hadoop 3.x 配置日志聚集功能
打开$HADOOP_HOME/etc/hadoop/yarn-site.xml,增加以下配置(在此配置文件中尽量不要使用中文注释)
<!--logs-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- logs keep time -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
依次执行以下命令start-dfs.sh,start-yarn.sh.mr-jobhistory-daemon.sh start historyserver启动完毕后jps
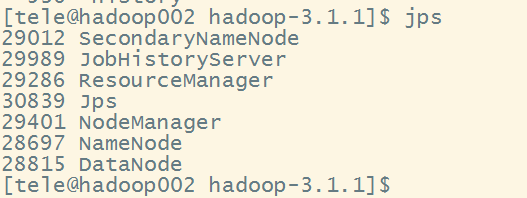
接下来执行MapReduce程序
hadoop fs -rm -r -f /usr/tele/hadoop/wcoutput
hadoop jar /opt/module/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /usr/tele/hadoop/wcinput /usr/tele/hadoop/wcoutput
执行完毕后打开mapreduce管理界面(8088),再打开history(19888),然后打开logs
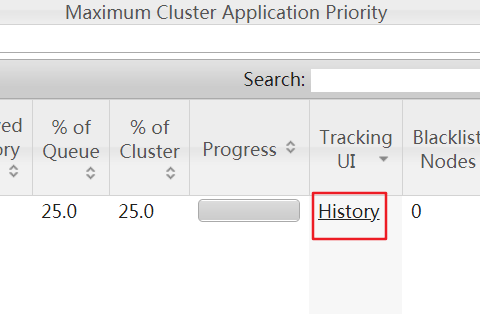
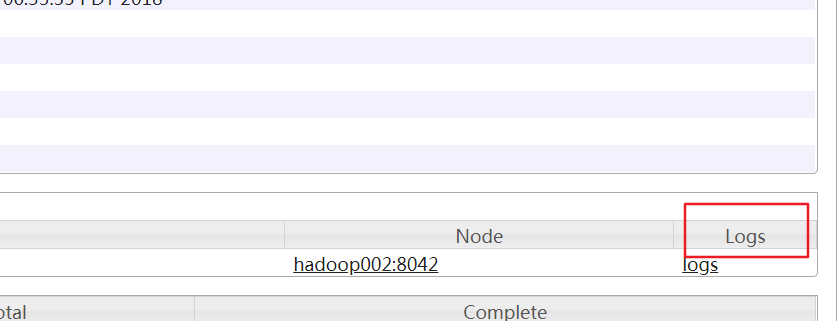
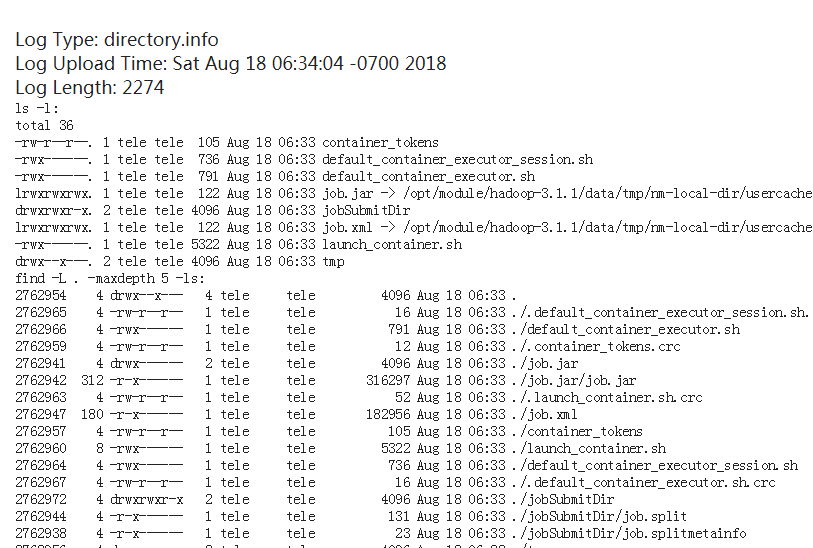
注意的是如果启用了日志聚集功能,那么在userlogs下生成的yarn的作业日志目录在被上传到hdfs上之后就会从linux上删除掉了,大概在执行完mapreduce程序的几秒后
history打不开的请参考https://www.cnblogs.com/tele-share/p/9498698.html
hadoop 3.x 配置日志聚集功能的更多相关文章
- Hadoop基础-完全分布式模式部署yarn日志聚集功能
Hadoop基础-完全分布式模式部署yarn日志聚集功能 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 其实我们不用配置也可以在服务器后台通过命令行的形式查看相应的日志,但为了更方 ...
