指导手册05:MapReduce编程入门
指导手册05:MapReduce编程入门
Part 1:使用Eclipse创建MapReduce工程
操作系统:
Centos 6.8, hadoop 2.6.4
情景描述:
因为Hadoop本身就是由Java开发的,所以通常也选用Eclipse作为MapReduce的编程工具,本小节将完成Eclipse安装,MapReduce集成环境配置。
1.下载与安装Eclipse
(1)在官网下载Eclipse安装包“Eclipse IDE for Java EE Developers”官网:https://www.eclipse.org/downloads/packages/
(2)将Eclipse安装包解压到本地的安装目录
(3)将插件hadoop-eclipse-plugin-2.6.0jar拷贝到Eclipse安装目录下的dropins目录
(4)双击解压文件下Eclipse文件夹中的图标,打开Eclipse
2.配置MapReduce环境
(1)增加Map/Reduce功能区。
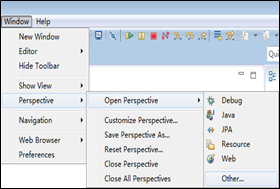
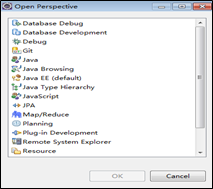
打开Eclipse主界面,在菜单中选择“Window”->”Perspective”->”Open Perspective”->”Other”命令,在弹出的菜单中选择”Map/Reduce”选择,然后单击“OK”按钮确定。
(2)增加Hadoop集群的连接。
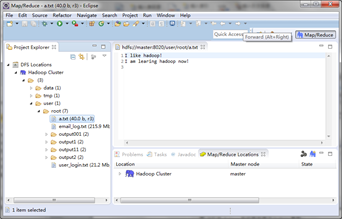
在Eclipse主界面下方的控制台界面中,选中选项卡“Map/Reduce Locations”,如下图所示:
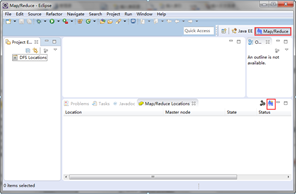
单击上图所示右下方的蓝色小象图标(其右上方有+号),就会弹出连接Hadoop集群的配置对话框。
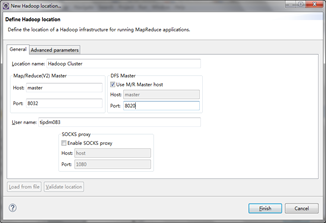
map/Reduce 端口:8032,DFS端口:8020 和core-site.xml中配置一致
相关的Hadoop 集群的连接信息有以下各项。
ü Location name:命名新建的Hadoop连接,如Hadoop Cluster.
ü Map/Reduce(v2)Master:填写Hadoop集群的ResourceManager的IP地址和端口。(查看yarn-site.xml配置文件)。
ü DFS Master:填写Hadoop集群的NameNode的IP地址和连接端口。(查看core-site.xml配置文件)
(3)浏览HDFS上的目录文件。
3.新建MapReduce工程
(1)导入MapReduce运行依赖的相关Jar包
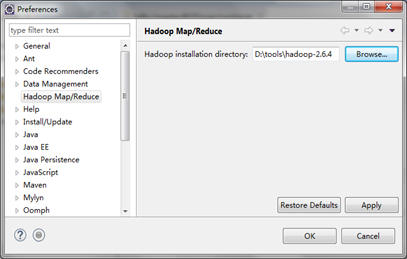
在主菜单上选择”Window”->”Preferences”命令,在下图的Preference窗口中选择“Hadoop Map/Reduce”选项,单击“Browse”按钮,选中Hadoop的安装文件夹路径。
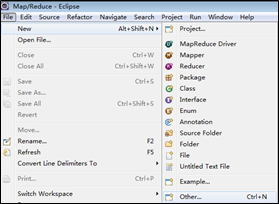
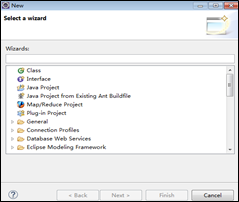
(2)创建MapReduce工程。从菜单栏中选择“File”->”New”->”Project”命令,在弹出的New对话框中选择“Map/Reduce Project”选项。如下图如示。
(3)在“MapReduce Project”的创建界面中填写工程名“MemberCount”,然后单击“Finish”按钮。
(4)接下来,在主界在左侧的”Project Explorer”栏可以看到己经创建好的工程MemberCout,接下来就可以正式进行MapReduce工作了。
4.实训操作
在Linux中完成Eclipse安装并创建MapReduce工程。(参考:Eclipe在Linux中安装配置参考)
Part 2: 通过源码初识MapReduce编程
情景描述:
在进行MapReduce编程前,有必要对MapReduce的基本原理进行了解,尤其是要对其核心模块Mapper与Reduce的执行流程有一定认识。Hadoop官方提供了一些示例源码,非常适合初学者学习及参考。比如词频统计(WordCount)的源码。
1.词频统计(WordCount)的源码
2.MapReduce原理
MapReduce,在名称上就表现出了它的核心原理,它是由两个阶段组成的。
Map,表示“映射”,在map阶段进行的一系列数据处理任务被称为Mapper模块。
Reduce,表示“归约”,同样,在reduce阶段进行的一系列数据处理任务也被称为Reducer模块。
MapReduce通常也被简称为MR
如果用打比方的方式来说明,MapReduce可以被看作一个专业处理大数据的工程队,它由以下主要成员组成:
(1)Mapper:映射器。
(2)Mapper助理InputFormat:输入文件读取器。
(3)Shuffle:运输队。
(4)Shuffle助理Sorter:排序器。
(5)Reducer:归约器。
(6)Reducer助理OutputFormat:输出结果写入器。

- 数据分片。假设原始文件中8000万行记录被系统分配给100个Mapper来处理,那么每个Mapper处理80万行数据。相当于MapReduce通过数据分片的方式,把数据分发给多个单元来进行处理,这就是分布式计算的第一步。
- 数据映射。在数据分片完成后,由Mapper助理InputFormat从文件的输入目录中读取这些记录,然后由Mapper负责对记录进行解析,并重新组织成新的格式。然后Mapper把自己的处理结果输出,等待Shuffle运输队取走结果。
