spark相关介绍-提取hive表(一)
本文环境说明
centos服务器
jupyter的scala核spylon-kernel
spark-2.4.0
scala-2.11.12
hadoop-2.6.0
本文主要内容
- spark读取hive表的数据,主要包括直接sql读取hive表;通过hdfs文件读取hive表,以及hive分区表的读取。
- 通过jupyter上的cell来初始化sparksession。
- 文末还有通过spark提取hdfs文件的完整示例
jupyter配置文件
- 我们可以在jupyter的cell框里面,对spark的session做出对应的初始化,具体可以见下面的示例。
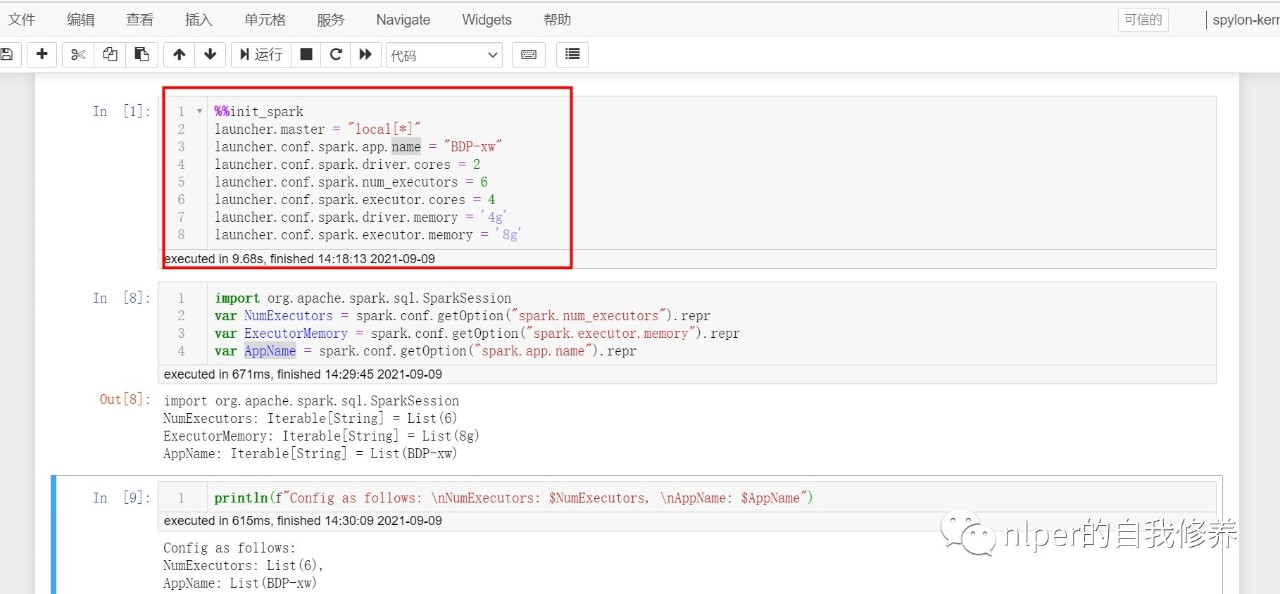
%%init_spark
launcher.master = "local[*]"
launcher.conf.spark.app.name = "BDP-xw"
launcher.conf.spark.driver.cores = 2
launcher.conf.spark.num_executors = 3
launcher.conf.spark.executor.cores = 4
launcher.conf.spark.driver.memory = '4g'
launcher.conf.spark.executor.memory = '4g'
// launcher.conf.spark.serializer = "org.apache.spark.serializer.KryoSerializer"
// launcher.conf.spark.kryoserializer.buffer.max = '4g'
