HDFS源码解析系列一——HDFS通信协议
通信架构
首先,看下hdfs的交互图:
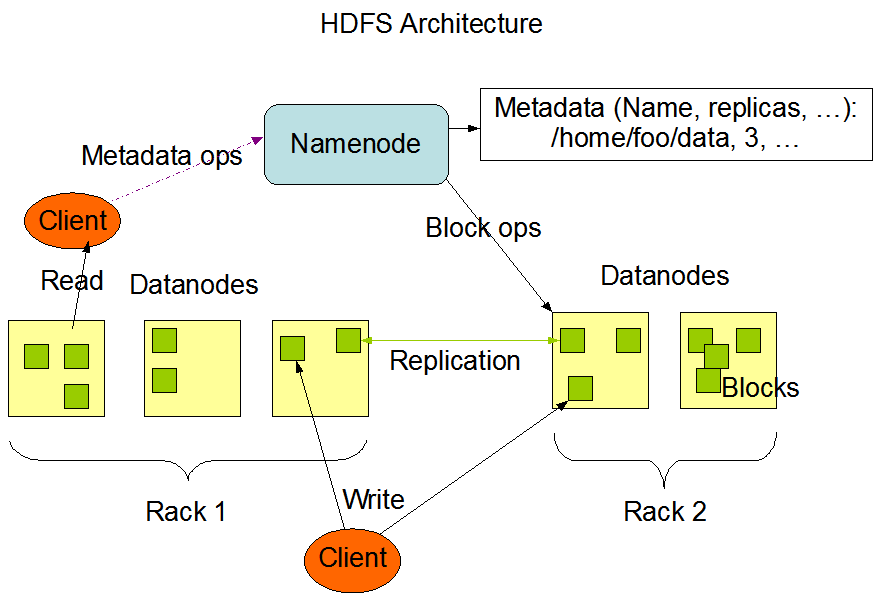
可以看到通信方面是有几个角色的:客户端(client)、NameNode、SecondaryNamenode、DataNode;其中SecondaryNamenode只与NameNode交互,其余的三种之间可以相互交互,所以便有了client—>NameNode,client—>DataNode,DataNode—>NameNode,DataNode—>DataNode,外加SecondaryNamenode<—>NameNode这几种交互方式,我们统一通过源码方式来先确定个大概轮廓。
交互协议
其实在Hadoop中存在两种通信协议,一种是基于Hadoop RPC的,其实底层是用到了ProtoBuf,这个主要用于进程间的通信,是的进程间通信形同本地调用一样的;另一种时流式通信,毕竟Hadoop是用来存储文件的数据,这就需要流式方式来读写,因为文件不能中断具备连续性底层是基于Tcp来实现的。这篇文章主要还是在于介绍各类角色间的通信,属于进程间,所以主要还是RPC接口,当然具体实现后面开篇讲清楚,目前只是给个大概轮廓。
Hadoop RPC接口主要是定义在org.apache.hadoop.hdfs.server.protocol和org.apache.hadoop.hdfs.protocol两个包中。其中主要包括如下几个接口:
- ClientProtocol:ClientProtocol定义了客户端和NameNode之间的交互,这个接口方法是非常多的,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读写文件等操作也需要先通过这个接口与NameNode协商之后,在进行数据的读出和写入。
- ClientDatanodeProtocol:客户端与DataNode之间的交互,该接口定义的方法主要用于客户端获取数据节点信息时调用,而真正进行数据读写交互的则是后续要讲到的流式接口。
- DatanodeProtocol:DataNode通过这个接口与NameNode通信,同时NameNode会通过该接口中方法的返回值向DataNode下发指令。注意,这是NameNode与DataNode通信的唯一方式,DataNode会通过这个接口向NameNode注册、汇报数据块的全量以及增量的存储情况。同时,NameNode也会通过这个接口中的方法返回值,指令DataNode执行诸如数据块复制、删除以及恢复等操作。
- InterDatanodeProtocol:DataNode之间的通信,主要用于数据块的恢复,以及同步DataNode上存储的数据块副本的信息。
- NamenodeProtocol:SecondaryNamenode与NameNode之间的通信,因为引入了HA机制,checkpoint操作不再由SecondaryNamenode执行,所以这个接口不太需要详细介绍。
- 其他接口:主要包括安全相关的RefreshAuthorizationPolicyProtocol、RefreshUserMappingsProtocol,HA相关的接口HAServiceProtocol等。
接下来一一介绍。
1、ClientProtocol
ClientProtocol定义了所有由客户端发起,由NameNode响应的操作。这个接口非常大,大概80几个方法:
查看代码
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hdfs.protocol;
import java.io.IOException;
import java.util.EnumSet;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.crypto.CryptoProtocolVersion;
import org.apache.hadoop.fs.BatchedRemoteIterator.BatchedEntries;
import org.apache.hadoop.fs.PathIsNotEmptyDirectoryException;
import org.apache.hadoop.ha.HAServiceProtocol;
import org.apache.hadoop.hdfs.AddBlockFlag;
import org.apache.hadoop.fs.CacheFlag;
import org.apache.hadoop.fs.ContentSummary;
import org.apache.hadoop.fs.CreateFlag;
import org.apache.hadoop.fs.FsServerDefaults;
import org.apache.hadoop.fs.Options;
import org.apache.hadoop.fs.QuotaUsage;
import org.apache.hadoop.fs.StorageType;
import org.apache.hadoop.fs.XAttr;
import org.apache.hadoop.fs.XAttrSetFlag;
