默认返回的编码 遇到问题 接着前面 ...
- python测试开发django-15.查询结果转json(serializers)
前言 django查询数据库返回的是可迭代的queryset序列,如果不太习惯这种数据的话,可以用serializers方法转成json数据,更直观 返回json数据,需要用到JsonResponse ...
- 2019第一期《python测试开发》课程,10月13号开学
2019第一期<python测试开发>课程,10月13号开学! 主讲老师:上海-悠悠 上课方式:QQ群视频在线教学,方便交流 本期上课时间:10月13号-12月8号,每周六.周日晚上20: ...
- Python测试开发-创建模态框及保存数据
Python测试开发-创建模态框及保存数据 原创: fin 测试开发社区 前天 什么是模态框? 模态框是指的在覆盖在父窗体上的子窗体.可用来做交互,我们经常会看到模态框用来登录.确定等等,到底是怎 ...
- Python测试开发-浅谈如何自动化生成测试脚本
Python测试开发-浅谈如何自动化生成测试脚本 原创: fin 测试开发社区 前天 阅读文本大概需要 6.66 分钟. 一 .接口列表展示,并选择 在右边,点击选择要关联的接口,区分是否要登录, ...
- 《Python测试开发技术栈—巴哥职场进化记》—前言
写在前面 今年从4月份开始写一本讲Python测试开发技术栈的书,主要有两个目的,第一是将自己掌握的一些内容分享给大家,第二是希望自己能系统的梳理和学习Python相关的技术栈.当时我本来打算以故事体 ...
随机推荐
- Java基础87 MySQL数据约束
1.默认值 -- 创建表student1,设置address字段有默认值 create table student1 ( id int, name ), address ) default '广东省深 ...
- java 嵌套接口
接口可以嵌套在其它类或接口中,可以拥有public和"包访问权限"两种可见性 作为一种新添加的方式,接口也可以实现为private 当实现某个接口时,并不需要实现嵌套在其内的任何接 ...
- 利用openssl构建根证书-服务器证书-客户证书
利用openssl构建根证书-服务器证书-客户证书 OpenSSL功能远胜于KeyTool,可用于根证书,服务器证书和客户证书的管理 一.构建根证书 1.构建根证书前,需要构建随机数文件(.rand) ...
- JS实现音乐播放器
JS实现音乐播放器 前 言 最近在复习JS,觉得音乐播放器是个挺有意思的东西,今天就来用我们最原生的JS写一个小小的音乐播放器~ 主要功能: 1.支持循环.随机播放 2.在播 ...
- 如何快速切换Python运行版本,如何选择Python版本
想必在学习Python时会面临选择Python2.X或者是Python3.X的问题. 我在电脑上不同位置下载安装了不同版本 的Python,当我在学习时,不管是需要哪一个版本才能运行都无所谓,相应的快 ...
- Ubuntu服务器的anaconda环境修复办法(自动进入base环境怎么办?)
某天在服务器上更新了conda的版本,不知怎么回事我的python3.6就变成python2.7了,而且一进入服务器就会自动进入base环境(我的conda只装了base环境) 仔细研究了半天,才发现 ...
- 23.python中的类属性和实例属性
在上篇的时候,我们知道了:属性就是属于一个对象的数据或者函数,我们可以通过句点(.)来访问属性,同时 python 还支持在运作中添加和修改属性. 而数据变量,类似于: name = 'scolia' ...
- zookeeper 节点启动时的更新机制
使用zk的应用节点和zk数据本身的同步,当系统启动时使用zk配置的信息和zk本身存储不一致, 此时应存在一个更新机制将应用配置数据和zk数据更新一致. 启动时更新拉取zk配置中心的更新本地数据,以zk ...
- eclipse闪退解决(转)
最近帮同事解决一个eclipse闪退解决的问题,从网上找了N多方法皆无效,最后用一个园友的博客上的方法解决了,特转载一下. 解决办法: 删除文件 [workspace]/.metadata/.plug ...
- BZOJ4175 : 小G的电话本
用后缀树统计出出现了x次的本质不同的子串的个数,最后再乘以x,得到一个多项式. 这个多项式常数项为0,但是一次项不为0. 于是把整个多项式除以一次项,通过多项式求ln和多项式求exp求出它的幂. 最后 ...