转载 Deep learning:四(logistic regression练习)
前言:
本节来练习下logistic regression相关内容,参考的资料为网页:http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearning&doc=exercises/ex4/ex4.html。这里给出的训练样本的特征为80个学生的两门功课的分数,样本值为对应的同学是否允许被上大学,如果是允许的话则用’1’表示,否则不允许就用’0’表示,这是一个典型的二分类问题。在此问题中,给出的80个样本中正负样本各占40个。而这节采用的是logistic regression来求解,该求解后的结果其实是一个概率值,当然通过与0.5比较就可以变成一个二分类问题了。
实验基础:
在logistic regression问题中,logistic函数表达式如下:
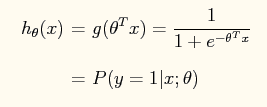
这样做的好处是可以把输出结果压缩到0~1之间。而在logistic回归问题中的损失函数与线性回归中的损失函数不同,这里定义的为:
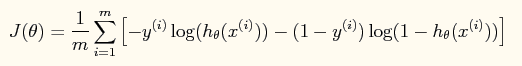
如果采用牛顿法来求解回归方程中的参数,则参数的迭代公式为:
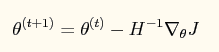
其中一阶导函数和hessian矩阵表达式如下:
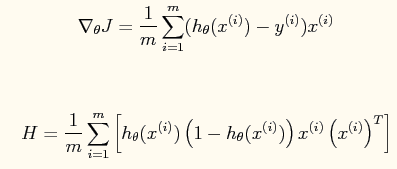
当然了,在编程的时候为了避免使用for循环,而应该直接使用这些公式的矢量表达式(具体的见程序内容)。
一些matlab函数:
find:
是找到的一个向量,其结果是find函数括号值为真时的值的下标编号。
inline:
构造一个内嵌的函数,很类似于我们在草稿纸上写的数学推导公式一样。参数一般用单引号弄起来,里面就是函数的表达式,如果有多个参数,则后面用单引号隔开一一说明。比如:g = inline('sin(alpha*x)','x','alpha'),则该二元函数是g(x,alpha) = sin(alpha*x)。
实验结果:
训练样本的分布图以及所学习到的分类界面曲线:
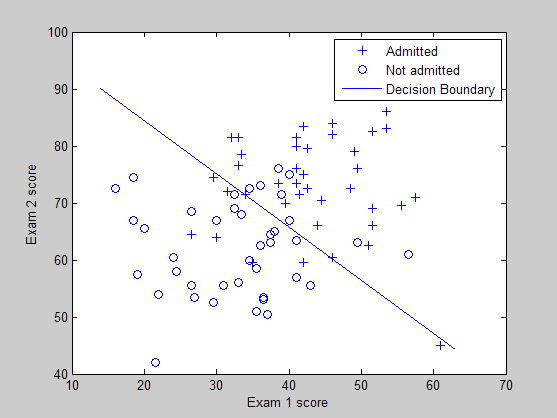
损失函数值和迭代次数之间的曲线:

最终输出的结果:

可以看出当一个小孩的第一门功课为20分,第二门功课为80分时,这个小孩不允许上大学的概率为0.6680,因此如果作为二分类的话,就说明该小孩不会被允许上大学。
实验代码(原网页提供):
% Exercise 4 -- Logistic Regression
clear all; close all; clc
x = load('ex4x.dat');
y = load('ex4y.dat');
[m, n] = size(x);
% Add intercept term to x
x = [ones(m, 1), x];
% Plot the training data
% Use different markers for positives and negatives
figure
pos = find(y); neg = find(y == 0);%find是找到的一个向量,其结果是find函数括号值为真时的值的编号
plot(x(pos, 2), x(pos,3), '+')
hold on
plot(x(neg, 2), x(neg, 3), 'o')
hold on
xlabel('Exam 1 score')
ylabel('Exam 2 score')
% Initialize fitting parameters
theta = zeros(n+1, 1);
% Define the sigmoid function
g = inline('1.0 ./ (1.0 + exp(-z))');
% Newton's method
MAX_ITR = 7;
J = zeros(MAX_ITR, 1);
for i = 1:MAX_ITR
% Calculate the hypothesis function
z = x * theta;
h = g(z);%转换成logistic函数
% Calculate gradient and hessian.