import org.apache.hadoop.fs.permission.AclEntry;
import org.apache.hadoop.fs.permission.AclStatus;
import org.apache.hadoop.fs.permission.FsAction;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.hadoop.hdfs.inotify.EventBatchList;
import org.apache.hadoop.hdfs.protocol.HdfsConstants.ReencryptAction;
import org.apache.hadoop.hdfs.protocol.HdfsConstants.RollingUpgradeAction;
import org.apache.hadoop.hdfs.protocol.OpenFilesIterator.OpenFilesType;
import org.apache.hadoop.hdfs.security.token.block.DataEncryptionKey;
import org.apache.hadoop.hdfs.security.token.delegation.DelegationTokenIdentifier;
import org.apache.hadoop.hdfs.security.token.delegation.DelegationTokenSelector;
import org.apache.hadoop.hdfs.server.namenode.ha.ReadOnly;
import org.apache.hadoop.hdfs.server.protocol.DatanodeStorageReport;
import org.apache.hadoop.io.EnumSetWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.retry.AtMostOnce;
import org.apache.hadoop.io.retry.Idempotent;
import org.apache.hadoop.security.AccessControlException;
import org.apache.hadoop.security.KerberosInfo;
import org.apache.hadoop.security.token.Token;
import org.apache.hadoop.security.token.TokenInfo;
import static org.apache.hadoop.hdfs.client.HdfsClientConfigKeys.DFS_NAMENODE_KERBEROS_PRINCIPAL_KEY;
/**********************************************************************
* ClientProtocol is used by user code via the DistributedFileSystem class to
* communicate with the NameNode. User code can manipulate the directory
* namespace, as well as open/close file streams, etc.
*
**********************************************************************/
@InterfaceAudience.Private
@InterfaceStability.Evolving
@KerberosInfo(
serverPrincipal = DFS_NAMENODE_KERBEROS_PRINCIPAL_KEY)
@TokenInfo(DelegationTokenSelector.class)
public interface ClientProtocol {
/**
* Until version 69, this class ClientProtocol served as both
* the client interface to the NN AND the RPC protocol used to
* communicate with the NN.
*
* This class is used by both the DFSClient and the
* NN server side to insulate from the protocol serialization.
*
* If you are adding/changing this interface then you need to
* change both this class and ALSO related protocol buffer
* wire protocol definition in ClientNamenodeProtocol.proto.
