K最近邻算法
K最近邻(K-Nearest-Neighbour,KNN)算法是机器学习里简单易掌握的一个算法。通过你的邻居判断你的类型,“近朱者赤,近墨者黑”表达了K近邻的算法思想。
一.算法描述:
1.1 KNN算法的原理
KNN算法的前提是存在一个样本的数据集,每一个样本都有自己的标签,表明自己的类型。现在有一个新的未知的数据,需要判断它的类型。那么通过计算新未知数据与已有的数据集中每一个样本的距离,然后按照从近到远排序。取前K个最近距离的样本,来判断新数据的类型。
通过两个例子来说明KNN算法的原理
(1)下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
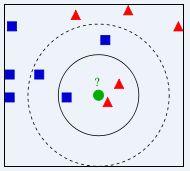
从该图中可以看出K值的选取对类别的判断具有较大的影响,K的选择目前没有很好的办法,经验规则K值一般低于训练样本的开平方。
(2)有六部已知类型的电影,有人统计了电影场景中打斗次数和接吻次数,如下表。最后一行表示有一部新的电影,统计了其中打斗和接吻的次数,那么如何判断这部电影是爱情片还是动作片。
|
电影名称 |
打斗次数 |
接吻次数 |
电影类型 |
|
California Man |
3 |
104 |
Romance |
|
He’s Not Really into Dudes |
2 |
100 |
Romance |
|
Beautiful Woman |
1 |
81 |
Romance |
|
Kevin Longblade |
101 |
10 |
Action |
|
Robo Slayer 3000 |
99 |
5 |
Action |
|
Amped II |
98 |
2 |
Action |
|
未知 |
18 |
90 |
Unknown |
将打斗次数和接吻次数分别作为x,y轴,得到下图

?表示未知电影的未知,然后计算该位置到其他点的距离,假定K=3,可知,距离最近都是爱情片,因此判定该电影也是爱情片。
1.2 KNN算法的优缺点
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
1.3 算法执行步骤:
(1)生成向量位置
(2)计算样本集到新数据的距离
(3)对样本集按距离进行排序
(4)根据K选取样本,判定类型
二.Python实现
1.简单实现
创建数据集并实现knn算法
#knn agorithm***
#2014-1-28 *** from numpy import
import operator def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet
ddMat=diffMat**2
dsumMat=sum(ddMat,axis=1)
deqrMat=dsumMat**0.5
sortMat=deqrMat.argsort()
dic={}
for i in range(k):
lab=labels[sortMat[i]]
dic[lab]=dic.get(lab,0)+1
maxlabelcout=sorted(dic.iteritems(),key=operator.itemgetter(1),reverse=True)
return maxlabelcout[0][0]
对测试数据进行类型判断
#knn *********
#run the knn1 with [0,0]****
#2014-1-28 *********
#zhen ********* import knn1 group,labels=knn1.createDataSet()
print group
print labels
g=knn1.classify0([0,0],group,labels,3)
print g
2.实际应用-约会网站
###knn agorithm
###2014-1-28 from numpy import *
import operator #knn
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
diffMat=tile(inX,(dataSetSize,1))-dataSet
ddMat=diffMat**2
dsumMat=sum(ddMat,axis=1)
deqrMat=dsumMat**0.5
sortMat=deqrMat.argsort()
dic={}
for i in range(k):
lab=labels[sortMat[i]]
dic[lab]=dic.get(lab,0)+1
maxlabelcout=sorted(dic.iteritems(),key=operator.itemgetter(1),reverse=True)
return maxlabelcout[0][0] def fileopen(filename):
f=open(filename)
flines=f.readlines()
fsize=len(flines)
index=0
mat=zeros((fsize,3))
labels=[]
for line in flines:
line=line.strip()
list=line.split('\t')
mat[index,:]=list[0:3]
labels.append(int(list[-1]))
index+=1
return mat,labels def autonorm(Dataset):
dmin=Dataset.min(0)
dmax=Dataset.max(0)
ranges=dmax-dmin
datanorm=zeros(shape(Dataset))
m=Dataset.shape[0]
datanorm=Dataset-tile(dmin,(m,1))
datanorm=datanorm/tile(ranges,(m,1))
return datanorm,ranges,dmin def classTest():
hoRatio=0.1
mat,lables=fileopen('datingTestSet2.txt')
dataNorm,ranges,dmin=autonorm(mat)
m=mat.shape[0]
numTest=int(m*hoRatio)
errorCount=0.0
for i in range(numTest):
lablesTest=classify0(dataNorm[i,:],dataNorm[numTest:m,:],\
lables[numTest:m],3)
if (lablesTest!=lables[i]):
errorCount+=1.0
print "the classifier came back with:%d,the real answer is:%d"\
%(lablesTest,lables[i])
print "the total error rate is: %f" % (errorCount/numTest) def classifyperson():
resultTypeList=['not at all','in small doses','in large doses']
percentGame=float(raw_input(\
"percentage of time spent playing video games?"))
