solr - 安装ik中文分词 和初始化富文本检索
1.下载安装包
https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler/7.4.0/solr-dataimporthandler-7.4.0.jar https://repo1.maven.org/maven2/org/apache/tika/tika-app/1.19.1/tika-app-1.19.1.jar https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler-extras/7.4.0/solr-dataimporthandler-extras-7.4.0.jar
ik分词器 ,我放在git 了
https://github.com/cen-xi/netty-tcp-spring-boot/tree/0458cb5626dcde976270b5351d67e96b162356d0/src/main/resources
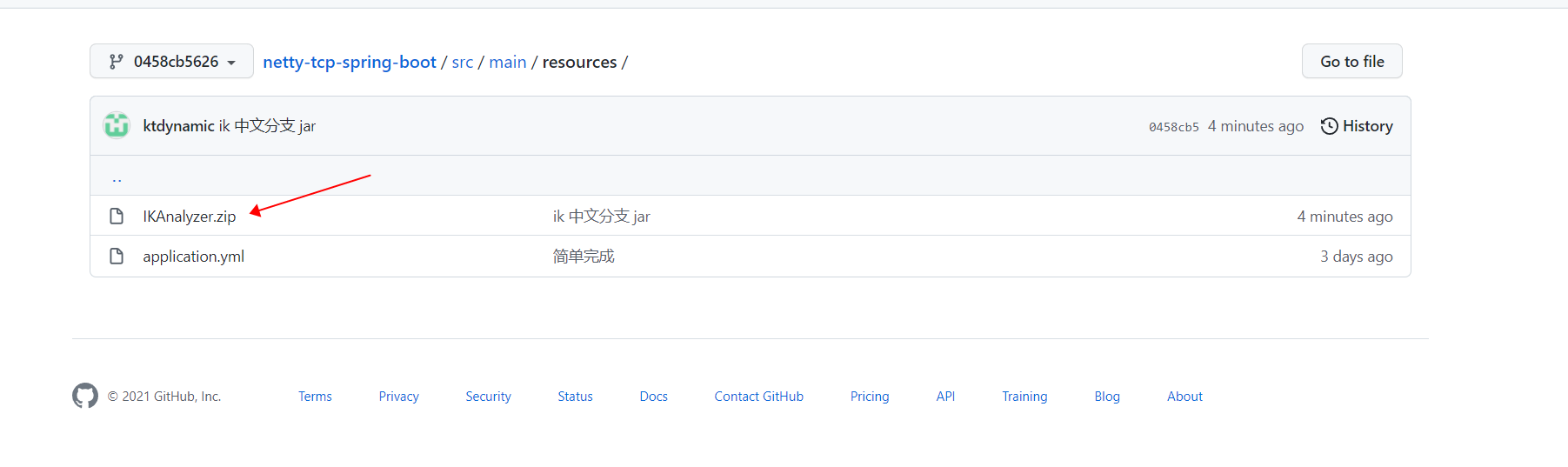
一共四个包,
把ik 的jar放到 E:\plug\solr\solr-7.7.3\server\solr-webapp\webapp\WEB-INF\lib 里面
其他的放到 E:\plug\solr\solr-7.7.3\contrib\extraction\lib
在 E:\plug\solr\solr-7.7.3\server\solr-webapp\webapp\WEB-INF 新建 classes 文件夹
然后在里面新建 IKAnalyzer.cfg.xml ,
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">hotword.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
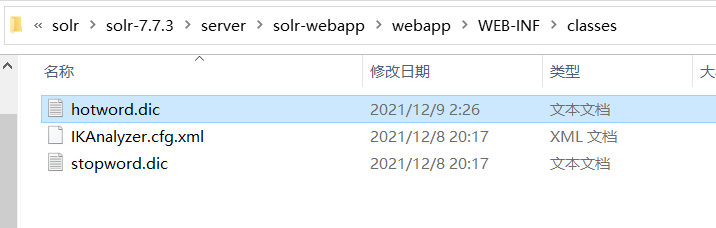
剩下的两个 hotword.dic 和 stopword.dic ,用sublime来创建 ,格式为 utf8且无bom的 ,否则不生效