*
* For more details on protocol buffer wire protocol, please see
* .../org/apache/hadoop/hdfs/protocolPB/overview.html
*
* The log of historical changes can be retrieved from the svn).
* 69: Eliminate overloaded method names.
*
* 69L is the last version id when this class was used for protocols
* serialization. DO not update this version any further.
*/
long versionID = 69L;
///////////////////////////////////////
// File contents
///////////////////////////////////////
/**
* Get locations of the blocks of the specified file
* within the specified range.
* DataNode locations for each block are sorted by
* the proximity to the client.
* <p>
* Return {@link LocatedBlocks} which contains
* file length, blocks and their locations.
* DataNode locations for each block are sorted by
* the distance to the client's address.
* <p>
* The client will then have to contact
* one of the indicated DataNodes to obtain the actual data.
*
* @param src file name
* @param offset range start offset
* @param length range length
*
* @return file length and array of blocks with their locations
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> does not
* exist
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(atimeAffected = true, isCoordinated = true)
LocatedBlocks getBlockLocations(String src, long offset, long length)
throws IOException;
/**
* Get server default values for a number of configuration params.
* @return a set of server default configuration values
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
FsServerDefaults getServerDefaults() throws IOException;
/**
* Create a new file entry in the namespace.
* <p>
* This will create an empty file specified by the source path.
* The path should reflect a full path originated at the root.
* The name-node does not have a notion of "current" directory for a client.
* <p>
* Once created, the file is visible and available for read to other clients.
* Although, other clients cannot {@link #delete(String, boolean)}, re-create
* or {@link #rename(String, String)} it until the file is completed
* or explicitly as a result of lease expiration.
* <p>
* Blocks have a maximum size. Clients that intend to create
* multi-block files must also use
* {@link #addBlock}
*
* @param src path of the file being created.
* @param masked masked permission.
* @param clientName name of the current client.
* @param flag indicates whether the file should be overwritten if it already
* exists or create if it does not exist or append, or whether the
* file should be a replicate file, no matter what its ancestor's
* replication or erasure coding policy is.
* @param createParent create missing parent directory if true
* @param replication block replication factor.
* @param blockSize maximum block size.
* @param supportedVersions CryptoProtocolVersions supported by the client
* @param ecPolicyName the name of erasure coding policy. A null value means
* this file will inherit its parent directory's policy,
* either traditional replication or erasure coding
* policy. ecPolicyName and SHOULD_REPLICATE CreateFlag
* are mutually exclusive. It's invalid to set both
* SHOULD_REPLICATE flag and a non-null ecPolicyName.
*@param storagePolicy the name of the storage policy.
*
* @return the status of the created file, it could be null if the server
* doesn't support returning the file status
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws AlreadyBeingCreatedException if the path does not exist.
* @throws DSQuotaExceededException If file creation violates disk space
* quota restriction
* @throws org.apache.hadoop.fs.FileAlreadyExistsException If file
* <code>src</code> already exists
* @throws java.io.FileNotFoundException If parent of <code>src</code> does
* not exist and <code>createParent</code> is false
* @throws org.apache.hadoop.fs.ParentNotDirectoryException If parent of
* <code>src</code> is not a directory.
* @throws NSQuotaExceededException If file creation violates name space
* quota restriction
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException create not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*
* RuntimeExceptions:
* @throws org.apache.hadoop.fs.InvalidPathException Path <code>src</code> is
* invalid
* <p>
* <em>Note that create with {@link CreateFlag#OVERWRITE} is idempotent.</em>
*/
@AtMostOnce
HdfsFileStatus create(String src, FsPermission masked,
String clientName, EnumSetWritable<CreateFlag> flag,
boolean createParent, short replication, long blockSize,
CryptoProtocolVersion[] supportedVersions, String ecPolicyName,
String storagePolicy)
throws IOException;
/**
* Append to the end of the file.
* @param src path of the file being created.
* @param clientName name of the current client.
* @param flag indicates whether the data is appended to a new block.
