solr - 安装ik中文分词 和初始化富文本检索
1.下载安装包
https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler/7.4.0/solr-dataimporthandler-7.4.0.jar https://repo1.maven.org/maven2/org/apache/tika/tika-app/1.19.1/tika-app-1.19.1.jar https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler-extras/7.4.0/solr-dataimporthandler-extras-7.4.0.jar
ik分词器 ,我放在git 了
https://github.com/cen-xi/netty-tcp-spring-boot/tree/0458cb5626dcde976270b5351d67e96b162356d0/src/main/resources
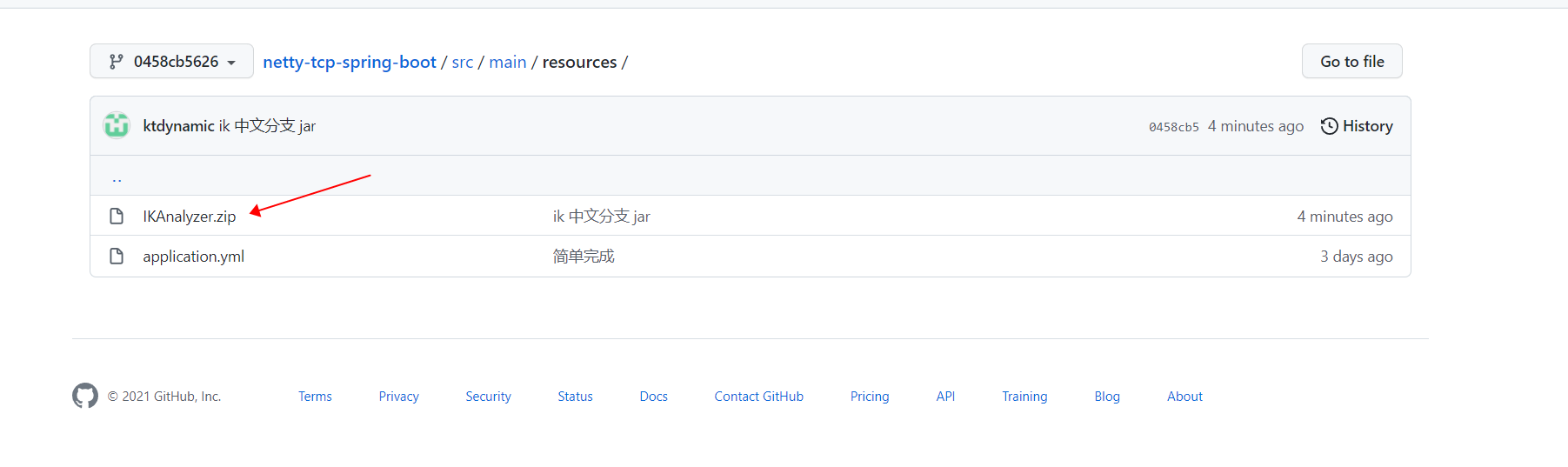
一共四个包,
把ik 的jar放到 E:\plug\solr\solr-7.7.3\server\solr-webapp\webapp\WEB-INF\lib 里面
其他的放到 E:\plug\solr\solr-7.7.3\contrib\extraction\lib
在 E:\plug\solr\solr-7.7.3\server\solr-webapp\webapp\WEB-INF 新建 classes 文件夹
然后在里面新建 IKAnalyzer.cfg.xml ,
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">hotword.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
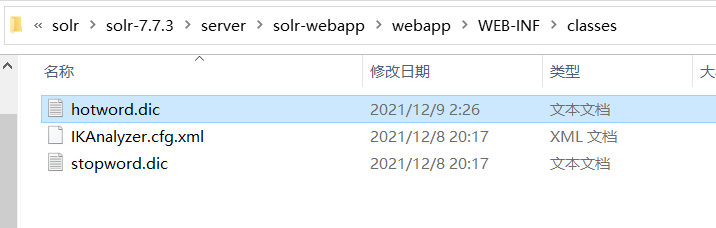
剩下的两个 hotword.dic 和 stopword.dic ,用sublime来创建 ,格式为 utf8且无bom的 ,否则不生效
更改hotword.dic 和 stopword.dic 后需要重启solr才生效