import org.apache.spark.sql.SparkSession
var NumExecutors = spark.conf.getOption("spark.num_executors").repr
var ExecutorMemory = spark.conf.getOption("spark.executor.memory").repr
var AppName = spark.conf.getOption("spark.app.name").repr
var max_buffer = spark.conf.getOption("spark.kryoserializer.buffer.max").repr
println(f"Config as follows: \nNumExecutors: $NumExecutors, \nAppName: $AppName,\nmax_buffer:$max_buffer")
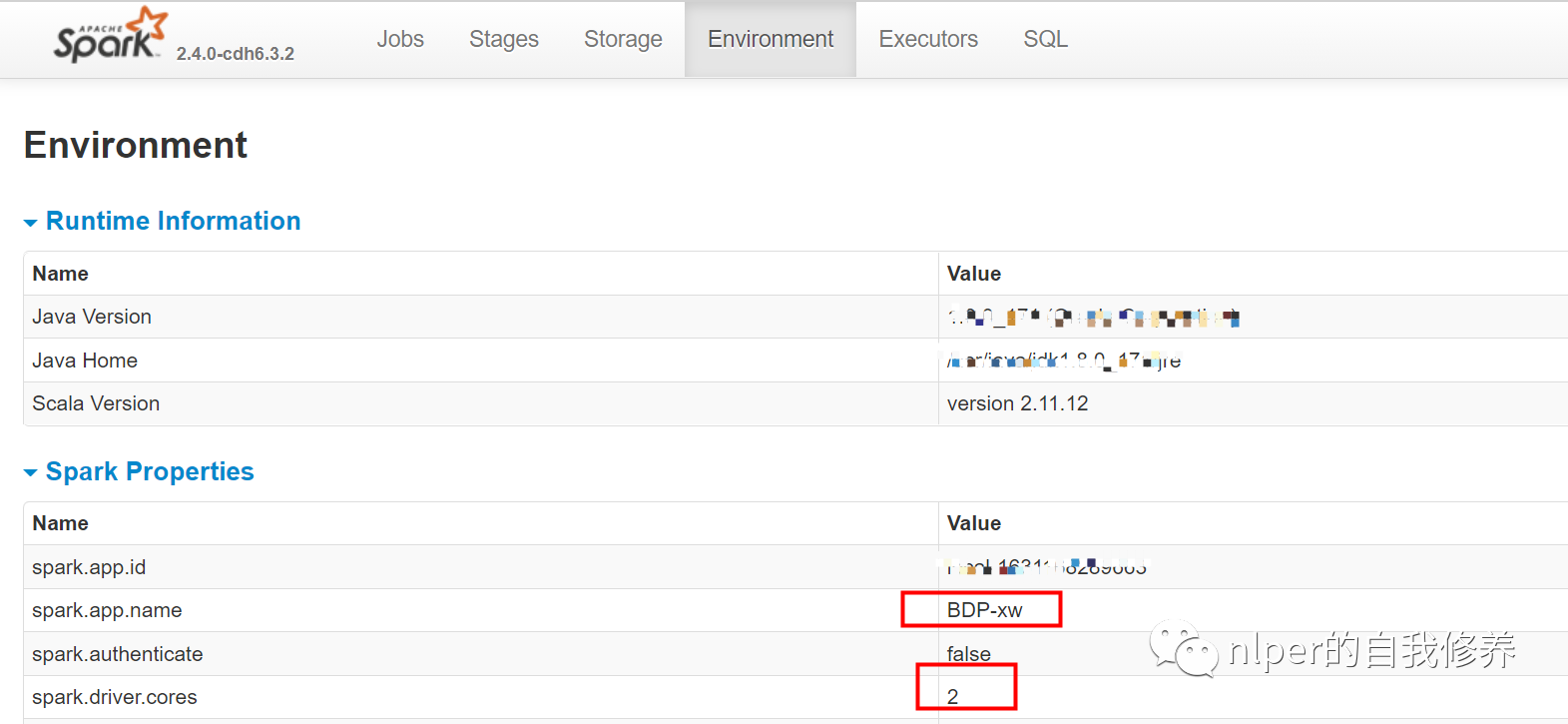
- 直接查看我们初始化的sparksession对应的环境各变量
从hive中取数
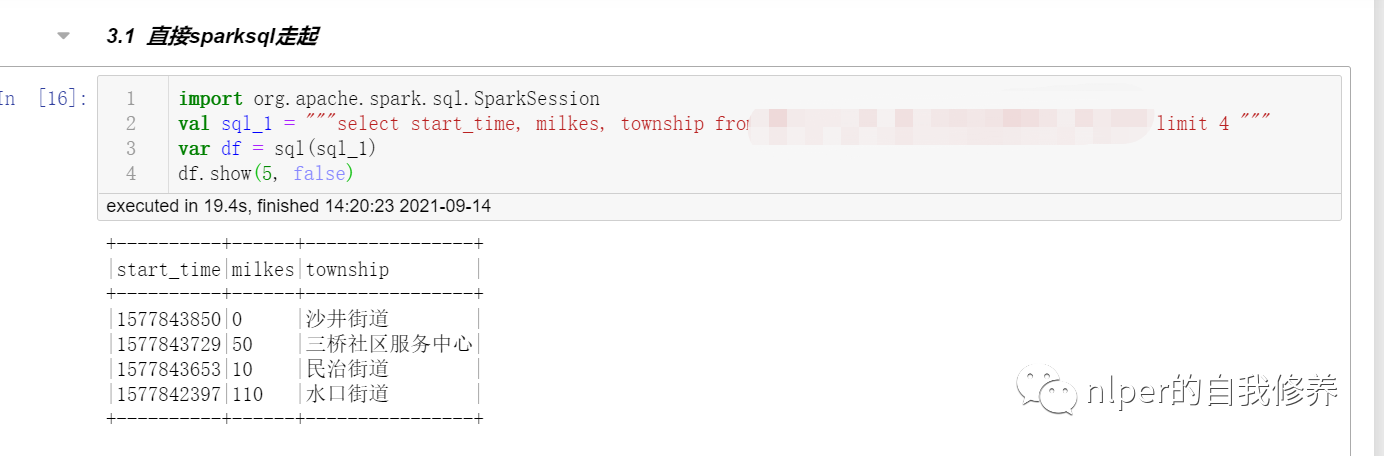
直接sparksql走起
import org.apache.spark.sql.SparkSession
val sql_1 = """select * from tbs limit 4 """
var df = sql(sql_1)
df.show(5, false)
通过hdfs取数
- 具体示例可以参考文末的从hdfs取数完整脚本示例
object LoadingData_from_hdfs_base extends mylog{// with Logging
...
