es(elasticsearch)安装IK中文分词器
IK压缩包下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.7.0,需要下载对应的版本

我也上传了
https://yvioo.lanzous.com/iaztq3i

2、下载完成之后,上传到服务器,然后解压到elasticsearch的plugins文件夹下,然后重命名为analysis-ik
也可以先在别处解压之后,然后重命名,以下代码,每个人可能不一样,根据自己实际的来
mv elasticsearch-analysis-ik-6.6.2 elasticsearch-6.6.0/plugins/analysis-ik
在这里要注意层级,以下这个IKAnalyzer.cfg.xml文件和plugins文件夹的层级是这样的
/plugins/analysis-ik/config/IKAnalyzer.cfg.xml
然后关闭elasticsearch
[root@localhost config]# ps -ef|grep elast
elas+ 49202 1 1 18:10 pts/1 00:00:23 /usr/web/java/jdk1.8/bin/java -Xms256m -Xmx256m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.io.tmpdir=/tmp/elasticsearch-628240789535257481 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:ErrorFile=logs/hs_err_pid%p.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:logs/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=32 -XX:GCLogFileSize=64m -Des.path.home=/usr/web/elasticsearch/elasticsearch-6.6.0 -Des.path.conf=/usr/web/elasticsearch/elasticsearch-6.6.0/config -Des.distribution.flavor=default -Des.distribution.type=tar -cp /usr/web/elasticsearch/elasticsearch-6.6.0/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
hoi+ 49216 49202 0 18:10 pts/1 00:00:00 /usr/web/elasticsearch/elasticsearch-6.6.0/modules/x-pack-ml/platform/linux-x86_64/bin/controller
root 49738 3679 0 18:37 pts/0 00:00:00 grep --color=auto elast
然后杀掉进程
kill 49202
然后切换到普通账号(使用root账号启动会失败)重新启动,进入elasticsearch文件目录的bin文件夹下
./elasticsearch
或者后台启动
nohup ./elasticsearch &
如果出现以下报错
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalArgumentException: Plugin [analysis-ik] was built for Elasticsearch version 6.5.0 but version 6.6.0 is running
问题原因
elasticsearch版本和 ik分词器版本不一致。
由于我用的elasticsearch时最新版本 6.6.0,而ik分词器master编译出来的是6.5.0
解决办法
进入插件目录的分词文件夹下 analysis-ik/ ,修改 plugin-descriptor.properties 文件中的
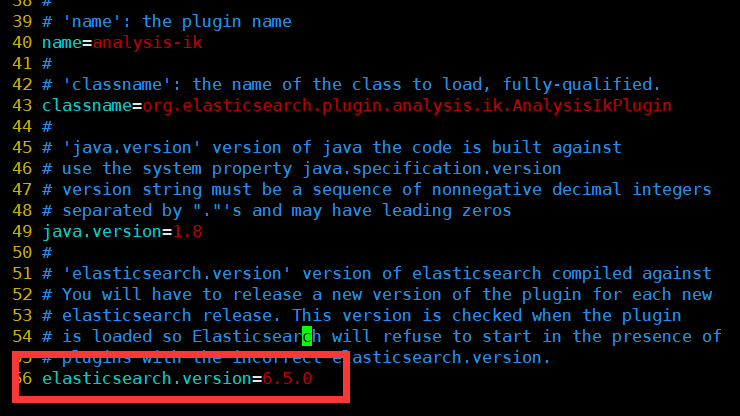
改为你的elasticsearch版本号,我的是6.6.0

然后保存退出 使用非root用户重启

IK提供了两个分词算法ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
es(elasticsearch)安装IK中文分词器的更多相关文章
- elasticsearch使用ik中文分词器
elasticsearch使用ik中文分词器 一.背景 二.安装 ik 分词器 1.从 github 上找到和本次 es 版本匹配上的 分词器 2.使用 es 自带的插件管理 elasticsearc ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- Elasticsearch:IK中文分词器
Elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,比如: POST /_analyze { "text": "我爱北京天安门&quo ...
- es5.0 安装ik中文分词器 mac
es5.0集成ik中文分词器,网上资料很多,但是讲的有点乱,有的方法甚至不能正常运行此插件 特别注意的而是,es的版本一定要和ik插件的版本相对应: 1,下载ik 插件: https://github ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- elasticsearch 安装ik中文分词
https://blog.csdn.net/c5113620/article/details/79339541
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- 30.IK中文分词器的安装和简单使用
在之前我们学的都是英文,用的也是英文的standard分词器.从这一节开始,学习中文分词器.中国人基本上都是中文应用,很少是英文的,而standard分词器是没有办法对中文进行合理分词的,只是将每个中 ...
- ES[7.6.x]学习笔记(七)IK中文分词器
在上一节中,我们给大家介绍了ES的分析器,我相信大家对ES的全文搜索已经有了深刻的印象.分析器包含3个部分:字符过滤器.分词器.分词过滤器.在上一节的例子,大家发现了,都是英文的例子,是吧?因为ES是 ...
随机推荐
- [省选联考 2020 A 卷] 组合数问题
题意 [省选联考 2020 A 卷] 组合数问题 想法 自己在多项式和数论方面还是太差了,最近写这些题都没多少思路,看完题解才会 首先有这两个柿子 \(k*\dbinom{n}{k} = n*\dbi ...
- Codeforces 889E - Mod Mod Mod(dp+状态设计)
Codeforces 题目传送门 & 洛谷题目传送门 题目名称 hopping 我们记 \(x_i=X\bmod a_1\bmod a_2\bmod\dots\bmod a_i\),也就是 \ ...
- ceph简单了解
ceph简介 ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能.可靠性和可扩展性. 目前已经得到众多云计算厂商的支持并被广泛应用.RedHat及OpenStack都可以与Ceph整合以支持 ...
- Python序列化,json&pickle&shelve模块
1. 序列化说明 序列化可将非字符串的数据类型的数据进行存档,如字典.列表甚至是函数等等 反序列化,将通过序列化保存的文件内容反序列化即可得到数据原本的样子,可直接使用 2. Python中常用的序列 ...
- 使用input+datalist简单实现实时匹配的可编辑下拉列表-并解决选定后浏览器默认只显示value的可读性问题
问题背景 最近小伙伴提了一个希望提高后台下拉列表可操作性的需求,原因是下拉列表选项过多,每次下拉选择比较费时费力且容易出错,硬着头皮啃了啃前端知识,网上搜寻了一些下拉列表实现的资料,这里总结一下. P ...
- accent, accept
accent A colon (:) is used to represent a long vowel, e.g. sheet /ʃiːt/ and shit /ʃit/. The word bed ...
- Kafka(一)【概述、入门、架构原理】
目录 一.Kafka概述 1.1 定义 二.Kafka快速入门 2.1 安装部署 2.2 配置文件解析 2.3Kafka群起脚本 2.4 topic(增删改查) 2.5 生产和消费者命令行操作 三.K ...
- redis 之 集群
#:下载源码包,并编译安装 [root@localhost src]# wget http://download.redis.io/releases/redis-4.0.14.tar.gz [root ...
- js 长按鼠标左键实现溢出内容左右滚动滚动
var nextPress, prevPress; // 鼠标按下执行定时器,每0.1秒向左移一个li内容的宽度 function nextDown() { nextPress = setInterv ...
- java使用在线api实例
字符串 strUrl为访问地址和参数 public String loadAddrsApi() { StringBuffer sb; String strUrl = "https://api ...