2.如果需要加载数据源 ,用在添加富文本检索数据 【代码里一般是在上传文件时就用tk来抽取检索内容然后存入solr的 ,这样用来初始化solr的检索文件的 ,比如数据丢失 ,一般将备份检索数据存在mysql里,启动时初始化检索数据】
需要在 进入创建的 core 里 ,E:\plug\solr\solr-7.7.3\server\solr\mycore1\conf 找到 solrconfig.xml
添加
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">tika-data-config.xml</str>
</lst>
</requestHandler>

在同级目录添加 tika-data-config.xml 文件
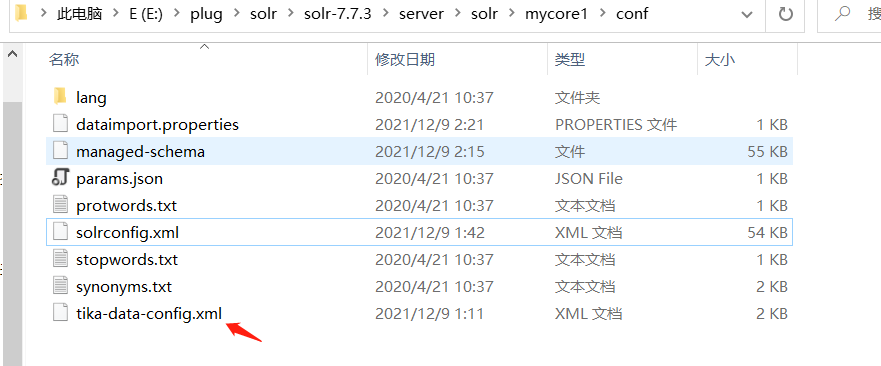
内容为
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="BinFileDataSource"/>
<document>
<entity name="file" processor="FileListEntityProcessor" dataSource="null"
baseDir="E:/plug/solr/testfile/" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)"
rootEntity="false">
<field column="file" name="id"/>
<field column="fileSize" name="fileSize"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileAbsolutePath" name="fileAbsolutePath"/>
<entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text">
<field column="Author" name="author" meta="true"/>
<!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased -->
<field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
E:/plug/solr/testfile/ 是存放文件的目录