def main(args: Array[String]=Array("tb1", "3", "\001", "cols", "")): Unit = {
if (args.length < 2) {
println("Usage: LoadingData_from_hdfs <tb_name, parts. sep_line, cols, paths>")
System.err.println("Usage: LoadingData_from_hdfs <tb_name, parts, sep_line, cols, paths>")
System.exit(1)
}
log.warn("开始啦调度")
val tb_name = args(0)
val parts = args(1)
val sep_line = args(2)
val select_col = args(3)
val save_paths = args(4)
val select_cols = select_col.split("#").toSeq
log.warn(s"Loading cols are : \n $select_cols")
val gb_sql = s"DESCRIBE FORMATTED ${tb_name}"
val gb_desc = sql(gb_sql)
val hdfs_address = gb_desc.filter($"col_name".contains("Location")).take(1)(0).getString(1)
val hdfs_address_cha = s"$hdfs_address/*/"
val Cs = new DataProcess_base(spark)
val tb_desc = Cs.get_table_desc(tb_name)
val raw_data = Cs.get_hdfs_data(hdfs_address)
val len1 = raw_data.map(item => item.split(sep_line)).first.length
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val rawRDD = raw_data.map(_.split(sep_line).map(_.toString)).map(p => Row(p: _*)).filter(_.length == len1)
val df_data = spark.createDataFrame(rawRDD, schema1)//.filter("custommsgtype = '1'")
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100)
df_gb_result.show(5, false)
...
// spark.stop()
}
}
val cols = "area_name#city_name#province_name"
val tb_name = "tb1"
val sep_line = "\u0001"
// 执行脚本
LoadingData_from_hdfs_base.main(Array(tb_name, "4", sep_line, cols, ""))
)
判断路径是否为文件夹
- 方式1
def pathIsExist(spark: SparkSession, path: String): Boolean = {
val filePath = new org.apache.hadoop.fs.Path( path )
val fileSystem = filePath.getFileSystem( spark.sparkContext.hadoopConfiguration )
fileSystem.exists( filePath )
}
pathIsExist(spark, hdfs_address)
// 得到结果如下:
// pathIsExist: (spark: org.apache.spark.sql.SparkSession, path: String)Boolean
// res4: Boolean = true
- 方式2
import java.io.File
val d = new File("/usr/local/xw")
d.isDirectory
// 得到结果如下:
// d: java.io.File = /usr/local/xw
// res3: Boolean = true
分区表读取源数据
- 对分区文件需要注意下,需要保证原始的hdfs上的raw文件里面是否有对应的分区字段值
- 如果分区字段在hdfs中的原始文件中,则可以直接通过通过hdfs取数
- 若原始文件中,不包括分区字段信息,则需要按照以下方式取数啦
- 具体示例可以参考文末的从hdfs取数完整脚本示例
单个文件读取
object LoadingData_from_hdfs_onefile_with_path extends mylog{
def main(args: Array[String]=Array("tb_name", "hdfs:/", "3","\n", "\001", "cols", "")): Unit = {
...
val hdfs_address = args(1)
val len1 = raw_data.map(item => item.split(sep_line)).first.length
val rawRDD = raw_data.flatMap(line => line.split(sep_text)).map(word => (word.split(sep_line):+hdfs_address)).map(p => Row(p: _*))
println(rawRDD.take(2))
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
import org.apache.spark.sql.types.StructType
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val new_schema1 = schema1.add(StructField("path", StringType))
val df_data = spark.createDataFrame(rawRDD, new_schema1)
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
// df_desc.show(false)
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100)
df_gb_result.show(5, false)
...
// spark.stop()
}
}
val file1 = "hdfs:file1.csv"
val tb_name = "tb_name"
val sep_text = "\n"
val sep_line = "\001"
val cols = "city#province#etl_date#path"
// 执行脚本
LoadingData_from_hdfs_onefile_with_path.main(Array(tb_name, file1, "4", sep_line, sep_text, cols, ""))
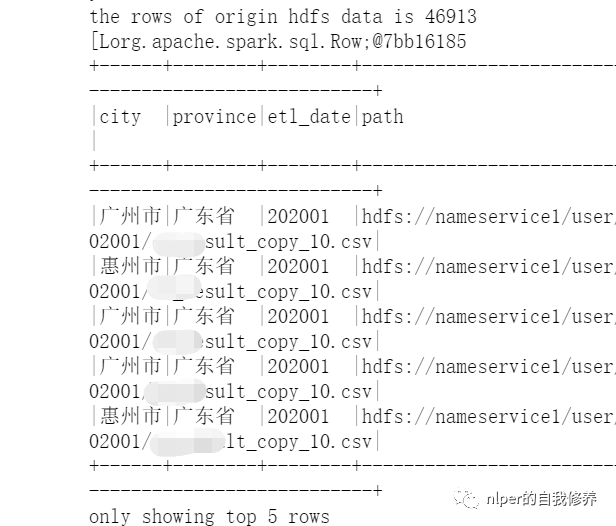
多个文件读取尝试1
- 通过wholeTextFiles读取文件夹里面的文件时,保留文件名信息;
- 具体示例可以参考文末的从hdfs取数完整脚本示例
object LoadingData_from_hdfs_wholetext_with_path extends mylog{// with Logging
...
def main(args: Array[String]=Array("tb1", "hdfs:/", "3","\n", "\001", "cols", "")): Unit = {
...