更改hotword.dic 和 stopword.dic 后需要重启solr才生效
2.如果需要加载数据源 ,用在添加富文本检索数据 【代码里一般是在上传文件时就用tk来抽取检索内容然后存入solr的 ,这样用来初始化solr的检索文件的 ,比如数据丢失 ,一般将备份检索数据存在mysql里,启动时初始化检索数据】
需要在 进入创建的 core 里 ,E:\plug\solr\solr-7.7.3\server\solr\mycore1\conf 找到 solrconfig.xml
添加
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">tika-data-config.xml</str>
</lst>
</requestHandler>

在同级目录添加 tika-data-config.xml 文件
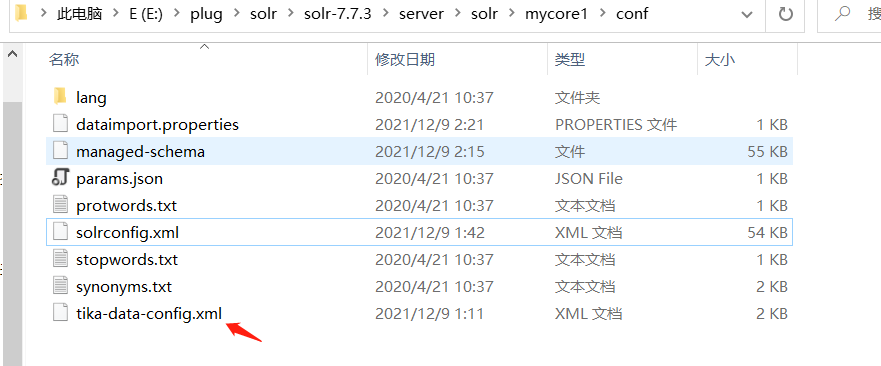
内容为
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="BinFileDataSource"/>
<document>
<entity name="file" processor="FileListEntityProcessor" dataSource="null"
baseDir="E:/plug/solr/testfile/" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)"
rootEntity="false">
<field column="file" name="id"/>
<field column="fileSize" name="fileSize"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileAbsolutePath" name="fileAbsolutePath"/>
<entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text">