* @return wrapper with information about the last partial block and file
* status if any
* @throws org.apache.hadoop.security.AccessControlException if permission to
* append file is denied by the system. As usually on the client side the
* exception will be wrapped into
* {@link org.apache.hadoop.ipc.RemoteException}.
* Allows appending to an existing file if the server is
* configured with the parameter dfs.support.append set to true, otherwise
* throws an IOException.
*
* @throws org.apache.hadoop.security.AccessControlException If permission to
* append to file is denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws DSQuotaExceededException If append violates disk space quota
* restriction
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException append not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred.
*
* RuntimeExceptions:
* @throws UnsupportedOperationException if append is not supported
*/
@AtMostOnce
LastBlockWithStatus append(String src, String clientName,
EnumSetWritable<CreateFlag> flag) throws IOException;
/**
* Set replication for an existing file.
* <p>
* The NameNode sets replication to the new value and returns.
* The actual block replication is not expected to be performed during
* this method call. The blocks will be populated or removed in the
* background as the result of the routine block maintenance procedures.
*
* @param src file name
* @param replication new replication
*
* @return true if successful;
* false if file does not exist or is a directory
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws DSQuotaExceededException If replication violates disk space
* quota restriction
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@Idempotent
boolean setReplication(String src, short replication)
throws IOException;
/**
* Get all the available block storage policies.
* @return All the in-use block storage policies currently.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BlockStoragePolicy[] getStoragePolicies() throws IOException;
/**
* Set the storage policy for a file/directory.
* @param src Path of an existing file/directory.
* @param policyName The name of the storage policy
* @throws SnapshotAccessControlException If access is denied
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink
* @throws java.io.FileNotFoundException If file/dir <code>src</code> is not
* found
* @throws QuotaExceededException If changes violate the quota restriction
*/
@Idempotent
void setStoragePolicy(String src, String policyName)
throws IOException;
/**
* Unset the storage policy set for a given file or directory.
* @param src Path of an existing file/directory.
* @throws SnapshotAccessControlException If access is denied
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink
* @throws java.io.FileNotFoundException If file/dir <code>src</code> is not
* found
* @throws QuotaExceededException If changes violate the quota restriction
*/
@Idempotent
void unsetStoragePolicy(String src) throws IOException;
/**
* Get the storage policy for a file/directory.
* @param path
* Path of an existing file/directory.
* @throws AccessControlException
* If access is denied
* @throws org.apache.hadoop.fs.UnresolvedLinkException
* if <code>src</code> contains a symlink
* @throws java.io.FileNotFoundException
* If file/dir <code>src</code> is not found
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BlockStoragePolicy getStoragePolicy(String path) throws IOException;
/**
* Set permissions for an existing file/directory.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@Idempotent
void setPermission(String src, FsPermission permission)
throws IOException;
/**
* Set Owner of a path (i.e. a file or a directory).
* The parameters username and groupname cannot both be null.
* @param src file path
* @param username If it is null, the original username remains unchanged.
* @param groupname If it is null, the original groupname remains unchanged.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@Idempotent
void setOwner(String src, String username, String groupname)
throws IOException;
/**
* The client can give up on a block by calling abandonBlock().
* The client can then either obtain a new block, or complete or abandon the
* file.
* Any partial writes to the block will be discarded.
*
* @param b Block to abandon
* @param fileId The id of the file where the block resides. Older clients
* will pass GRANDFATHER_INODE_ID here.
* @param src The path of the file where the block resides.
* @param holder Lease holder.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
void abandonBlock(ExtendedBlock b, long fileId,
String src, String holder)
throws IOException;
/**
* A client that wants to write an additional block to the
* indicated filename (which must currently be open for writing)
* should call addBlock().
*
* addBlock() allocates a new block and datanodes the block data
* should be replicated to.
*
* addBlock() also commits the previous block by reporting
* to the name-node the actual generation stamp and the length
* of the block that the client has transmitted to data-nodes.