val tb_name = args(0)
val hdfs_address = args(1)
val parts = args(2)
val sep_line = args(3)
val sep_text = args(4)
val select_col = args(5)
val save_paths = args(6)
val select_cols = select_col.split("#").toSeq
val Cs = new DataProcess_get_data(spark)
val tb_desc = Cs.get_table_desc(tb_name)
val rddWhole = spark.sparkContext.wholeTextFiles(s"$hdfs_address", 10)
rddWhole.foreach(f=>{
println(f._1+"数据量是=>"+f._2.split("\n").length)
})
val files = rddWhole.collect
val len1 = files.flatMap(item => item._2.split(sep_text)).take(1).flatMap(items=>items.split(sep_line)).length
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
import org.apache.spark.sql.types.StructType
// 解析wholeTextFiles读取的结果并转化成dataframe
val wordCount = files.map(f=>f._2.split(sep_text).map(g=>g.split(sep_line):+f._1.split("/").takeRight(1)(0))).flatMap(h=>h).map(p => Row(p: _*))
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val new_schema1 = schema1.add(StructField("path", StringType))
val rawRDD = sc.parallelize(wordCount)
val df_data = spark.createDataFrame(rawRDD, new_schema1)
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
//df_desc.show(false)
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)
df_gb_result.show(5, false)
println("生成的dataframe,依path列groupby的结果如下")
df_gb_result.groupBy("path").count().show(false)
...
// spark.stop()
}
}
val file1 = "hdfs:file1_1[01].csv"
val tb_name = "tb_name"
val sep_text = "\n"
val sep_line = "\001"
val cols = "city#province#etl_date#path"
// 执行脚本