<field column="Author" name="author" meta="true"/>
<!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased -->
<field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
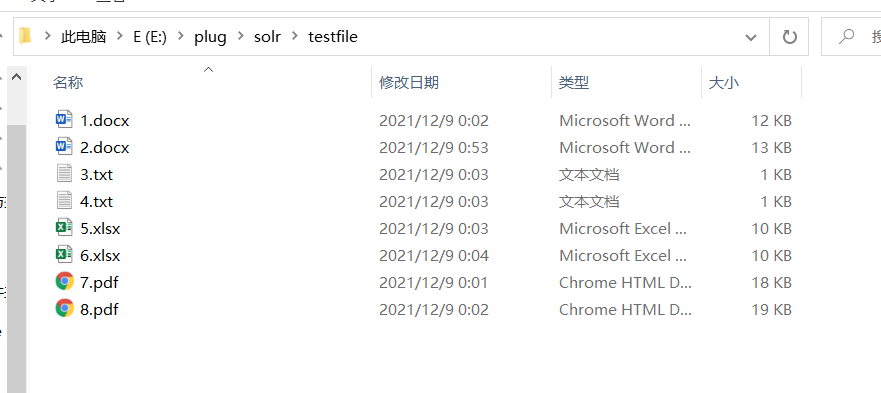
E:/plug/solr/testfile/ 是存放文件的目录
E:\plug\solr\solr-7.7.3\server\solr\mycore1\conf 找到 managed-schema
添加类型和字段 ,字段时根据需要来添加 ,但是 <fieldType name ="text_ik" class ="solr.TextField"> 则必须要有
<!-- ik-chinese-config , omitNorms ="true" , text_auto_phrase-->
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="pdf" type="text_ik" indexed="true" stored="true"/>
<field name="mytab666" type="text_ik" indexed="true" stored="true"/>
<field name="text" type="text_ik" indexed="true" stored="true" />
<field name="author" type="text_ik" indexed="true" stored="true"/>
<field name="fileSize" type="plong" indexed="true" stored="true"/>
<field name="fileLastModified" type="pdate" indexed="true" stored="true"/>