- 数据混洗。由Shuffle运输队把获取的结果按照相同的键(Key)进行汇集,再把结果送到Shuffle助理Sorter,由Sorter负责对这些结果排好序,然后提交给Reducer。
- 数据归约。Reducer收到传输过来的结果后,接着进行汇总与映射工作,得到最终计算结果。最后由Reducer助理OutputFormat把结果输出到指定位置。
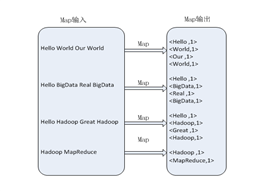
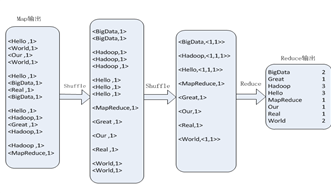
3.MapReduce 实现词频统计的执行流程
map任务的处理过程
reduce任务的处理过程
4.Hadoop MapReduce– 单词计数源码分析Driver
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration(); //程序运行时参数
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if (otherArgs.length != 2)
{ System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count"); //设置环境参数
job.setJarByClass(WordCount.class); //设置整个程序的类名
job.setMapperClass(MyMapper.class); //添加MyMapper类
job.setReducerClass(MyReducer.class); //添加MyReducer类
job.setOutputKeyClass(Text.class); //设置输出类型
job.setOutputValueClass(IntWritable.class); //设置输出类型
FileInputFormat.addInputPath(job,new Path(otherArgs[0])); //设置输入文件
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); //设置输出文件
System.exit(job.waitForCompletion(true)?0:1);
}
在MapReduce任务中涉及4个键值对格式,Mapper输入键值对格式<K1,V1>, Mapper输出键值对格式<K2,V2>,Reducer输出键值对格式<K3,V3 >。当Mapper输出键值对格式<K2,V2>和Reducer输出键值对格式<K3,V3>一样的时候,可以只设置Reducerl输出键值对的格式。
应用程序Driver分析:
(1) 最后部分:提交MapReduce任务运行。
以下是Mapper、Reducer类
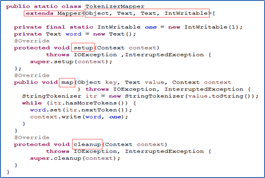
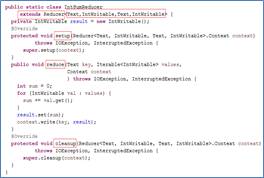
Map 是映射,Reducer是把相同的键列表值全部累加起来。
5.WordCount完整代码:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount{
//WordCount类的具体代码见下面
}
------------------------------------------------------------------------------------------------------------------
(WordCount类代码)
public class WordCount{
public static class MyMapper extends Mapper<Object,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word,one);
}
}
}
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
6实验步骤:
使用java编译程序,生成.class文件
将.class文件打包为jar包
上传到master服务器
[root@maste opt]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-exampes-2.6.4.jar wordcount /user/root/emil_log.txt /user/root/output1
运行jar包(需要启动Hadoop)
这里特别注意的是在WordCount中的命名空间,也就是package那一行的东西外加主类要放到jar包后面,
如:org.apache.hadoop.example.WordCount
[root@centos WordCount]# hadoop dfs -rmr /wc/output
Deleted hdfs://centos:9000/wc/output
[root@centos WordCount]# hadoop jar WordCount.jar org.apache.hadoop.examples.WordCount /wc/input /wc/output
查看结果
7.实训操作
使用有短句“A friend in need is a friend in deed”,画出使用MapReduce对它进行词频统计的过程,主要展示Map阶段与Reduce阶段的处理过程。请画图展示。
指导手册05:MapReduce编程入门的更多相关文章
- 实训任务04 MapReduce编程入门
实训任务04 MapReduce编程入门 1.实训1:画图mapReduce处理过程 使用有短句“A friend in need is a friend in deed”,画出使用MapReduce ...