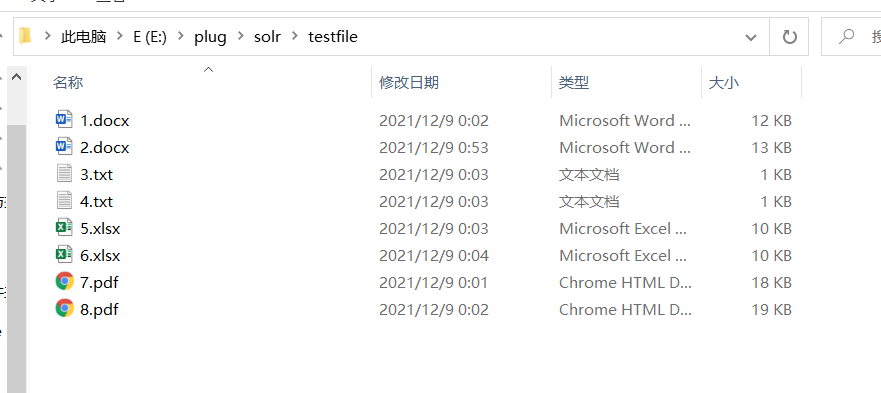
E:\plug\solr\solr-7.7.3\server\solr\mycore1\conf 找到 managed-schema
添加类型和字段 ,字段时根据需要来添加 ,但是 <fieldType name ="text_ik" class ="solr.TextField"> 则必须要有
<!-- ik-chinese-config , omitNorms ="true" , text_auto_phrase-->
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="pdf" type="text_ik" indexed="true" stored="true"/>
<field name="mytab666" type="text_ik" indexed="true" stored="true"/>
<field name="text" type="text_ik" indexed="true" stored="true" />
<field name="author" type="text_ik" indexed="true" stored="true"/>
<field name="fileSize" type="plong" indexed="true" stored="true"/>
<field name="fileLastModified" type="pdate" indexed="true" stored="true"/>
<field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer type ="index" isMaxWordLength ="false" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type ="query" isMaxWordLength ="true" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
保存后,在 http://localhost:8983/solr/ 控制面板 的 core admin找到 这个code 然后点击 reload , 否则不生效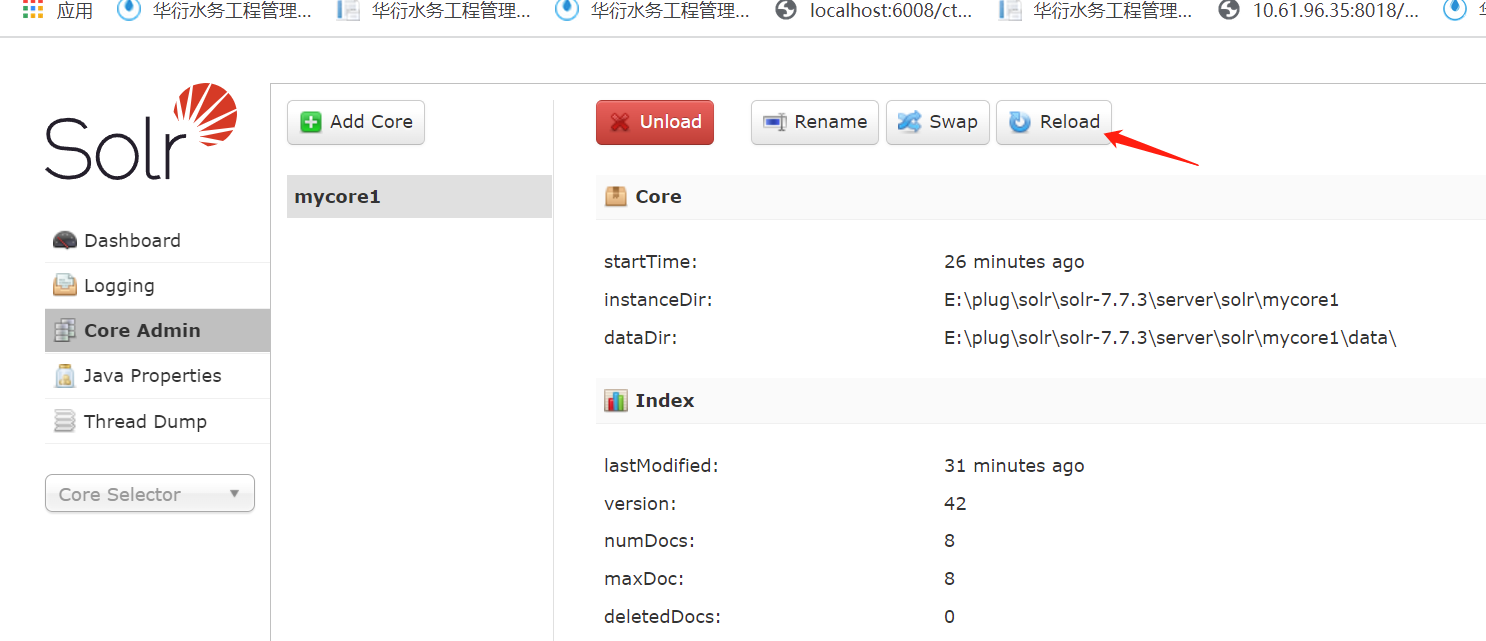