<field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
<fieldType name ="text_ik" class ="solr.TextField">
<analyzer type ="index" isMaxWordLength ="false" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type ="query" isMaxWordLength ="true" class ="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
保存后,在 http://localhost:8983/solr/ 控制面板 的 core admin找到 这个code 然后点击 reload , 否则不生效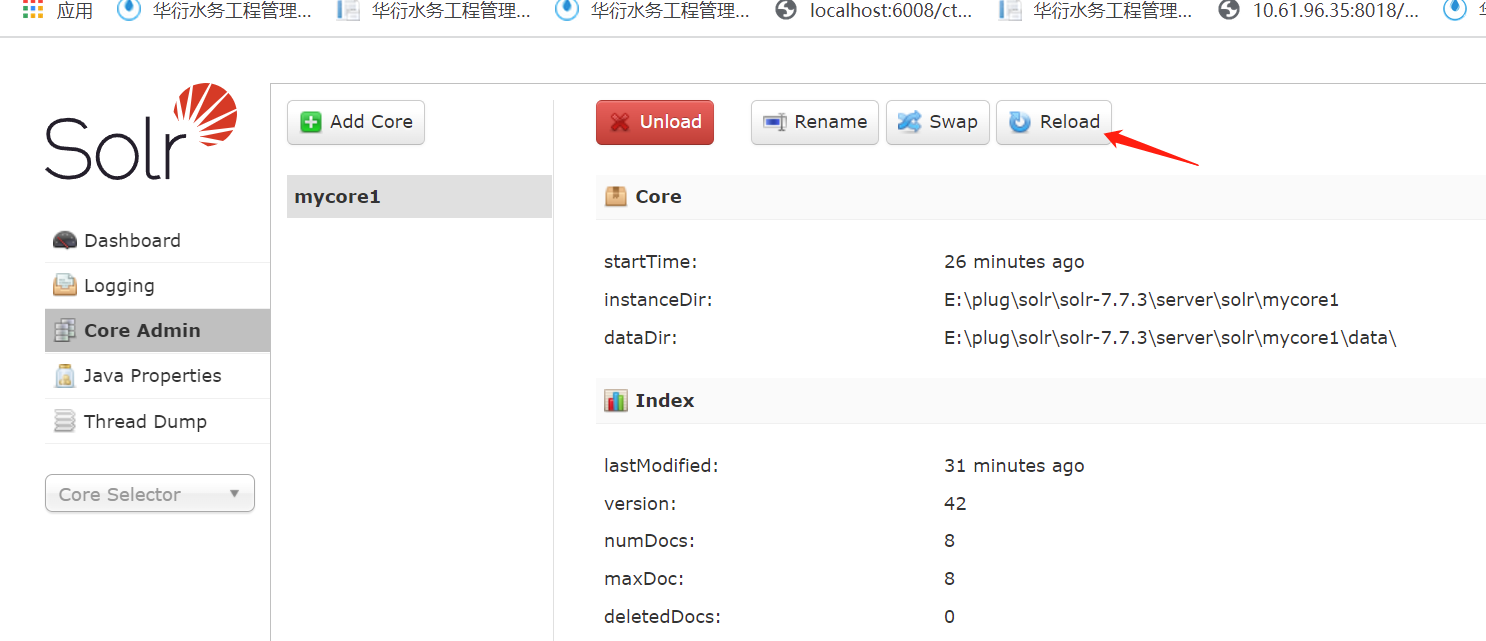
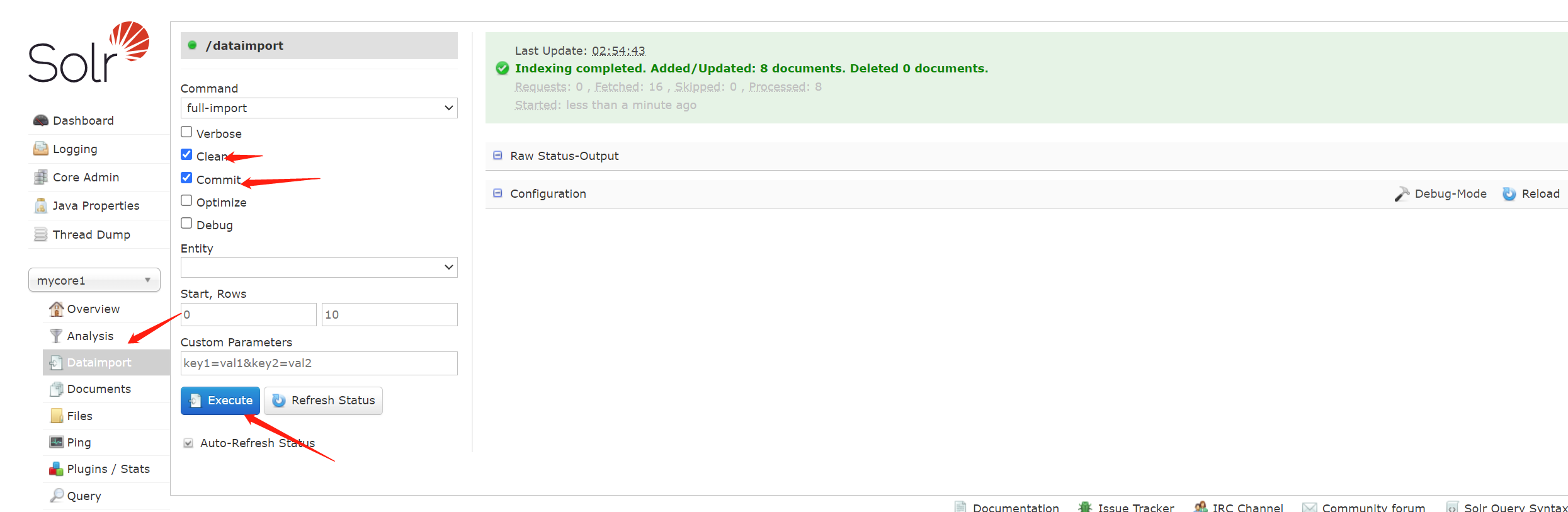
数据源配置完了,找到 Dataimport ,执行数据源的导入操作 ,否则不更新检索数据
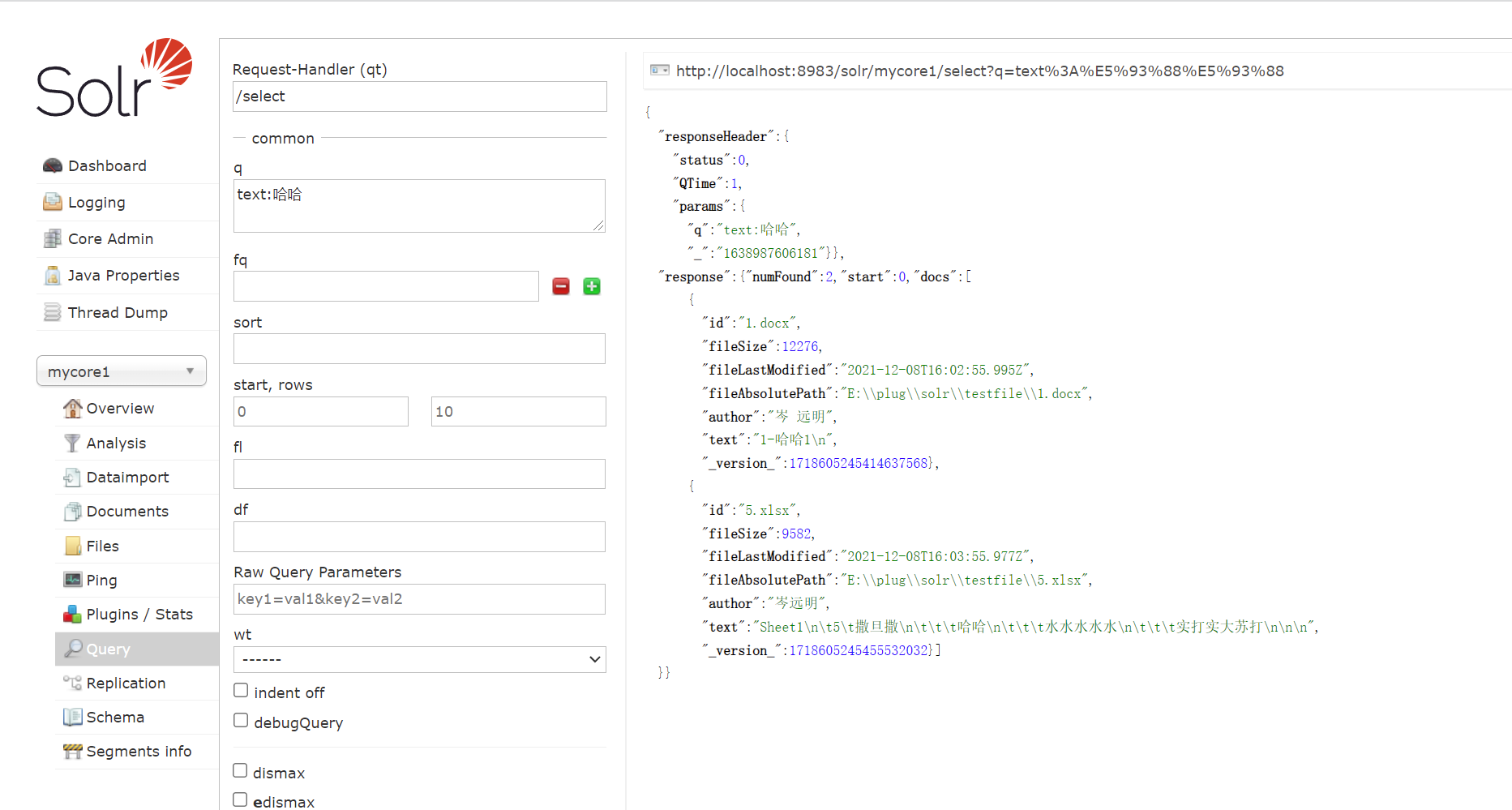
测试

solr - 安装ik中文分词 和初始化富文本检索的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- es5.0 安装ik中文分词器 mac
es5.0集成ik中文分词器,网上资料很多,但是讲的有点乱,有的方法甚至不能正常运行此插件 特别注意的而是,es的版本一定要和ik插件的版本相对应: 1,下载ik 插件: https://github ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- solr配置ik中文分词(二)
上一篇文章主要介绍了solr的安装与配置,这篇文章主要记录如何使用ik分词器对中文进行分词. 步骤: 1.下载ik分词jar包:ik-analyzer-solr5-5.x.jar. 2.将下载的jar ...