*
* @param src the file being created
* @param clientName the name of the client that adds the block
* @param previous previous block
* @param excludeNodes a list of nodes that should not be
* allocated for the current block
* @param fileId the id uniquely identifying a file
* @param favoredNodes the list of nodes where the client wants the blocks.
* Nodes are identified by either host name or address.
* @param addBlockFlags flags to advise the behavior of allocating and placing
* a new block.
*
* @return LocatedBlock allocated block information.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.NotReplicatedYetException
* previous blocks of the file are not replicated yet.
* Blocks cannot be added until replication completes.
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException create not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
LocatedBlock addBlock(String src, String clientName,
ExtendedBlock previous, DatanodeInfo[] excludeNodes, long fileId,
String[] favoredNodes, EnumSet<AddBlockFlag> addBlockFlags)
throws IOException;
/**
* Get a datanode for an existing pipeline.
*
* @param src the file being written
* @param fileId the ID of the file being written
* @param blk the block being written
* @param existings the existing nodes in the pipeline
* @param excludes the excluded nodes
* @param numAdditionalNodes number of additional datanodes
* @param clientName the name of the client
*
* @return the located block.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException create not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
LocatedBlock getAdditionalDatanode(final String src,
final long fileId, final ExtendedBlock blk,
final DatanodeInfo[] existings,
final String[] existingStorageIDs,
final DatanodeInfo[] excludes,
final int numAdditionalNodes, final String clientName
) throws IOException;
/**
* The client is done writing data to the given filename, and would
* like to complete it.
*
* The function returns whether the file has been closed successfully.
* If the function returns false, the caller should try again.
*
* close() also commits the last block of file by reporting
* to the name-node the actual generation stamp and the length
* of the block that the client has transmitted to data-nodes.
*
* A call to complete() will not return true until all the file's
* blocks have been replicated the minimum number of times. Thus,
* DataNode failures may cause a client to call complete() several
* times before succeeding.
*
* @param src the file being created
* @param clientName the name of the client that adds the block
* @param last the last block info
* @param fileId the id uniquely identifying a file
*
* @return true if all file blocks are minimally replicated or false otherwise
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException create not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
boolean complete(String src, String clientName,
ExtendedBlock last, long fileId)
throws IOException;
/**
* The client wants to report corrupted blocks (blocks with specified
* locations on datanodes).
* @param blocks Array of located blocks to report
*/
@Idempotent
void reportBadBlocks(LocatedBlock[] blocks) throws IOException;
///////////////////////////////////////
// Namespace management
///////////////////////////////////////
/**
* Rename an item in the file system namespace.
* @param src existing file or directory name.
* @param dst new name.
* @return true if successful, or false if the old name does not exist
* or if the new name already belongs to the namespace.
*
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException an I/O error occurred
*/
@AtMostOnce
boolean rename(String src, String dst)
throws IOException;
/**
* Moves blocks from srcs to trg and delete srcs.
*
* @param trg existing file
* @param srcs - list of existing files (same block size, same replication)
* @throws IOException if some arguments are invalid
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>trg</code> or
* <code>srcs</code> contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
*/
@AtMostOnce
void concat(String trg, String[] srcs)
throws IOException;
/**
* Rename src to dst.
* <ul>
* <li>Fails if src is a file and dst is a directory.
* <li>Fails if src is a directory and dst is a file.
* <li>Fails if the parent of dst does not exist or is a file.
* </ul>
* <p>
* Without OVERWRITE option, rename fails if the dst already exists.
* With OVERWRITE option, rename overwrites the dst, if it is a file
* or an empty directory. Rename fails if dst is a non-empty directory.
* <p>
* This implementation of rename is atomic.
* <p>
* @param src existing file or directory name.
* @param dst new name.
* @param options Rename options
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws DSQuotaExceededException If rename violates disk space
* quota restriction
* @throws org.apache.hadoop.fs.FileAlreadyExistsException If <code>dst</code>
* already exists and <code>options</code> has
* {@link org.apache.hadoop.fs.Options.Rename#OVERWRITE} option
* false.
