Kemaswill 机器学习 数据挖掘 推荐系统 Ranking SVM 简介
排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简介)。LTR有三种主要的方法:PointWise,PairWise,ListWise。Ranking SVM算法是PointWise方法的一种,由R. Herbrich等人在2000提出, T. Joachims介绍了一种基于用户Clickthrough数据使用Ranking SVM来进行排序的方法(SIGKDD, 2002)。
1. Ranking SVM的主要思想
Ranking SVM是一种Pointwise的排序算法, 给定查询q, 文档d1>d2>d3(亦即文档d1比文档d2相关, 文档d2比文档d3相关, x1, x2, x3分别是d1, d2, d3的特征)。为了使用机器学习的方法进行排序,我们将排序转化为一个分类问题。我们定义新的训练样本, 令x1-x2, x1-x3, x2-x3为正样本,令x2-x1, x3-x1, x3-x2为负样本, 然后训练一个二分类器(支持向量机)来对这些新的训练样本进行分类,如下图所示:
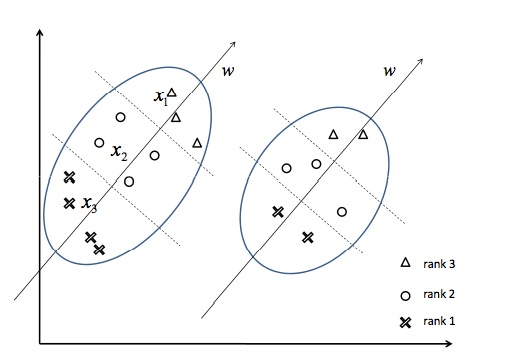
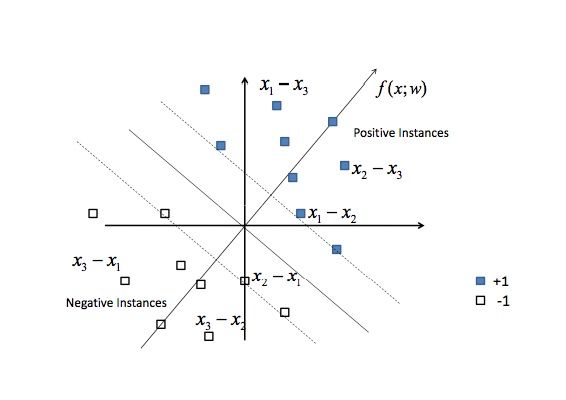
左图中每个椭圆代表一个查询, 椭圆内的点代表那些要计算和该查询的相关度的文档, 三角代表很相关, 圆圈代表一般相关, 叉号代表不相关。我们把左图中的单个的文档转换成右图中的文档对(di, dj), 实心方块代表正样本, 亦即di>dj, 空心方块代表负样本, 亦即di<dj。
2. Ranking SVM
将排序问题转化为分类问题之后, 我们就可以使用常用的机器学习方法解决该问题。 Ranking SVM使用SVM来进行分类:
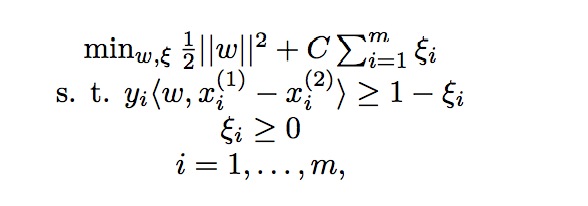
其中w为参数向量, x为文档的特征,y为文档对之间的相对相关性, ξ为松弛变量。
3. 使用Clickthrough数据作为训练数据
T. Joachims提出了一种非常巧妙的方法, 来使用Clickthrough数据作为Ranking SVM的训练数据。
假设给定一个查询"Support Vector Machine", 搜索引擎的返回结果为

其中1, 3, 7三个结果被用户点击过, 其他的则没有。因为返回的结果本身是有序的, 用户更倾向于点击排在前面的结果, 所以用户的点击行为本身是有偏(Bias)的。为了从有偏的点击数据中获得文档的相关信息, 我们认为: 如果一个用户点击了a而没有点击b, 但是b在排序结果中的位置高于a, 则a>b。
所以上面的用户点击行为意味着: 3>2, 7>2, 7>4, 7>5, 7>6。
4. Ranking SVM的开源实现
H. Joachims的主页上有Ranking SVM的开源实现。
数据的格式与LIBSVM的输入格式比较相似, 第一列代表文档的相关性, 值越大代表越相关, 第二列代表查询, 后面的代表特征

3 qid:1 1:1 2:1 3:0 4:0.2 5:0 # 1A
2 qid:1 1:0 2:0 3:1 4:0.1 5:1 # 1B
1 qid:1 1:0 2:1 3:0 4:0.4 5:0 # 1C
1 qid:1 1:0 2:0 3:1 4:0.3 5:0 # 1D
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2A
2 qid:2 1:1 2:0 3:1 4:0.4 5:0 # 2B
1 qid:2 1:0 2:0 3:1 4:0.1 5:0 # 2C
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2D
2 qid:3 1:0 2:0 3:1 4:0.1 5:1 # 3A
3 qid:3 1:1 2:1 3:0 4:0.3 5:0 # 3B
4 qid:3 1:1 2:0 3:0 4:0.4 5:1 # 3C
1 qid:3 1:0 2:1 3:1 4:0.5 5:0 # 3D
训练模型和对测试数据进行排序的代码分别为:
./svm_rank_learn path/to/train path/to/model
./svm_classify path/to/test path/to/model path/to/rank_result
参考文献:
[1]. R. Herbrich, T. Graepel, and K. Obermayer. Large margin rank boundaries for ordinal regression. In Advances in Large Margin Classifiers, 2000.