LoadingData_from_hdfs_wholetext_with_path.main(Array(tb_name, file1, "4", sep_line, sep_text, cols, ""))
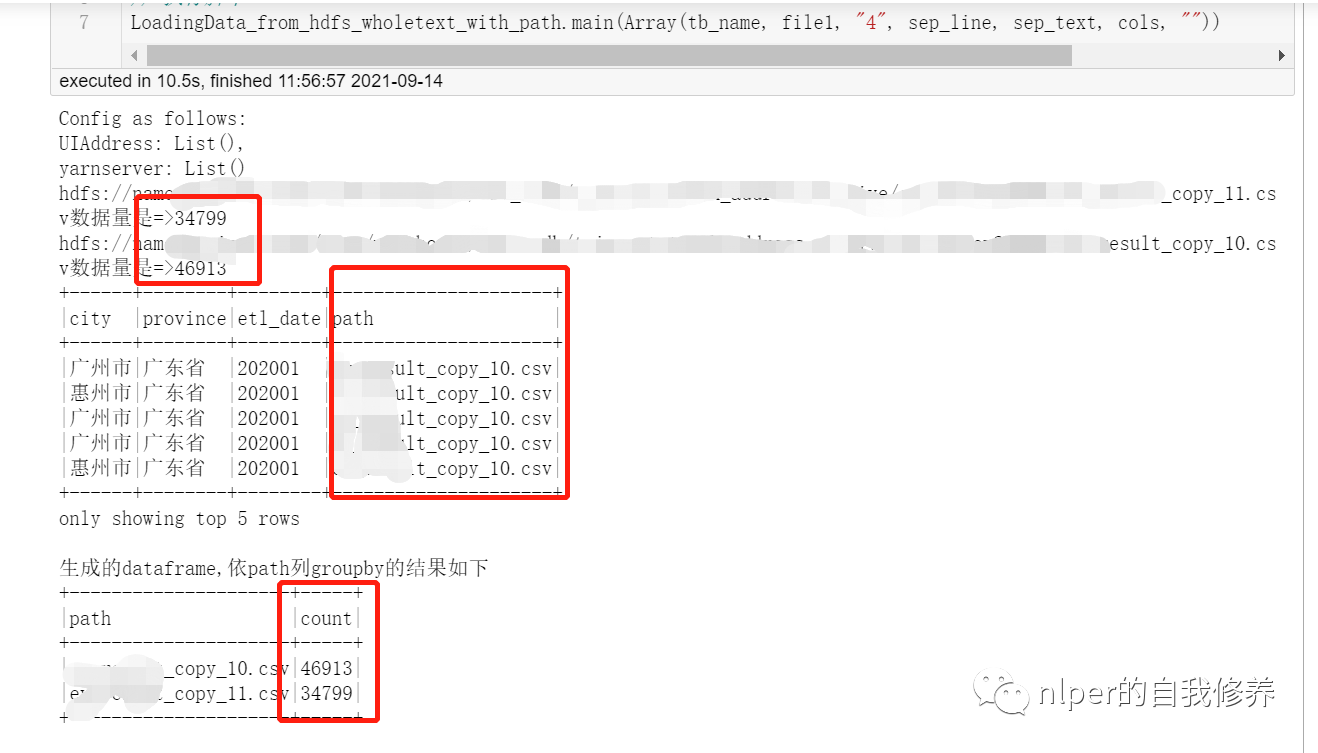
读取多文件且保留文件名为列名技术实现
以下实现功能
- 将
Array[(String, String)]类型的按(String, String)拆成多行; - 将(String, String)中的第2个元素,按照
\n分割符分成多行,按\?分隔符分成多列; - 将(String, String)中的第1个元素,分别加到2中的每行后面。在dataframe中呈现的就是新增一列啦
- 将
业务场景
- 如果要一次读取多个文件,且相对合并后的数据集中,对数据来源于哪一个文件作出区分。
// 测试用例,主要是把wholetextfile得到的结果转化为DataFrame
val test1 = Array(("abasdfsdf", "a?b?c?d\nc?d?d?e"), ("sdfasdf", "b?d?a?e\nc?d?e?f"))
val test2 = test1.map(line=>line._2.split("\n").map(line1=>line1.split("\\?"):+line._1)).flatMap(line2=>line2).map(p => Row(p: _*))
val cols = "cn1#cn2#cn3#cn4#path"
val names = cols.split("#")
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val rawRDD = sc.parallelize(test2)
val df_data = spark.createDataFrame(rawRDD, schema1)
df_data.show(4, false)
test1
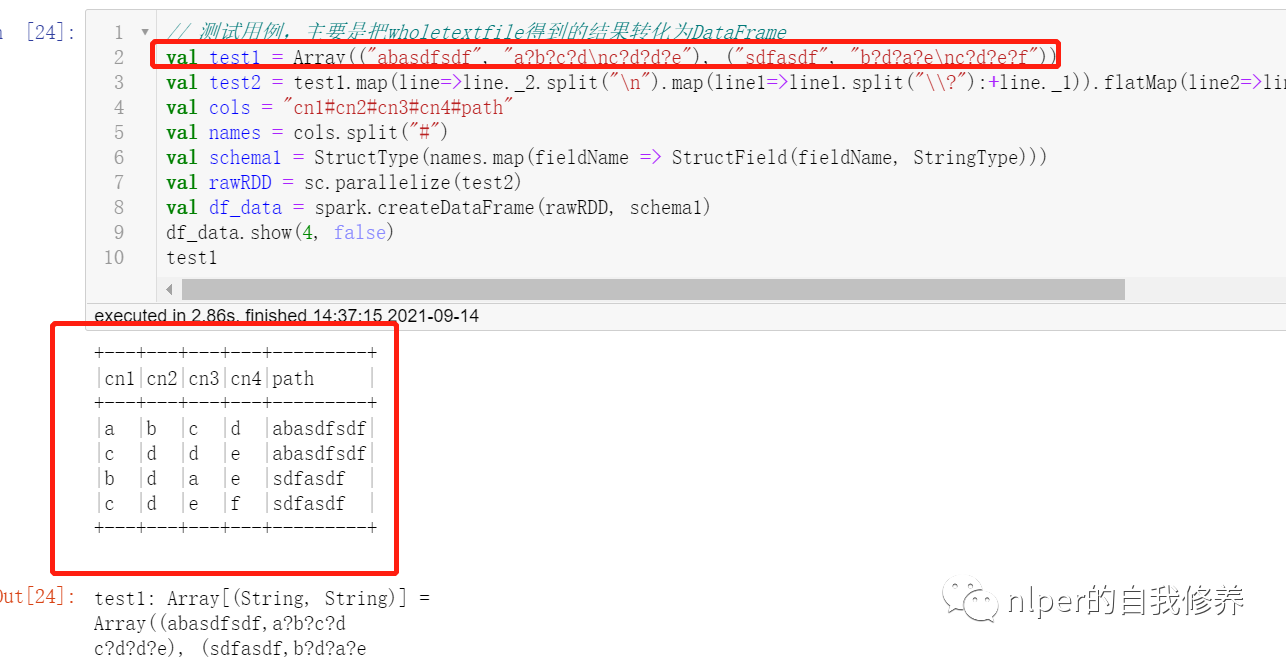
多个文件读取for循环
- 通过for循环遍历读取文件夹里面的文件时,保留文件名信息;
- 具体示例可以参考文末的从hdfs取数完整脚本示例
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row}
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.functions.monotonically_increasing_id
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}
import org.apache.hadoop.fs.{FileSystem, Path}
Logger.getLogger("org").setLevel(Level.WARN)
// val log = Logger.getLogger(this.getClass)
@transient lazy val log:Logger = Logger.getLogger(this.getClass)
class DataProcess_get_data_byfor (ss: SparkSession) extends java.io.Serializable{
import ss.implicits._
import ss.sql
import org.apache.spark.sql.types.DataTypes
...
