Scrapy爬取遇到的一点点问题
学了大概一个月Scrapy,自己写了些东东,遇到很多问题,这几天心情也不大好,小媳妇人也不舒服,休假了,自己研究了很久,有些眉目了
利用scrapy 框架爬取慕课网的一些信息
步骤一:新建项目
scrapy startproject muke
进入muke
scrapy genspider mukewang imooc.com #mukewang 为爬虫名,imooc.com 是域名,爬虫爬取的范围
步骤二:编写ITEM,定义需要爬取的字段,此处只定义两个字段吧(初学)

步骤三:编写Spider主题,暂时先只爬取title,有些名词用的比较low,莫怪
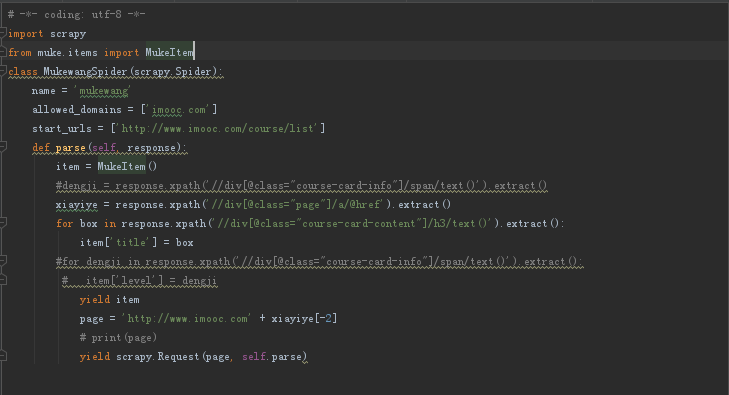
以上基本的东西就写完了
步骤四:运行爬虫 scrapy crwal mukewang 查看结果 爬取结果较多就不一一列举了
期间遇到一点点问题问题,就是我的爬取结果只限制在第一页,收到一个DEUBG信息:
原来是我的allowed_domains出现问题 将allowed_domains=['www.imooc.com/']改为allowed_domains=['imooc.com']即可实现全部爬取
本次算是初学爬虫,自己写了点东西,但是远远没有达到要求,比如储存到数据库,路漫漫其修远兮,吾将上下而求索!!
Scrapy爬取遇到的一点点问题的更多相关文章
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
- 用scrapy爬取京东的数据
本文目的是使用scrapy爬取京东上所有的手机数据,并将数据保存到MongoDB中. 一.项目介绍 主要目标 1.使用scrapy爬取京东上所有的手机数据 2.将爬取的数据存储到MongoDB 环境 ...
随机推荐
- 可以用软连接的方式解决linux内存空间不足的问题
突然提示说/var空间满了,然后接着系统卡死,最后彻底没辙,重启试试,没想到提示什么系统错误,请联系管理员之类的提示语,也进不去登陆界面啥了.之后用其他电脑连接SSH用root账号访问. # cd / ...
- salesforce零基础学习(八十九)使用 input type=file 以及RemoteAction方式上传附件
在classic环境中,salesforce提供了<apex:inputFile>标签用来实现附件的上传以及内容获取.salesforce 零基础学习(二十四)解析csv格式内容中有类似的 ...
- 从零开始学 Web 之 移动Web(五)touch事件的缺陷,移动端常用插件
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- iOS ipa包瘦身,iOS8及以下text段超60MB
前沿 很早之前写过一篇相关文章,不过博客主机上跑路了之后数据没了,凭着记忆补了下相关资料 ipa安装包瘦身 清理无用图片,图片压缩(PNG换WebP和JPG),处于某种不可抗拒的原因,导致有部分3X图 ...
- #15 time&datetime&calendar模块
前言 从这一节开始,记录一些常用的内置模块,模块的学习可能比较无聊,但基础就在这无聊的模块中,话不多说,本节记录和时间相关的模块! 一.time模块 Python中设计时间的模块有很多,但是最常用的就 ...
- 从零搭建生产环境的ghost2.0博客
当前安装过程是在ghost cli 1.9.2上的,由于ghost更新特别快,我安装我个人博客cmlanche.com的时候还是1.9.1,当时没碰到啥问题,到1.9.2就有一点点不一样了,所以要注意 ...
- ZooKeeper 分布式锁
在Redis分布式锁一文中, 作者介绍了如何使用Redis开发分布式锁. Redis分布式锁具有轻量高吞吐量的特点,但是一致性保证较弱.我们可以使用Zookeeper开发分布式锁,来满足对高一致性的要 ...
- Aspose.Cells API 中文版文档 下载
链接: https://pan.baidu.com/s/19foJyWgPYvA7eIqEHJ_IdA 密码: yxun
- 初学HTML-10
marquee标签:设置文字滚动效果. 格式:<marquee>文字滚动</marquee> 属性:direction:设置滚动方向:left / right / up / d ...
- 网络安全之sql注入
1.何为Sql注入? 所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令.具体来说,它是利用现有应用程序,将(恶意的)SQ ...