% The formulas below are equivalent to the summation formulas
% given in the lecture videos.
grad = (1/m).*x' * (h-y);%梯度的矢量表示法
H = (1/m).*x' * diag(h) * diag(1-h) * x;%hessian矩阵的矢量表示法
% Calculate J (for testing convergence)
J(i) =(1/m)*sum(-y.*log(h) - (1-y).*log(1-h));%损失函数的矢量表示法
theta = theta - H\grad;%是这样子的吗?
end
% Display theta
theta
% Calculate the probability that a student with
% Score 20 on exam 1 and score 80 on exam 2
% will not be admitted
prob = 1 - g([1, 20, 80]*theta)
%画出分界面
% Plot Newton's method result
% Only need 2 points to define a line, so choose two endpoints
plot_x = [min(x(:,2))-2, max(x(:,2))+2];
% Calculate the decision boundary line,plot_y的计算公式见博客下面的评论。
plot_y = (-1./theta(3)).*(theta(2).*plot_x +theta(1));
plot(plot_x, plot_y)
legend('Admitted', 'Not admitted', 'Decision Boundary')
hold off
% Plot J
figure
plot(0:MAX_ITR-1, J, 'o--', 'MarkerFaceColor', 'r', 'MarkerSize', 8)
xlabel('Iteration'); ylabel('J')
% Display J
J
参考资料:
作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 欢迎转载或分享,但请务必声明文章出处。
转载 Deep learning:四(logistic regression练习)的更多相关文章
- 转载 Deep learning:三(Multivariance Linear Regression练习)
前言: 本文主要是来练习多变量线性回归问题(其实本文也就3个变量),参考资料见网页:http://openclassroom.stanford.edu/MainFolder/DocumentPage. ...
- 转载 Deep learning:六(regularized logistic回归练习)
前言: 在上一讲Deep learning:五(regularized线性回归练习)中已经介绍了regularization项在线性回归问题中的应用,这节主要是练习regularization项在lo ...
- [转载]Deep Learning(深度学习)学习笔记整理
转载自:http://blog.csdn.net/zouxy09/article/details/8775360 感谢原作者:zouxy09@qq.com 八.Deep learning训练过程 8. ...
- 转载 deep learning:八(SparseCoding稀疏编码)
转载 http://blog.sina.com.cn/s/blog_4a1853330102v0mr.html Sparse coding: 本节将简单介绍下sparse coding(稀疏编码),因 ...
- machine learning 之 logistic regression
整理自Adrew Ng 的 machine learning课程week3 目录: 二分类问题 模型表示 decision boundary 损失函数 多分类问题 过拟合问题和正则化 什么是过拟合 如 ...
- CheeseZH: Stanford University: Machine Learning Ex2:Logistic Regression
1. Sigmoid Function In Logisttic Regression, the hypothesis is defined as: where function g is the s ...
- (四)Logistic Regression
1 线性回归 回归就是对已知公式的未知参数进行估计.线性回归就是对于多维空间中的样本点,用特征的线性组合去拟合空间中点的分布和轨迹,比如已知公式是y=a∗x+b,未知参数是a和b,利用多真实的(x,y ...
- 转载 Deep learning:二(linear regression练习)
前言 本文是多元线性回归的练习,这里练习的是最简单的二元线性回归,参考斯坦福大学的教学网http://openclassroom.stanford.edu/MainFolder/DocumentPag ...
- 转载 Deep learning:一(基础知识_1)
前言: 最近打算稍微系统的学习下deep learing的一些理论知识,打算采用Andrew Ng的网页教程UFLDL Tutorial,据说这个教程写得浅显易懂,也不太长.不过在这这之前还是复习下m ...
随机推荐
- linux中的守护进程
概念Daemon(精灵)进程,是Linux中的后台服务进程,生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件.模型守护进程编程步骤1. 创建子进程,父进程退出所有工 ...
- 使用 mulan-1.5.0 如何构造.arff文件
1. 为什么要使用mulan 我用mulan来做多标签数据的分类,但是mulan的输入数据由两个文件控制,一个是data.arff文件,这个文件列出的所有的属性以及这些属性值的类型和他们对应的值.la ...
- hdu 5874 Friends and Enemies icpc大连站网络赛 1007 数学
#include<stdio.h> #include<iostream> #include<algorithm> #include<math.h> #i ...
- stl 生产全排列 next_permutation
#include<stdio.h>#include<algorithm>using namespace std;int main(){ int n,p[10]; scanf(& ...
- SIM卡信息的管理
MTK平台上,所有插入到手机中的SIM卡的信息都会存储在数据库com.android.providers.telephony中. 原始的数据库 图表 1 SimInfo数据表的结构 从上图示中,我们可 ...
- bootstrap validator html attributes 选项
常用的html属性:data-fv-message="The username is not valid"data-fv-notempty="true"data ...
- iOS导航栏主题
主要是取得导航栏的appearance对象,操作它就设置导航栏的主题 UINavigationBar *navBar = [UINavigationBar appearance]; 常用主题设置 导航 ...
- hibernate在配置文件中配置对象关系映射文件即hbm文件路径的写法
hbm文件如果在src下,则<mapping resource="*.hbm.xml"/> 如果在实体类包中,则<mapping resource="c ...
- Oracle 10gR2 Dataguard搭建(非duplicate方式)
Oracle 10gR2 Dataguard搭建(非duplicate方式) 我的实验环境: 源生产库(主库): IP地址:192.168.1.30 Oracle 10.2.0.5 单实例 新DG库( ...
- Emacs阅读chm文档
.title { text-align: center; margin-bottom: .2em } .subtitle { text-align: center; font-size: medium ...