def union_dataframe(df_1:RDD[String], df_2:RDD[String]):RDD[String] ={
val count1 = df_1.map(item=>item.split(sep_line)).take(1)(0).length
val count2 = df_2.map(item=>item.split(sep_line)).take(1)(0).length
val name2 = df_2.name.split("/").takeRight(1)(0)
val arr2 = df_2.map(item=>item.split(sep_line):+name2).map(p => Row(p: _*))
println(s"运行到这儿了")
var name1 = ""
var arr1 = ss.sparkContext.makeRDD(List().map(p => Row(p: _*)))
// var arr1 = Array[org.apache.spark.sql.Row]
if (count1 == count2){
name1 = df_1.name.split("/").takeRight(1)(0)
arr1 = df_1.map(item=>item.split(sep_line):+name1).map(p => Row(p: _*))
// arr1.foreach(f=>print(s"arr1嘞$f" + f.length + "\n"))
println(s"运行到这儿了没?$count1~$count2 $name1/$name2")
arr1
}
else{
println(s"运行到这儿了不相等哈?$count1~$count2 $name1/$name2")
arr1 = df_1.map(item=>item.split(sep_line)).map(p => Row(p: _*))
}
var rawRDD = arr1.union(arr2)
// arr3.foreach(f=>print(s"$f" + f.length + "\n"))
// var rawRDD = sc.parallelize(arr3)
var sourceRdd = rawRDD.map(_.mkString(sep_line))
// var count31 = arr1.take(1)(0).length
// var count32 = arr2.take(1)(0).length
// var count3 = sourceRdd.map(item=>item.split(sep_line)).take(1)(0).length
// var nums = sourceRdd.count
// print(s"arr1: $count31、arr2: $count32、arr3: $count3, 数据量为:$nums")
sourceRdd
}
}
object LoadingData_from_hdfs_text_with_path_byfor extends mylog{// with Logging
...
def main(args: Array[String]=Array("tb1", "hdfs:/", "3","\n", "\001", "cols","data1", "test", "")): Unit = {
...
val hdfs_address = args(1)
...
val pattern = args(6)
val pattern_no = args(7)
val select_cols = select_col.split("#").toSeq
log.warn(s"Loading cols are : \n $select_cols")
val files = FileSystem.get(spark.sparkContext.hadoopConfiguration).listStatus(new Path(s"$hdfs_address"))
val files_name = files.toList.map(f=> f.getPath.getName)
val file_filter = files_name.filter(_.contains(pattern)).filterNot(_.contains(pattern_no))
val df_1 = file_filter.map(item=> sc.textFile(s"$path1$item"))
df_1.foreach(f=>{
println(f + "数据量是" + f.count)
})
val df2 = df_1.reduce(_ union _)
println("合并后的数据量是" + df2.count)
val Cs = new DataProcess_get_data_byfor(spark)
...
// 将for循环读取的结果合并起来
val result = df_1.reduce((a, b)=>union_dataframe(a, b))
val result2 = result.map(item=>item.split(sep_line)).map(p => Row(p: _*))
val df_data = spark.createDataFrame(result2, new_schema1)
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
println("\n")
//df_desc.show(false)
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)
df_gb_result.show(5, false)
println("生成的dataframe,依path列groupby的结果如下")
df_gb_result.groupBy("path").count().show(false)
...
// spark.stop()
}
}
val path1 = "hdfs:202001/"
val tb_name = "tb_name"
val sep_text = "\n"
val sep_line = "\001"
val cols = "city#province#etl_date#path"
val pattern = "result_copy_1"
val pattern_no = "1.csv"