miles=float(raw_input("miles earned per year?"))
iceCream=float(raw_input("liters of ice cream per year?"))
mat,lables=fileopen('datingTestSet2.txt')
dataNorm,ranges,dmin=autonorm(mat)
arr=array([miles,percentGame,iceCream])
result=classify0((arr-dmin)/ranges,dataNorm,lables,3)
print "You will probably like this person: ",\
resultTypeList[result-1]
3.手写识别
K最近邻算法的更多相关文章
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
- 《算法图解》——第十章 K最近邻算法
第十章 K最近邻算法 1 K最近邻(k-nearest neighbours,KNN)——水果分类 2 创建推荐系统 利用相似的用户相距较近,但如何确定两位用户的相似程度呢? ①特征抽取 对水果 ...
- 12、K最近邻算法(KNN算法)
一.如何创建推荐系统? 找到与用户相似的其他用户,然后把其他用户喜欢的东西推荐给用户.这就是K最近邻算法的分类作用. 二.抽取特征 推荐系统最重要的工作是:将用户的特征抽取出来并转化为度量的数字,然后 ...
- [笔记]《算法图解》第十章 K最近邻算法
K最近邻算法 简称KNN,计算与周边邻居的距离的算法,用于创建分类系统.机器学习等. 算法思路:首先特征化(量化) 然后在象限中选取目标点,然后通过目标点与其n个邻居的比较,得出目标的特征. 余弦相似 ...
- PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废, 所以在生产前需计划多投一定比例的板板, 例:订单 量是5000pcs,加投3%,那 ...
- K最近邻算法项目实战
这里我们用酒的分类来进行实战练习 下面来代码 1.把酒的数据集载入到项目中 from sklearn.datasets import load_wine #从sklearn的datasets模块载入数 ...
- 机器学习【一】K最近邻算法
K最近邻算法 KNN 基本原理 离哪个类近,就属于该类 [例如:与下方新元素距离最近的三个点中,2个深色,所以新元素分类为深色] K的含义就是最近邻的个数.在sklearn中,KNN的K值是通过n ...
- 机器学习-K最近邻算法
一.介绍 二.编程 练习一(K最近邻算法在单分类任务的应用): import numpy as np #导入科学计算包import matplotlib.pyplot as plt #导入画图工具fr ...
- 转载: scikit-learn学习之K最近邻算法(KNN)
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
随机推荐
- DataBase 之 常用操作
(1) try catch 配合 Transactions 使用 --打开try catch功能 set xact_abort on begin try begin tran ) commit tra ...
- jQuery的动画效果
jQuery 是一个 JavaScript 库.jQuery 库可以通过一行简单的标记被添加到网页中. <script type="text/javascript" src= ...
- 2012第二届GIS制图大赛——公开课技术问题&答疑(珍贵资源哦!)(http://blog.csdn.net/arcgis_all/article/details/8216984)
本次制图大赛培训的公开课结束后,我们把所有技术问题收集并进行统一解答,现将这些资料在博文中分享. 由于这些问题涉及了制图技术中较多普遍性的内容,因此是非常珍贵的资源,希望能对大家有帮助. ——符号及符 ...
- WdatePicker时间控件联动选择
$("#txtStartTime").bind("click focus", function () { var endtimeTf = $dp.$('txtE ...
- 实验教学管理系统 c语言程序代写源码下载
问题描述:实验室基本业务活动包括:实验室.班级信息录入.查询与删除:实验室预定等.试设计一个实验教学管理系统,将上述业务活动借助计算机系统完成. 基本要求: 1.必须存储的信息 (1)实验室信息:编号 ...
- js常用代码收藏
--1.遍历string分割为数组 <script language="javascript"> str="2,2,3,5,6,6"; //这是一字 ...
- java 调用OpenOffice将word格式文件转换为pdf格式
一:环境搭建 OpenOffice 下载地址http://www.openoffice.org/ JodConverter 下载地址http://sourceforge.net/projects/jo ...
- Mina的线程模型
在Mina的NIO模式中有三种I/O工作线程(这三种线程模型只在NIOSocket中有效,在NIO数据包和虚拟管道中没有,也不需要配置): IoAcceptor/IoConnector线程 IoPro ...
- Python内存解析浅学
1.内存管理 首先理解变量,和内存特性 1. Python中无须声明变量, 2. 无须指定类型 3. 不用关心内存管理 4. 变量名会被回收 5. ...
- Git CMD - merge: Join two or more development histories together
命令格式 git merge [-n] [--stat] [--no-commit] [--squash] [--[no-]edit] [-s <strategy>] [-X <st ...