spark核心原理
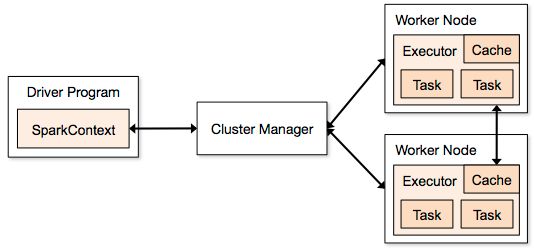
spark运行结构图如下:
spark基本概念
应用程序(application):用户编写的spark应用程序,包含驱动程序(Driver)和分布在集群中多个节点上运行的Executor代码,在执行过程中由一个或者多个作业组成。
驱动程序(dirver):spark中Driver即运行上述Application的main函数并且创建sparkContext,其中sparkcontext的目的是为了准备spark应用程序的运行环境。在 spark中由sparkcontext负责与cluster manager通信,进行资源的申请,任务的分配和监控等,当executor部分运行完毕后,driver负责将sparkcontext关闭。通常sparkcontext代表dirver。
集群管理器(cluster manager):指在集群中获取资源的外部服务器。目前有一下几种①standalone:spark原生的资源管理,由master负责资源管理。②hadoop yarn:由yarn中的ResourceManager负责资源管理。③mesos:由mesos中的mesos master负责资源的管理。
工作节点(worker):集群中运行application代码的节点,类似于yarn中的nodemanager节点,standalone模式中就是通过slave文件配置的worker节点,spark on yarn模式中指的是nodemanager节点
master(总控程序):spark standalone运行模式下的主节点,负责管理和分配集群资源来管理spark application
executor(执行程序): application运行在worker节点上的一个进程,改进程负责运行task,并负责将数据存在内存或者磁盘上,每个application都有各自独立的一批executor。在spark on yarn模式下,进程名为CoarseGrainedExecutorBackend进程。一个CoarseGrainedExecutorBackend有且只有一个executor对象,他负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行的Task数据取决于分配给它的CPU个数。
消息通信原理:暂未研究
作业执行原理
spark的作业和任务调度系统是其核心,它能够有效地进行调度的根本原因是对任务划分DAG和容错,使得它对底层到顶层各个模块之间的调用和处理显得游刃有余。
相关术语如下:
作业(job):RDD中由行动操作所生成的一个或者多个调度阶段
调度阶段(Stage):每个作业会因为RDD之间的依赖关系拆分成多组任务的组合,称为调度阶段,也叫作任务集(taskset)。调度阶段的划分是由DAGScheduler来划分的,调度阶段有shuffle map stage和result stage两种。
任务(task):分发到excutor上工作的任务,是spark实际执行应用的最小单元。
DAGScheduler:DAGScheduler是面向调度阶段的任务调度器,负责接收spark提交的作业,根据RDD的依赖关系划分调度阶段,并提交调度阶段给TaskScheduler。
TaskScheduler:TaskScheduler是面向任务的调度器,它接收DAGScheduler提交的调度阶段,然后把任务分发给Worker节点运行,由Woker节点的Executor来运行任务。
spark的作业调度主要指基于RDD的一系列操作构成的一个作业,然后在Executor中执行。这些操作算子分为转换操作和行动操作,对于转换操作的计算是lazy级别的,也就是延迟执行,只有出现了行动操作才会触发作业的提交。在spark调度中最重要的是DAGScheduler和TaskScheduler两个调度器,其中DAGScheduler负责任务的逻辑调度,将作业拆分成不同阶段的具有依赖关系的任务集。而TaskScheduler则负责具体任务的调度执行。
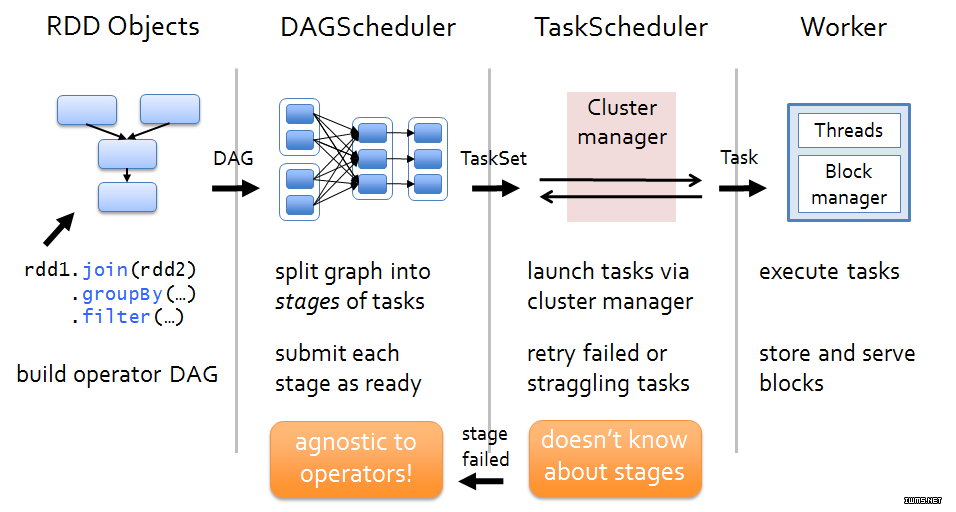
spark的作业和任务调度系统如下图所示:
 via:通过.经过;launch:开展,发射,着手进行,投掷,发动
via:通过.经过;launch:开展,发射,着手进行,投掷,发动
上图分析如下:
(1).spark引用程序进行各种转换,通过行动操作触发作业运行。提交之后根据RDD之间的依赖关系构建DAG图,DAG图交给DAGScheduler进行解析。
(2).DAGScheduler是面向调度阶段的高层次调度器,DAGScheduler把DAG拆分成相互依赖的调度阶段,拆分调度阶段以RDD的依赖是否为宽依赖,当遇到宽依赖就划分为新的调度阶段。每个调度阶段包含一个或者多个任务,这些任务形成任务集提交给底层调度器TaskScheduler进行调度运行。另外,DAGScheduler记录哪些RDD被存入磁盘等物化动作,同时要需求任务的最优化调度,例如数据本地性等;DAGScheduler监控运行调度阶段过程,如果某个调度阶段运行失败,则需要重新提交调度阶段。
(3).每TaskScheduler只为一个SparkContext实例服务,TaskScheduler接受来自DAGScheduler发送过来的任务集,TaskScheduler收到任务集后负责把任务集以任务的形势一个个发到集群Worker节点的Executor中运行,如果某个任务失败,TaskScheduler要负责重试,另外如果TaskScheduler发现某个任务一直未运行完,则可能启动同样的任务运行同一个任务,哪个任务先运行完就用哪个任务的结果。