// val file_filter = List("file1_10.csv", "file_12.csv", "file_11.csv")
// 执行脚本
LoadingData_from_hdfs_text_with_path_byfor.main(Array(tb_name, path1, "4", sep_line, sep_text, cols, pattern, pattern_no, ""))
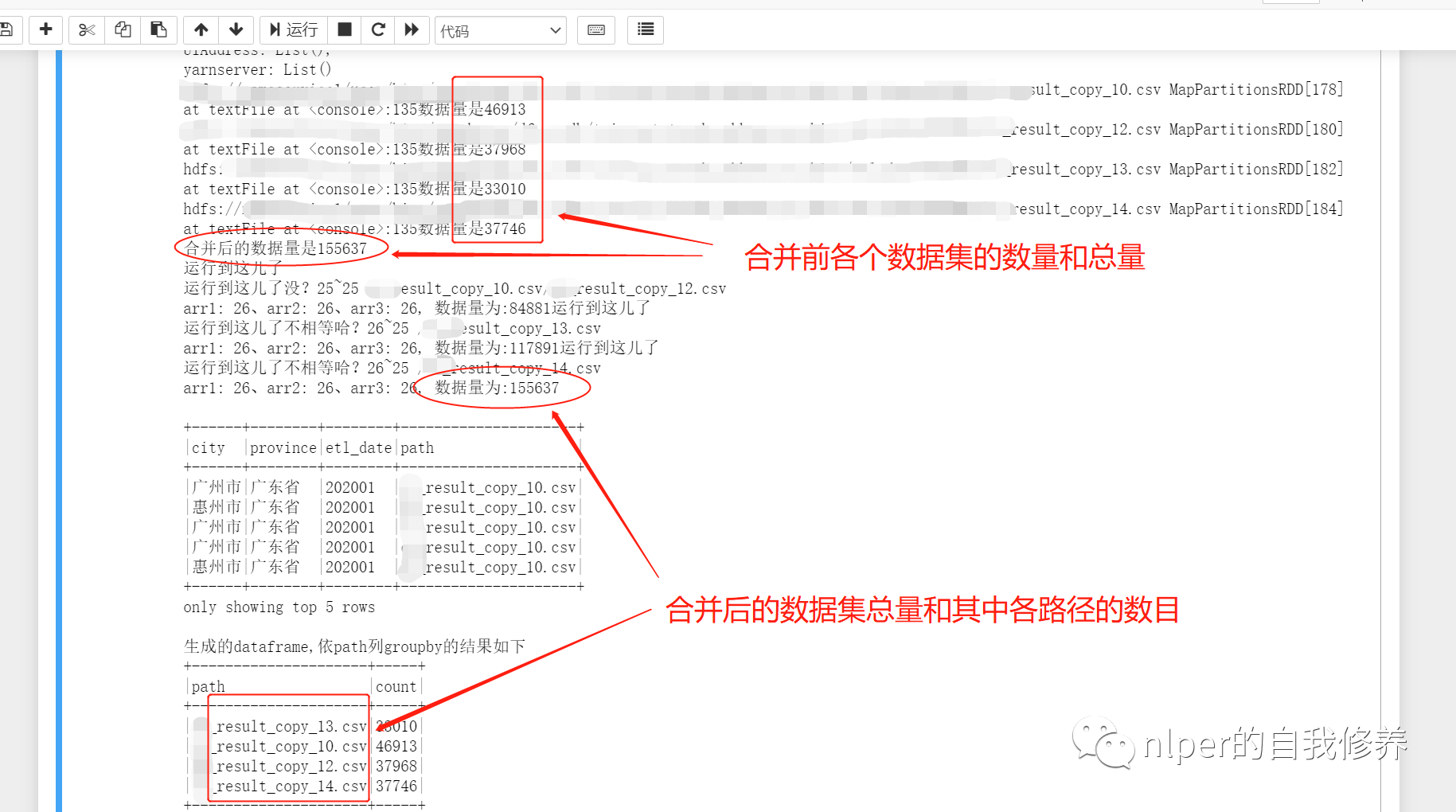
执行脚本的完整示例
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.monotonically_increasing_id
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}
Logger.getLogger("org").setLevel(Level.WARN)
val log = Logger.getLogger(this.getClass)
class DataProcess_base (ss: SparkSession) extends java.io.Serializable{
import ss.implicits._
import ss.sql
import org.apache.spark.sql.types.DataTypes
def get_table_desc(tb_name:String="tb"):DataFrame ={
val gb_sql = s"desc ${tb_name}"
val gb_desc = sql(gb_sql)
val names = gb_desc.filter(!$"col_name".contains("#")).withColumn("id", monotonically_increasing_id())
names
}
def get_hdfs_data(hdfs_address:String="hdfs:"):RDD[String]={
val gb_data = ss.sparkContext.textFile(hdfs_address)
gb_data.cache()
val counts1 = gb_data.count
println(f"the rows of origin hdfs data is $counts1%-1d")
gb_data
}
}
object LoadingData_from_hdfs_base extends mylog{// with Logging
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf()
conf.setMaster("yarn")
conf.setAppName("LoadingData_From_hdfs")
conf.set("spark.home", System.getenv("SPARK_HOME"))
val spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
import spark.implicits._
import spark.sql
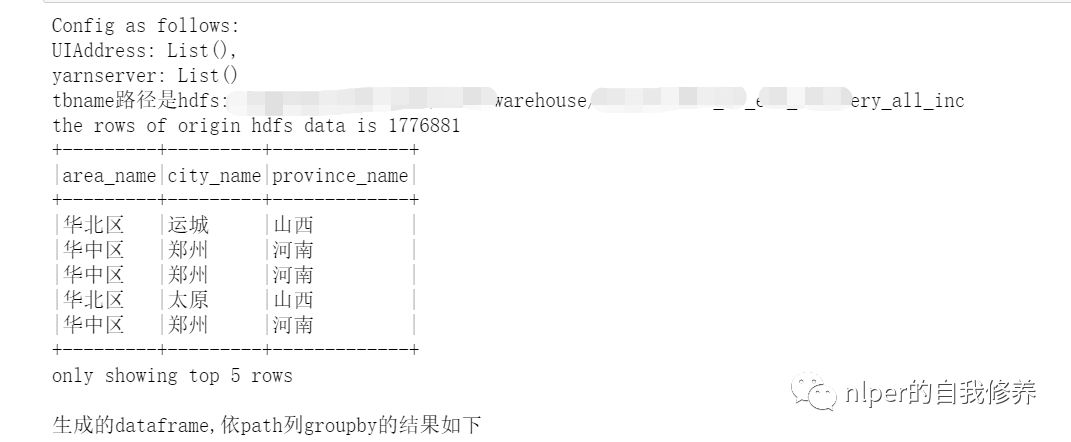
var UIAddress = spark.conf.getOption("spark.driver.appUIAddress").repr
var yarnserver = spark.conf.getOption("spark.org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter.param.PROXY_URI_BASES").repr
println(f"Config as follows: \nUIAddress: $UIAddress, \nyarnserver: $yarnserver")
def main(args: Array[String]=Array("tb1", "3", "\001", "cols", "")): Unit = {
if (args.length < 2) {
println("Usage: LoadingData_from_hdfs <tb_name, parts. sep_line, cols, paths>")
System.err.println("Usage: LoadingData_from_hdfs <tb_name, parts, sep_line, cols, paths>")
System.exit(1)
}
log.warn("开始啦调度")
val tb_name = args(0)
val parts = args(1)
val sep_line = args(2)
val select_col = args(3)
val save_paths = args(4)
val select_cols = select_col.split("#").toSeq
log.warn(s"Loading cols are : \n $select_cols")
val gb_sql = s"DESCRIBE FORMATTED ${tb_name}"
val gb_desc = sql(gb_sql)
val hdfs_address = gb_desc.filter($"col_name".contains("Location")).take(1)(0).getString(1)
println(s"tbname路径是$hdfs_address")
val hdfs_address_cha = s"$hdfs_address/*/"
val Cs = new DataProcess_base(spark)
val tb_desc = Cs.get_table_desc(tb_name)
val raw_data = Cs.get_hdfs_data(hdfs_address)
val len1 = raw_data.map(item => item.split(sep_line)).first.length
val names = tb_desc.filter(!$"col_name".contains("#")).dropDuplicates(Seq("col_name")).sort("id").select("col_name").take(len1).map(_(0)).toSeq.map(_.toString)