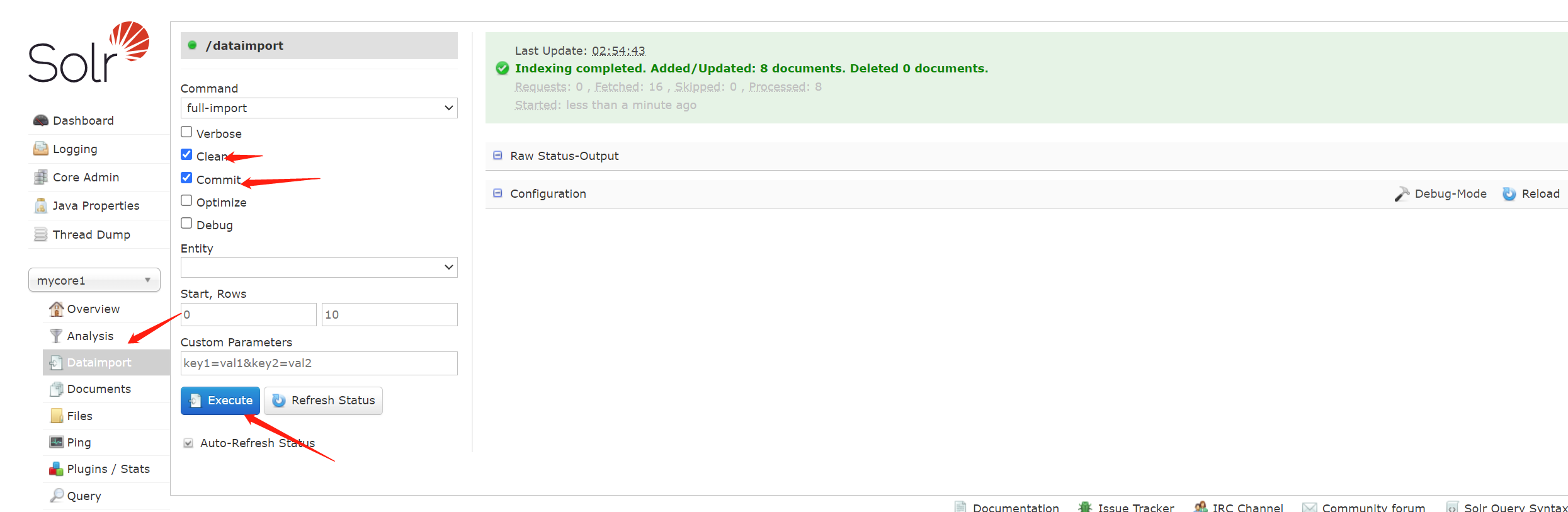
数据源配置完了,找到 Dataimport ,执行数据源的导入操作 ,否则不更新检索数据
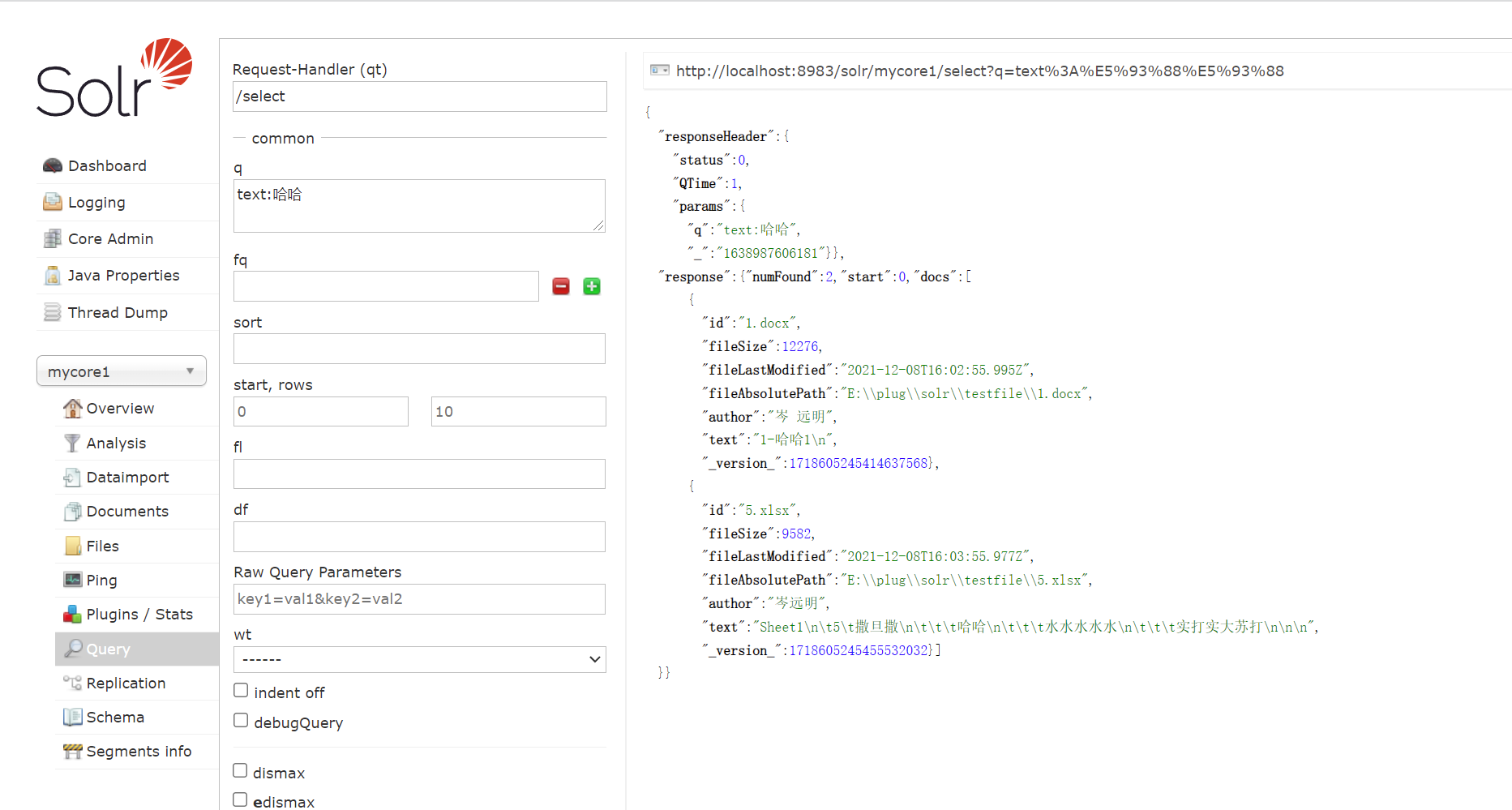
测试

solr - 安装ik中文分词 和初始化富文本检索的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- es5.0 安装ik中文分词器 mac
es5.0集成ik中文分词器,网上资料很多,但是讲的有点乱,有的方法甚至不能正常运行此插件 特别注意的而是,es的版本一定要和ik插件的版本相对应: 1,下载ik 插件: https://github ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- solr配置ik中文分词(二)
上一篇文章主要介绍了solr的安装与配置,这篇文章主要记录如何使用ik分词器对中文进行分词. 步骤: 1.下载ik分词jar包:ik-analyzer-solr5-5.x.jar. 2.将下载的jar ...
- es(elasticsearch)安装IK中文分词器
IK压缩包下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.7.0,需要下载对应的版本 我也上传了 h ...
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- elasticsearch 安装ik中文分词
https://blog.csdn.net/c5113620/article/details/79339541
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- 30.IK中文分词器的安装和简单使用
在之前我们学的都是英文,用的也是英文的standard分词器.从这一节开始,学习中文分词器.中国人基本上都是中文应用,很少是英文的,而standard分词器是没有办法对中文进行合理分词的,只是将每个中 ...
随机推荐
- 修改页面.JSP
<%@ page contentType="text/html;charset=UTF-8" language="java" %><%@tag ...
- jQuery节点更新