* @throws java.io.FileNotFoundException If <code>src</code> does not exist
* @throws NSQuotaExceededException If rename violates namespace
* quota restriction
* @throws org.apache.hadoop.fs.ParentNotDirectoryException If parent of
* <code>dst</code> is not a directory
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException rename not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code> or
* <code>dst</code> contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@AtMostOnce
void rename2(String src, String dst, Options.Rename... options)
throws IOException;
/**
* Truncate file src to new size.
* <ul>
* <li>Fails if src is a directory.
* <li>Fails if src does not exist.
* <li>Fails if src is not closed.
* <li>Fails if new size is greater than current size.
* </ul>
* <p>
* This implementation of truncate is purely a namespace operation if truncate
* occurs at a block boundary. Requires DataNode block recovery otherwise.
* <p>
* @param src existing file
* @param newLength the target size
*
* @return true if client does not need to wait for block recovery,
* false if client needs to wait for block recovery.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException truncate
* not allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@Idempotent
boolean truncate(String src, long newLength, String clientName)
throws IOException;
/**
* Delete the given file or directory from the file system.
* <p>
* same as delete but provides a way to avoid accidentally
* deleting non empty directories programmatically.
* @param src existing name
* @param recursive if true deletes a non empty directory recursively,
* else throws an exception.
* @return true only if the existing file or directory was actually removed
* from the file system.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws java.io.FileNotFoundException If file <code>src</code> is not found
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException create not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws PathIsNotEmptyDirectoryException if path is a non-empty directory
* and <code>recursive</code> is set to false
* @throws IOException If an I/O error occurred
*/
@AtMostOnce
boolean delete(String src, boolean recursive)
throws IOException;
/**
* Create a directory (or hierarchy of directories) with the given
* name and permission.
*
* @param src The path of the directory being created
* @param masked The masked permission of the directory being created
* @param createParent create missing parent directory if true
*
* @return True if the operation success.
*
* @throws org.apache.hadoop.security.AccessControlException If access is
* denied
* @throws org.apache.hadoop.fs.FileAlreadyExistsException If <code>src</code>
* already exists
* @throws java.io.FileNotFoundException If parent of <code>src</code> does
* not exist and <code>createParent</code> is false
* @throws NSQuotaExceededException If file creation violates quota
* restriction
* @throws org.apache.hadoop.fs.ParentNotDirectoryException If parent of
* <code>src</code> is not a directory
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException create not
* allowed in safemode
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred.
*
* RunTimeExceptions:
* @throws org.apache.hadoop.fs.InvalidPathException If <code>src</code> is
* invalid
*/
@Idempotent
boolean mkdirs(String src, FsPermission masked, boolean createParent)
throws IOException;
/**
* Get a partial listing of the indicated directory.
*
* @param src the directory name
* @param startAfter the name to start listing after encoded in java UTF8
* @param needLocation if the FileStatus should contain block locations
*
* @return a partial listing starting after startAfter
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException If <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
DirectoryListing getListing(String src, byte[] startAfter,
boolean needLocation) throws IOException;
/**
* Get a partial listing of the input directories
*
* @param srcs the input directories
* @param startAfter the name to start listing after encoded in Java UTF8
* @param needLocation if the FileStatus should contain block locations
*
* @return a partial listing starting after startAfter. null if the input is
* empty
* @throws IOException if an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BatchedDirectoryListing getBatchedListing(
String[] srcs,
byte[] startAfter,
boolean needLocation) throws IOException;
/**
* Get the list of snapshottable directories that are owned
* by the current user. Return all the snapshottable directories if the
* current user is a super user.
* @return The list of all the current snapshottable directories.
* @throws IOException If an I/O error occurred.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
SnapshottableDirectoryStatus[] getSnapshottableDirListing()
throws IOException;
///////////////////////////////////////
// System issues and management
///////////////////////////////////////
/**
* Client programs can cause stateful changes in the NameNode
* that affect other clients. A client may obtain a file and
* neither abandon nor complete it. A client might hold a series
* of locks that prevent other clients from proceeding.