- Yarn 的日志聚集功能配置使用
需要 hadoop 的安装目录/etc/hadoop/yarn-site.xml 中进行配置 配置内容 <property> <name>yarn.log-aggregati ...
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- 开启spark日志聚集功能
spark监控应用方式: 1)在运行过程中可以通过web Ui:4040端口进行监控 2)任务运行完成想要监控spark,需要启动日志聚集功能 开启日志聚集功能方法: 编辑conf/spark-env ...
- 启用yarn日志聚集功能
在yarn-site.xml配置文件中添加如下内容: ##开启日志聚集功能 <property> <name>yarn.log-ag ...
- Hadoop 历史服务配置启动查看
历史服务配置启动查看 1)配置mapred-site.xml <property> <name>mapreduce.jobhistory.address</name> ...
- hadoop之 YARN配置参数剖析—RM与NM相关参数
参数均需要在yarn-site.xml中配置: 1. ResourceManager相关配置参数 (1) yarn.resourcemanager.address 参数解释:ResourceManag ...
- yarn配置日志聚合
[原文地址] 日志聚集是YARN提供的日志中央化管理功能,它能将运行完成的Container/任务日志上传到HDFS上,从而减轻NodeManager负载,且提供一个中央化存储和分析机制.默认情况下, ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- 洛谷 P2069 松鼠吃果子
P2069 松鼠吃果子 题目描述 有N个一种松鼠喜欢吃的果子由下向上串排成一列,并标号1,2,...N.一只松鼠从最下果子开始向上跳,并且第i次跳可以一次跳过i*i*i除以5的余数+1个果子(=i*i ...
- Intent传递对象的几种方式
原创文章.转载请注明 http://blog.csdn.net/leejizhou/article/details/51105060 李济洲的博客 Intent的使用方法相信你已经比較熟悉了,Inte ...
- Android 获取联系人手机号码、姓名、地址、公司、邮箱、生日
public void testGetAllContact() throws Throwable { //获取联系人信息的Uri Uri uri = ContactsContract.Contacts ...
- Javascript和jquery事件-鼠标移入移出事件
javascript使用mouseover和mouseout,只在css中支持hover jquery支持mouseover和mouseout,封装了mouseenter.mouseleave事件函数 ...
- (转)linux的一个find命令配合rm删除某天前的文件
转自:http://www.cnblogs.com/mingforyou/p/3930624.html 语句写法:find 对应目录 -mtime +天数 -name "文件名" ...
- HTTP详解--请求、响应、缓存
1. HTTP请求格式 做过Socket编程的人都知道,当我们设计一个通信协议时,“消息头/消息体”的分割方式是很常用的,消息头告诉对方这个消息是干什么的,消息体告诉对方怎么干.HTTP协议传输的消息 ...
- 回家过年,CSDN博客暂时歇业
CSDN博客之星2013评选活动,结束了,感谢大家的投票. 我个人只是主动拉了300票左右,2400+的票都是大家主动投的,非常感谢啊! (*^__^*) 年关将至,最近也在忙自己的事情,不再更新了. ...
- Spring Boot Shiro 权限管理
Spring Boot Shiro 权限管理 标签: springshiro 2016-01-14 23:44 94587人阅读 评论(60) 收藏 举报 .embody{ padding:10px ...
- amazeui页面分析4
amazeui页面分析4 一.总结 1.直接照着作者的设计思路用:例如 pet_hd_con_time pet_hd_con_map ,这是time 和 map,那我别的说不定也可以直接用,比如aut ...
- vue-cli 构建vue项目
师父说,咱们还是要用vue-cli 去构建前端项目.然后我就开始了 懵逼之旅. 今天上午主要就是搞懂用webpack和vue-cli怎么搭建 运行项目 首先找到了咱们博客园 园友的博客,提供了大概五个 ...