- Hadoop MapReduce编程入门案例
Hadoop入门例程简介 一个.有些指令 (1)Hadoop新与旧API差异 新API倾向于使用虚拟课堂(象类),而不是接口.由于这更easy扩展. 比如,能够无需改动类的实现而在虚类中加入一个方法( ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 05 mapreduce快速入门
统计HDFS的/wordcount/input/a.txt文件中的每个单词出现的次数——wordcount package cn.oracle.core; import java.io.IOExcep ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- 指导手册04:运行MapReduce
指导手册04:运行MapReduce Part 1:运行单个MapReduce任务 情景描述: 本次任务要求对HDFS目录中的数据文件/user/root/email_log.txt进行计算处理, ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- [Hadoop入门] - 1 Ubuntu系统 Hadoop介绍 MapReduce编程思想
Ubuntu系统 (我用到版本号是140.4) ubuntu系统是一个以桌面应用为主的Linux操作系统,Ubuntu基于Debian发行版和GNOME桌面环境.Ubuntu的目标在于为一般用户提供一 ...
随机推荐
- scanperiod 不生效
注意:要改 target 目录下的,真正运行时加载的 logback-spring.xml
- 创建多线程的第一种方式——创建Thread子类和重写run方法
创建多线程的第一种方式——创建Thread子类和重写run方法: 第二种方式——实现Runnable接口,实现类传参给父类Thread类构造方法创建线程: 第一种方式创建Thread子类和重写run方 ...
- 使用Python在自己博客上进行自动翻页
先上一张代码及代码运行后的输出结果的图! 下面上代码: # coding=utf-8 import os import time from selenium import webdriver #打开火 ...
- jquery改变字符串中部分字符的颜色
//该方法改变字符串中中括号内(包括中括号)的字符串颜色为红色function changecolocer() { var zf = $('#YWFA').text(); if(zf.length&g ...
- KVO的使用一
概述 KVO即Key-Value Observing,它允许一个对象被另一个对象在改变指定的属性值后进行通知.iOS中的应用场景很多,比如model的值发生变化,controller里对model进行 ...
- Python爬虫(一)——开封市58同城租房信息
代码: # coding=utf-8 import sys import csv import requests from bs4 import BeautifulSoup reload(sys) s ...
- 修改mongodb(带仲裁节点的副本集)各机器端口
需求:因为端口调整,需要改变副本的备份集 1.查看当前的副本集信息 [root@localhost bin]# ./mongo 192.168.1.134:10001 repltest:PRIMARY ...
- linux 指令 备份
lsb_release -a LSB是Linux Standard Base的缩写,lsb_release命令用来显示LSB和特定版本的相关信息.如果使用该命令时不带参数,则默认加上-v参数. -v, ...
- Linux系统初始配置标准化
Inux系统标准化 配置环境:4台Centos7.6版本的虚拟机,刚刚最小化安装完成,未作任何操作,分别是node1.node2.node3.node4 本文打算利用ansible工具对这四台虚拟机进 ...
- 模块——Getopt::Long接收客户命令行参数和Smart::Comments输出获得的命令行参数内容
我们在linux常常用到一个程序需要加入参数,现在了解一下 perl 中的有关控制参数的模块 Getopt::Long ,比直接使用 @ARGV 的数组强大多了.我想大家知道在 Linux 中有的参 ...