Scrapy爬取遇到的一点点问题
学了大概一个月Scrapy,自己写了些东东,遇到很多问题,这几天心情也不大好,小媳妇人也不舒服,休假了,自己研究了很久,有些眉目了
利用scrapy 框架爬取慕课网的一些信息
步骤一:新建项目
scrapy startproject muke
进入muke
scrapy genspider mukewang imooc.com #mukewang 为爬虫名,imooc.com 是域名,爬虫爬取的范围
步骤二:编写ITEM,定义需要爬取的字段,此处只定义两个字段吧(初学)

步骤三:编写Spider主题,暂时先只爬取title,有些名词用的比较low,莫怪
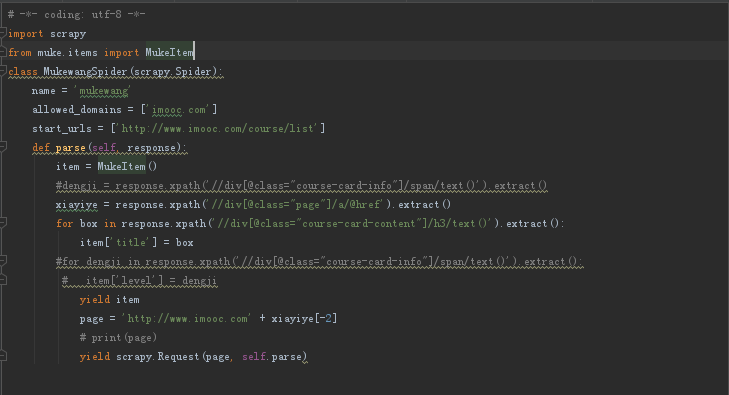
以上基本的东西就写完了
步骤四:运行爬虫 scrapy crwal mukewang 查看结果 爬取结果较多就不一一列举了
期间遇到一点点问题问题,就是我的爬取结果只限制在第一页,收到一个DEUBG信息:
原来是我的allowed_domains出现问题 将allowed_domains=['www.imooc.com/']改为allowed_domains=['imooc.com']即可实现全部爬取
本次算是初学爬虫,自己写了点东西,但是远远没有达到要求,比如储存到数据库,路漫漫其修远兮,吾将上下而求索!!
Scrapy爬取遇到的一点点问题的更多相关文章
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
- 用scrapy爬取京东的数据
本文目的是使用scrapy爬取京东上所有的手机数据,并将数据保存到MongoDB中. 一.项目介绍 主要目标 1.使用scrapy爬取京东上所有的手机数据 2.将爬取的数据存储到MongoDB 环境 ...
随机推荐
- django model数据 时间格式
from datetime import datetime dt = datetime.now() print '时间:(%Y-%m-%d %H:%M:%S %f): ' , dt.strftime( ...
- Python编码和Unicode
原文链接: ERIC MORITZ 翻译: 伯乐在线- 贱圣OMG译文链接: http://blog.jobbole.com/50345/ 我确定有很多关于Unicode和Python的说明,但为 ...
- DeepLab 使用 Cityscapes 数据集训练模型
原文地址:DeepLab 使用 Cityscapes 数据集训练模型 0x00 操作环境 OS: Ubuntu 16.04 LTS CPU: Intel® Core™ i7-4790K GPU: Ge ...
- Makefile.am文件配置
Makefile.am Makefile.am是一种比Makefile更高层次的编译规则,可以和configure.in文件一起通过调用automake命令,生成Makefile.in文件,再调用./ ...
- Ubuntu Docker版本的更新与安装
突然发现自己的docker版本特别的低,目前是1.9.1属于古董级别的了,想更新一下最新版本,这样最新的一下命令就可以被支持.研究了半天都没有更新成功,更新后的版本始终都是1.9.1 :查阅了官网资料 ...
- 【详解】换一个角度看Socket的数据读写
前言 以前对IO.NIO还算了解,也写过Netty的项目.但是对底层的数据传递不是很了解,一直存有这方面的疑惑.但是由于有其他事情就被打断了.前阵子因为想要了解volatile关键字的原理,学习了下J ...
- openssl speed和openssl rand
openssl系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html 1.1 openssl speed 测试加密算法的性能. 支持的算法有: o ...
- 启动设置mongodb
启动 ①:启动之前,我们要给mongodb指定一个文件夹,这里取名为”db",用来存放mongodb的数据. ②:微软徽标+R,输入cmd,首先找到“mongodb”的路径,然后运行mong ...
- 将不确定变为确定~老赵写的CodeTimer是代码性能测试的利器
首先,非常感谢赵老大的CodeTimer,它让我们更好的了解到代码执行的性能,从而可以让我们从性能的角度来考虑问题,有些东西可能我们认为是这样的,但经理测试并非如何,这正应了我之前的那名话:“机器最能 ...
- oracle创建用户、创建表空间、授权、建表
2.然后我就可以来创建用户了. create user zzg identified by zzg123; 3.创建好用户我们接着就可以修改用户的密码. alter user zzg identifi ...