一.插入子节点 var $newNode1 = $("<p>我是p标签</p>"); 加入之后,原来的会删除. 二.插入兄弟节点 三.替换节点 1.HTML ...
- PHP之CURL实现含有验证码的模拟登录
博主最近在为学校社团写一个模拟登录教务系统来进行成绩查询的功能,语言当然是使用PHP啦,原理是通过php数据传输神器---curl扩展,向学校教务系统发送请求,通过模拟登录,获取指定url下的内容. ...
- C#生成pdf -- iText7 设置自定义字体和表格
itextsharp已经不再更新,由iText 7来替代 安装 nuget 安装 itext7 注册自定义字体 下载字体文件 .ttc或.ttf到项目目录,设置更新则拷贝到输出目录,这样构建的时候会把 ...
- Mysql资料 查询SQL执行顺序
目录 一.Mysql数据库查询Sql的执行顺序是什么? 二.具体顺序 一.Mysql数据库查询Sql的执行顺序是什么? (9)SELECT (10) DISTINCT column, (6)AGG_F ...
- Azure Virtual Netwok(二)配置 ExpressRoute 虚拟网络网关
一,引言 我们可以使用 ExpressRoute 可通过连接服务提供商所提供的专用连接,将本地网络扩展到 Microsoft Cloud,实现了网络的混合连接.使用 ExpressRoute 可与 M ...
- 使用.NET 6开发TodoList应用(4)——引入数据存储
需求 作为后端CRUD程序员(bushi,数据存储是开发后端服务一个非常重要的组件.对我们的TodoList项目来说,自然也需要配置数据存储.目前的需求很简单: 需要能持久化TodoList对象并对其 ...
- 面试官:HashSet如何保证元素不重复?
本文已收录<Java常见面试题>系列,Git 开源地址:https://gitee.com/mydb/interview HashSet 实现了 Set 接口,由哈希表(实际是 HashM ...
- odoo views中html的奇怪问题
在我创建了字段类型为 fields.Html 以后,确出现了两种不同的情况 下图中,content是此类型的,可以正常显示不需要加widget(小部件)="html" <fo ...
- birt分组时,如何让居中
birt分组时,如何让居中,如下图,选择cell格,然后调整属性为all,如下图所示,