(4).Woker中的Executor收到TaskScheduler发送过来的任务后,以多线程的方式运行,每个线程负责一个任务。任务运行结束后要返回给TaskScheduler,不同类型的任务,返回的方式也不同。ShuffleMapTask返回的是一个MapStatus对象,而不是结果本事;ResultTask根据结果大小的不同,返回的方式分为:
①生成的结果大小为(∞,1G):结果会被丢弃,该配置项可以通过spark.driver.maxResultSize进行设置:
scala> import org.apache.spark.SparkConf
import org.apache.spark.SparkConf
scala> val conf=new SparkConf()
conf: org.apache.spark.SparkConf = org.apache.spark.SparkConf@6724bdec
scala> conf.set("spark.driver.maxResultSize", "4g")
res89: org.apache.spark.SparkConf = org.apache.spark.SparkConf@6724bdec
scala> conf.getAll
res104: Array[(String, String)] = Array((spark.app.name,Spark shell), (spark.jars,""), (spark.master,local[*]), (spark.submit.deployMode,client), (spark.driver.maxResultSize,4g))
----------------------------
scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession
scala> val session=SparkSession.builder().getOrCreate()
session: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@7952e1d0
scala> session.conf.set("spark.driver.maxResultSize", "6g")
scala> session.conf.getAll
res110: Map[String,String] = Map(spark.sql.warehouse.dir -> /user/hive/warehouse, spark.driver.host -> 192.168.53.122, spark.driver.maxResultSize -> 6g, spark.driver.port -> 40647, spark.repl.class.uri -> spark://192.168.53.122:40647/classes, spark.jars -> "", spark.repl.class.outputDir -> /tmp/spark-07bcb5fa-da26-43c6-a36c-429e45b7b76d/repl-e41427c6-c47a-463f-9382-078e77a97517, spark.app.name -> Spark shell, spark.executor.id -> driver, spark.submit.deployMode -> client, spark.master -> local[*], spark.home -> /root/spark/spark-2.2.0-bin-hadoop2.7, spark.sql.catalogImplementation -> hive, spark.app.id -> local-1534214213827)
两个设置相互不影响
②生成结果大小在[1G,128m-200KB]:如果生成结果的大小等于(128M-200KB),会把结果以taskid的编号存入到blockmanager中,然后把该编号通过Netty发送给driver终端点,该阈值是Netty框架数据的最大值spark.akka.framesize(默认128M)和Netty的预留空间reserveredSizeBytes(200kb)的差值
③结果大小在(128MB-200K,0):通过Netty直接发送到driver终端点
在spark应用程序中,会拆分多个作业,然后对于多个作业之间的调度,spark目前提供了两种调度策略:一种是FIFO(即先来先得first in first out),这是目前的默认模式,另一种是FAIR模式。
FIFO调度策略中,由于调度池 rootpool直接包含了多个作业的任务管理器,在比较时,首先比较作业的优先级(根据作业编号,编号越小优先级越高),如果是同一个作业,会再比较调度阶段的优先级(根据调度阶段的编号,调度阶段的编号越小优先级越高)。
FAIR调度策略中包含了两层调度,第一层根据调度池rootpool中博涵了夏季的下级调度吃pool,第二层为下级调度池pool包含多个tasksetmanager。具体配置参见spark conf目录的fairscheduler.xml,其中minshare最小任务数和weight任务的权重两个参数用来设置第一级调度的算法,schedulingmode参数用来设置第二层调度算法,配置文件如下:
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations>
在fair算法中,先获取两个调度的饥饿程度,饥饿程度为正在运行的任务是否小余最小的任务,如果是,则表示该调度处于饥饿程度。获取借程度后进行如下比较:
如果某个调度处于饥饿状态量另外一个非饥饿状态,则先满足饥饿状态的调度;
如果两个调度都处于饥饿状态,则计较资源,先满足资源比小的调度;
如果两个调度都处于非饥饿状态,则比较权重比,先满足权重比小的调度;
以上情况均相同的情况下,根据调度的名称排序
spark核心原理的更多相关文章
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- Spark核心原理初探
一.运行架构概览 Spark架构是主从模型,分为两层,一层管理集群资源,另一层管理具体的作业,两层是解耦的.第一层可以使用yarn等实现. Master是管理者进程,Worker是被管理者进程,每个W ...
- Spark核心技术原理透视一(Spark运行原理)
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位. Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势.无论是性能,还是方案的统一 ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- Spark 核心篇-SparkContext
本章内容: 1.功能描述 本篇文章就要根据源码分析SparkContext所做的一些事情,用过Spark的开发者都知道SparkContext是编写Spark程序用到的第一个类,足以说明SparkCo ...
- Spark 核心篇-SparkEnv
本章内容: 1.功能概述 SparkEnv是Spark的执行环境对象,其中包括与众多Executor执行相关的对象.Spark 对任务的计算都依托于 Executor 的能力,所有的 Executor ...
- Spark Shuffle原理解析
Spark Shuffle原理解析 一:到底什么是Shuffle? Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算. 二: ...
随机推荐
- Azure SQL 数据库仓库Data Warehouse (3) DWU
<Windows Azure Platform 系列文章目录> 在笔者的上一篇文章中:Azure SQL 数据库仓库Data Warehouse (2) 架构 介绍了SQL DW的工作节点 ...
- 【nginx】之常用命令
查看版本号: nginx -s reload :修改配置后重新加载生效 nginx -s reopen :重新打开日志文件nginx -t -c /path/to/nginx.conf 测试ngi ...
- 【AMQ】之安装,启动,访问
1.访问官网下载AMQ 2.解压下载包 windows直接找到系统对应的win32|win64 双击activemq.bat 即可 linux执行 ./activemq start 访问: AMQ默认 ...
- 【Mysql】mysql使用触发器创建hash索引
概述 若设计的数据表中,包含较长的字段,比如URL(通常都会比较长),查询时需要根据该字段进行过滤: select * from table_xxx where url = 'xxxxxxx'; 为了 ...
- sklearn.cross_validation 0.18版本废弃警告及解决方法
转载:cheneyshark 机器环境: scikit-learn==0.19.1 Python 2.7.13 train_test_split基本用法 在机器学习中,我们通常将原始数据按照比例分割为 ...
- uoj#272. 【清华集训2016】石家庄的工人阶级队伍比较坚强
http://uoj.ac/problem/272 这题的式子形式是异或卷积的三进制推广,因此可以设计一个类似fwt的变换,这里需要一个三次单位根$w$,满足$w^3\%p==1$且$(1+w+w^2 ...
- Hadoop单机模式的配置与安装
Hadoop单机模式的配置与安装 单机hadoop集群正常启动后进程情况 ResourceManager NodeManager SecondaryNameNode NameNode DataNode ...
- MySQL数据库InnoDB存储引擎中的锁机制(转载)
http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能导致数据不一致.因此需要一种致机制来将访问顺序化. 锁就是 ...
- [UE4]虚幻4的网络适合开发什么游戏
使用虚幻4开发网络游戏的两种方式 一.虚幻4只做客户端,服务器端独立开发,适用于任何网络游戏 二.使用虚幻4同时开发客户端和服务器(使用虚幻4内置的服务器),适用于一部分网络游戏. 如果使用虚幻4作为 ...
- ArcMap VBA实现连续编号
连续编号VBA部分:Static lCount as longlCount=lCount+1赋值部分:lCount (从1开始)lCount-1 (从0开始)