python第三方库Requests的基本使用
Requests 是用python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。Requests 的哲学是以 PEP 20 的习语为中心开发的,所以它比 urllib 更加 Pythoner。
通过pip安装
pip install requests 一、最基本的get请求
import requests
req=requests.get('https://www.cnblogs.com/')#普通的get请求
print(req.text)#解析网页标签,查找头域head中的meta标签<meta charset="utf-8" />
print(req.content)#出来的中文有些是乱码,需要解码
print(req.content.decode('utf-8'))#用decode解码
requests.get(‘https://github.com/timeline.json’) #GET请求
requests.post(“http://httpbin.org/post”) #POST请求
requests.put(“http://httpbin.org/put”) #PUT请求
requests.delete(“http://httpbin.org/delete”) #DELETE请求
requests.head(“http://httpbin.org/get”) #HEAD请求
requests.options(“http://httpbin.org/get”) #OPTIONS请求
不但GET方法简单,其他方法都是统一的接口样式
二、用post获取需要用户名密码登陆的网页
import requests
postdata={
'name':'estate',
'pass':''
}#必须是字典类型
req=requests.post('http://www.iqianyue.com/mypost',data=postdata)
print(req.text)#进入登陆后的页面
yonghu=req.content#用户登陆后的结果
f=open('1.html','wb')#把结果写入1.html
f.write(yonghu)
f.close()
http://www.iqianyue.com/mypost
进入这个网站需要登陆,我们要定义一个字典输入用户名和密码
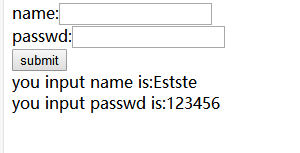
运行没有报错可以把结果写在一个HTML文件中
<html>
<head>
<title>Post Test Page</title>
</head> <body>
<form action="" method="post">
name:<input name="name" type="text" /><br>
passwd:<input name="pass" type="text" /><br>
<input name="" type="submit" value="submit" />
<br />
you input name is:estate<br>you input passwd is:123456</body>
</html>
三、用headers针对反爬
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}#请求头发送请求,多个头域可以直接在字典中添加
req=requests.get('http://maoyan.com/board',headers=headers)#传递实参
print(req.text)
User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
有些网页进去后会出现403禁止访问,我们需要进入网页查找到hesders中的User-Agent并添加到字典中,读取时要传递实参,运行后并可爬取猫眼电影网页信息
四、用cookies跳过登陆
import requests
f=open('cookies.txt','r')
#初始化cookies字典变量
cookies={}
#用for循环遍历切割。按照字符;进行切割读取,返回列表数据然后遍历
for line in f.read().split(';'):
#split参数设置为1,将字符串切割成两部分
name,value=line.split('=',1)
#为字典cookies添加内容
cookies[name] = value
url='https://www.cnblogs.com/'
res=requests.get(url,cookies=cookies)
data=res.content
f1=open('bokeyuan.html','wb')
f1.write(data)
f1.close()
f.close()
先输入用户名和密码登陆网页后获取网页的cookies,复制粘贴到新建的文本中,创建一个空的cookies字典,用for循环遍历切割。cookies中的字段按照字符 ; 进行切割读取成两部分。
运行后把结果写到命名为bokeyuan的html文件中,进入html文件直接点击网页图标即可进入登陆后的页面
五、代理IP
import requests
proxies={
'HTTP':'183.129.244.17:10080'
}
req=requests.get('https://www.taobao.com/',proxies=proxies)
print(req.text)
采集时为避免被封IP,经常会使用代理。requests也有相应的proxies属性。我们可以在网页上查找代理IP,在字典中输入代理IP地址和端口,需要多个IP可以直接在字典后面添加。如果代理需要账户和密码,则需这样:
proxies = {
"http": "http://user:pass@10.10.1.10:3128/",
}
六、超时设置
import requests
req=requests.get('https://www.taobao.com/',timeout=1)
print(req.text)
timeout 仅对连接过程有效,与响应体的下载无关 以上为Requests库的基础操作,后续再做补充......
python第三方库Requests的基本使用的更多相关文章
- python第三方库requests简单介绍
一.发送请求与传递参数 简单demo: import requests r = requests.get(url='http://www.itwhy.org') # 最基本的GET请求 print(r ...