[2]. T. Joachims. Optimizing Search Engines using Clickthrough Data. SIGKDD, 2002.
[3]. Hang Li. A Short Introduction to Learning to Rank.
[4]. Tie-yan Liu. Learning to Rank for Information Retrieval.
[5]. Learning to Rank简介
Kemaswill 机器学习 数据挖掘 推荐系统 Ranking SVM 简介的更多相关文章
- Kemaswill 机器学习 数据挖掘 推荐系统 Python optparser模块简介
Python optparser模块简介
- 【机器学习】Learning to Rank之Ranking SVM 简介
Learning to Rank之Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning t ...
- Learning to Rank之Ranking SVM 简介
排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简 ...
- 机器学习 数据挖掘 推荐系统机器学习-Random Forest算法简介
Random Forest是加州大学伯克利分校的Breiman Leo和Adele Cutler于2001年发表的论文中提到的新的机器学习算法,可以用来做分类,聚类,回归,和生存分析,这里只简单介绍该 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 【机器学习】Learning to Rank 简介
Learning to Rank 简介 去年实习时,因为项目需要,接触了一下Learning to Rank(以下简称L2R),感觉很有意思,也有很大的应用价值.L2R将机器学习的技术很好的应用到了排 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
随机推荐
- 浅谈javascript性能-管理内存
上次说到,javascript脚本到底应该放在哪里?用什么用处? 以下2点: 在Html.Body部分中的JS会在页面加载的时候执行.即-用户触发一个事件的时候执行的脚本.eg:onload事件... ...
- 探讨css中repaint和reflow
(个人blog迁移文章.) 前言: 页面设计中,不可避免的需要浏览器进行repaint和reflow.那到底什么是repaint和reflow呢.下面谈谈自己对repaint和reflow的理解,以及 ...
- ASP.NET MVC创建的网站
ASP.NET MVC创建的网站 最近在写一个网站,昨天刚写完,由于要和朋友一起测试,但是他电脑上没有环境,所以希望我在自己电脑上部署一下,让他直接通过浏览器来访问来测试,所以从昨晚到今天上午,通 ...
- SQL点滴35—SQL语句中的exists
原文:SQL点滴35-SQL语句中的exists 比如在Northwind数据库中有一个查询为 SELECT c.CustomerId,CompanyName FROM Customers c WHE ...
- 功能和形式的反思sql声明 一个
日前必须使用sql语句来查询数据库 但每次你不想写一个数据库中读取所以查了下反射 我想用反映一个实体的所有属性,然后,基于属性的查询和分配值 首先,须要一个实体类才干反射出数据库相应的字段, 可是開始 ...
- ASP.NET MVC项目里创建一个aspx视图
先从控制器里添加视图 视图引擎选"ASPX(C#)",使用布局或模板页不要选. 在Views\EAV目录里,生成的aspx是个单独的页面,没有代码文件,所以代码也要写在这个文件里. ...
- Hibernate的三种缓存
一级缓存 hibernate的一级缓存是跟session绑定的,那么一级缓存的生命周期与session的生命周期一致,因此,一级缓存也叫session级缓存或者事务级缓存. 支持一级缓存的方法有: q ...
- 利用cxfreeze将Python 3.3打包成exe程序
参考自别人的博文:http://blog.csdn.net/yatere/article/details/6667230 步骤如下: (1) 下载cxfreeze后安装(先得安装python 3.3) ...
- NET系列文章
NET系列文章 由于博主今后一段时间可能会很忙(准备出书:<.NET框架设计—模式.配置.工具>,外加换了新工作),所以博客会很少更新: 在最近一年左右时间里,博主各种.NET技术类型的文 ...
- XLink and XPoint
XLink 定义在 XML 文档中创建超级链接的标准方法. XPointer 允许这些超级链接指向 XML 文档中的更多具体部分(片断). XLink XLink 是 XML 链接语言(XML Lin ...