- es(elasticsearch)安装IK中文分词器
IK压缩包下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.7.0,需要下载对应的版本 我也上传了 h ...
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- elasticsearch 安装ik中文分词
https://blog.csdn.net/c5113620/article/details/79339541
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- 30.IK中文分词器的安装和简单使用
在之前我们学的都是英文,用的也是英文的standard分词器.从这一节开始,学习中文分词器.中国人基本上都是中文应用,很少是英文的,而standard分词器是没有办法对中文进行合理分词的,只是将每个中 ...
随机推荐
- 【Java 与数据库】How to Timeout JDBC Queries
How to Timeout JDBC Queries JDBC queries by default do not have any timeout, which means that a quer ...
- jdk1.8帮助文档中文可搜索
jdk1.8帮助文档中文可搜索 链接:https://pan.baidu.com/s/11beeZLpEIhciOd14WkCpdg 提取码:t4lw
- 06 - Vue3 UI Framework - Dialog 组件
做完按钮之后,我们应该了解了遮罩层的概念,接下来我们来做 Dialog 组件! 返回阅读列表点击 这里 需求分析 默认是不可见的,在用户触发某个动作后变为可见 自带白板卡片,分为上中下三个区域,分别放 ...
- 编译工具grdle部署
目录 一.简介 二.部署 三.测试 一.简介 Gradle 是以 Groovy 语言为基础,面向Java应用为主.基于DSL(领域特定语言)语法的自动化构建工具.在github上,gradle项目很多 ...
- SpringBoot Redis 发布订阅模式 Pub/Sub
SpringBoot Redis 发布订阅模式 Pub/Sub 注意:redis的发布订阅模式不可以将消息进行持久化,订阅者发生网络断开.宕机等可能导致错过消息. Redis命令行下使用发布订阅 pu ...
- 判断存在…Contains…(Power Query 之 M 语言)
表函数 判断记录在表中是否存在 = Table.Contains( 表, 记录, {"指定列1",-, "指定列n"}) = Table.ContainsAll ...
- LuoguP7679 [COCI2008-2009#5] JABUKA 题解
Content Mirko 拥有 \(R\) 个红苹果和 \(G\) 个绿苹果,他想把他分给若干个朋友,使得所有朋友分得的红苹果个数和绿苹果个数都一样.现给定 \(R,G\),请你帮助 Mirko 找 ...
- LuoguP7008 [CERC2013]What does the fox say? 题解
Content 森林里面有很多声响,你想知道有哪些声响是由狐狸发出来的. 已知你搜集到了 \(n\) 个声响,并且还知道某些其他动物能够发出的声响,已知如果没有哪一个声响是由其他任何一种动物发出来的话 ...
- libevent源码学习(11):超时管理之min_heap
目录min_heap的定义向min_heap中添加eventmin_heap中event的激活以下源码均基于libevent-2.0.21-stable. 在前文中,分析了小顶堆min_h ...
- SQL优化一例:通过改变分组条件(减少计算次数)来提高效率
#与各人授权日期相关,所以有十万用户,就有十万次查询(相关子查询) @Run.ExecuteSql("更新各人应听正课数",@"update bi_data.study_ ...