- python第三方库requests详解
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTT ...
- Python第三方库requests的编码问题
PS:这个解决方法可能很简单,但是这是平时的一些细节问题,所以有必要提醒一下! 首先代码不多,就是通过get方法去获取豆瓣首页信息,如图:但是会报UnicodeEncodeError: 'gbk' c ...
- Python中第三方库Requests库的高级用法详解
Python中第三方库Requests库的高级用法详解 虽然Python的标准库中urllib2模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人实在感觉不好.它已经不适合现在的时代, ...
- [爬虫]Windows下如何安装python第三方库lxml
lxml是个非常有用的python库,它可以灵活高效地解析xml与BeautifulSoup.requests结合,是编写爬虫的标准姿势. 但是,当lxml遇上Windows,简直是个巨坑.掉在安装陷 ...
- 【Python基础】安装python第三方库
pip命令行安装(推荐) 打开cmd命令行 安装需要的第三方库如:pip install numpy 在安装python的相关模块和库时,我们一般使用“pip install 模块名”或者“pyth ...
- python第三方库自动安装脚本
#python第三方库自动安装脚本,需要在cmd中运行此脚本#BatchInstall.pyimport oslibs = {"numpy","matplotlib&qu ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- Windows下如何安装python第三方库lxml
lxml是个非常有用的python库,它可以灵活高效地解析xml,与BeautifulSoup.requests结合,是编写爬虫的标准姿势. 参考 Windows下如何安装python第三方库lxml ...
随机推荐
- flashfxp 数据socket错误 连接已超时 filezilla
最近windows server 开启了防火墙后发现flashfxp连不上,报超时. 1,服务端的动态端口从指定的范围内取, 2,防火墙开启范围内端口. 参考:http://jingyan.baidu ...
- C语言与C++语言的强制类型转换格式区别
C语言:(类型)(表达式),其中类型的括号()必须带. C++语言:(类型)(表达式),其中类型的括号()跟进表达式选带.
- python如何实现像shell中的case功能
我们知道在shell脚本里是支持case语句,当位置参数为空时,会提示我们怎么使用脚本 那么在python怎么实现呢?也使用case吗? python里不支持case语句,但是也有实现case的方法. ...
- mybatis oracle:批量操作(增删改查)
此文主要是讲mybatis在连接oracle数据库时的一些批量操作,请各位对号入座 (最后回来补充一下,所有都是在Spring+MVC的框架下实现的) 不废话,上代码: 1.批量插入(网上很多,是针对 ...
- postman之如何获取cookie
1.最近在学习postman的使用方法,为了保证后续模块操作,必须在登录时获取的session值,并将其设置为环境变量,session的位置处于response headers里面返回的set-coo ...
- XQuery:查询任何可作为 XML 形态呈现的数据,包括数据库
XQuery 也被称为 XML Query,被设计用来查询 XML 数据. 学习这个 需要知道 HTML / XHTML XML / XML 命名空间 XPath XML 实例文档 我们将在下面的例子 ...
- Xcodebuild ipa shell
命令行下打包iOS App工程: #!/bin/sh # # How To Build ? #http://www.jianshu.com/p/3f43370437d2 #http://www.jia ...
- Qthread的使用方法
1:重载 run()函数 2:将对象移到Qthread对象中 Movetothread 该方法必须通过信号 -槽来激发.
- 统计php-fpm内存占用
查看php-fpm的内存占用 1.查看php-fpm的进程个数 ps -ef |grep "php-fpm"|grep "pool"|wc -l 2.查看每个p ...
- PTA——组合数
PTA 7-48 求组合数 #include<stdio.h> double fact(int n); int main() { int m,n; int c; scanf("% ...