val schema1 = StructType(names.map(fieldName => StructField(fieldName, StringType)))
val rawRDD = raw_data.map(_.split(sep_line).map(_.toString)).map(p => Row(p: _*)).filter(_.length == len1)
val df_data = spark.createDataFrame(rawRDD, schema1)//.filter("custommsgtype = '1'")
val df_desc = select_cols.toDF.join(tb_desc, $"value"===$"col_name", "left")
val df_gb_result = df_data.select(select_cols.map(df_data.col(_)): _*)//.limit(100)
df_gb_result.show(5, false)
println("生成的dataframe,依path列groupby的结果如下")
// val part = parts.toInt
// df_gb_result.repartition(part).write.mode("overwrite").option("header","true").option("sep","#").csv(save_paths)
// log.warn(f"the rows of origin data compare to mysql results is $ncounts1%-1d VS $ncounts3%-4d")
// spark.stop()
}
}
val cols = "area_name#city_name#province_name"
val tb_name = "tb1"
val sep_line = "\u0001"
// 执行脚本
LoadingData_from_hdfs_base.main(Array(tb_name, "4", sep_line, cols, ""))
spark相关介绍-提取hive表(一)的更多相关文章
- 【原创】大叔经验分享(65)spark读取不到hive表
spark 2.4.3 spark读取hive表,步骤: 1)hive-site.xml hive-site.xml放到$SPARK_HOME/conf下 2)enableHiveSupport Sp ...
- Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
首先说一下,这里解决的问题应用场景: sparksql处理Hive表数据时,判断加载的是否是分区表,以及分区表的字段有哪些?再进一步限制查询分区表必须指定分区? 这里涉及到两种情况:select SQ ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
- spark+hcatalog操作hive表及其数据
package iie.hadoop.hcatalog.spark; import iie.udps.common.hcatalog.SerHCatInputFormat; import iie.ud ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
随机推荐
- Install Fabric 1.8.3 Manually on Ubuntu 12.04
When you install Fabric with apt-get install fabric, you get a fabric with version 1.3.x, which is t ...
- bat脚本中%~dp0含义解释
在Windows脚本中,%i类似于shell脚本中的$i,%0表示脚本本身,%1表示脚本的第一个参数,以此类推到%9,在%和i之间可以有"修饰符"(完整列表可通过"for ...
- spring学习06(AOP)
9.AOP 什么是AOP AOP(Aspect Oriented Programming)意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是软 ...
- MongoDB实例重启失败探究(大事务Redo导致)
1.实例重启背景 收到监控组同学反馈,连接某一个MongoDB实例的应用耗时异常,并且出现了超时.查看数据库监控平台,发现此实例服务器的IO异常飙升,而查看副本集状态(rs.status()),主从是 ...
- [论文阅读] ALM-HCS(高对比场景自适应对数映射)
[论文阅读] ALM-HCS(高对比场景自适应对数映射) 文章: Adaptive Logarithmic Mapping for Displaying High Contrast Scenes 1. ...
- MeteoInfo-Java解析与绘图教程(三)
MeteoInfo-Java解析与绘图教程(三) 上文我们说到简单绘制色斑图(卫星云图),但那种效果可定不符合要求,一般来说,客户需要的是在地图上色斑图的叠加,或者是将图片导出分别是这两种效果 当然还 ...
- sudo apt install net-tools [sudo] zyw 的密码: 正在读取软件包列表... 完成 正在分析软件包的依赖关系树,正在读取状态信息... 完成,没有可用的软件包 net-tools,但是它被其它的软件包引用了。这可能意味着这个缺失的软件包可能已被废弃,或者只能在其他发布源中找到
截图: 先执行: sudo apt-get update 再执行: sudo apt install net-tools 即可安装成功!!
- 在Activity和附贴的Fragment中同时使用多Surface错乱解决
SurfaceView因为独特的双缓冲机制,在android应用中十分普遍,视频播放器.摄像机预览等都会用到,如果在两个Fragment或者一个Fragment和Activity同时使用都会造成无法正 ...
- C 静态存储动态存储
首先,我们可以把程序所占的内存空间分为三个部分:(可以根据静态资源区.栈区.堆区来划分) 静态存储:程序运行期间由系统分配固定得到存储空间(栈): 动态存储:开发者根据自身需要进行动态分配的存储空间( ...
- Verilog实例数组
编写 Verilog 代码多年,至今才无意中发现了一种奇怪的语法,估计见过的这种的写法的人,在 FPGA 开发者中不会超过 20% 吧. 直接来看代码吧.先定义了一个简单的模块,名为 mod. mod ...