* Clearly, it would be bad if a client held a bunch of locks
* that it never gave up. This can happen easily if the client
* dies unexpectedly.
* <p>
* So, the NameNode will revoke the locks and live file-creates
* for clients that it thinks have died. A client tells the
* NameNode that it is still alive by periodically calling
* renewLease(). If a certain amount of time passes since
* the last call to renewLease(), the NameNode assumes the
* client has died.
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws IOException If an I/O error occurred
*/
@Idempotent
void renewLease(String clientName) throws IOException;
/**
* Start lease recovery.
* Lightweight NameNode operation to trigger lease recovery
*
* @param src path of the file to start lease recovery
* @param clientName name of the current client
* @return true if the file is already closed
* @throws IOException
*/
@Idempotent
boolean recoverLease(String src, String clientName) throws IOException;
/**
* Constants to index the array of aggregated stats returned by
* {@link #getStats()}.
*/
int GET_STATS_CAPACITY_IDX = 0;
int GET_STATS_USED_IDX = 1;
int GET_STATS_REMAINING_IDX = 2;
/**
* Use {@link #GET_STATS_LOW_REDUNDANCY_IDX} instead.
*/
@Deprecated
int GET_STATS_UNDER_REPLICATED_IDX = 3;
int GET_STATS_LOW_REDUNDANCY_IDX = 3;
int GET_STATS_CORRUPT_BLOCKS_IDX = 4;
int GET_STATS_MISSING_BLOCKS_IDX = 5;
int GET_STATS_MISSING_REPL_ONE_BLOCKS_IDX = 6;
int GET_STATS_BYTES_IN_FUTURE_BLOCKS_IDX = 7;
int GET_STATS_PENDING_DELETION_BLOCKS_IDX = 8;
int STATS_ARRAY_LENGTH = 9;
/**
* Get an array of aggregated statistics combining blocks of both type
* {@link BlockType#CONTIGUOUS} and {@link BlockType#STRIPED} in the
* filesystem. Use public constants like {@link #GET_STATS_CAPACITY_IDX} in
* place of actual numbers to index into the array.
* <ul>
* <li> [0] contains the total storage capacity of the system, in bytes.</li>
* <li> [1] contains the total used space of the system, in bytes.</li>
* <li> [2] contains the available storage of the system, in bytes.</li>
* <li> [3] contains number of low redundancy blocks in the system.</li>
* <li> [4] contains number of corrupt blocks. </li>
* <li> [5] contains number of blocks without any good replicas left. </li>
* <li> [6] contains number of blocks which have replication factor
* 1 and have lost the only replica. </li>
* <li> [7] contains number of bytes that are at risk for deletion. </li>
* <li> [8] contains number of pending deletion blocks. </li>
* </ul>
*/
@Idempotent
@ReadOnly
long[] getStats() throws IOException;
/**
* Get statistics pertaining to blocks of type {@link BlockType#CONTIGUOUS}
* in the filesystem.
*/
@Idempotent
@ReadOnly
ReplicatedBlockStats getReplicatedBlockStats() throws IOException;
/**
* Get statistics pertaining to blocks of type {@link BlockType#STRIPED}
* in the filesystem.
*/
@Idempotent
@ReadOnly
ECBlockGroupStats getECBlockGroupStats() throws IOException;
/**
* Get a report on the system's current datanodes.
* One DatanodeInfo object is returned for each DataNode.
* Return live datanodes if type is LIVE; dead datanodes if type is DEAD;
* otherwise all datanodes if type is ALL.
*/
@Idempotent
@ReadOnly
DatanodeInfo[] getDatanodeReport(HdfsConstants.DatanodeReportType type)
throws IOException;
/**
* Get a report on the current datanode storages.
*/
@Idempotent
@ReadOnly
DatanodeStorageReport[] getDatanodeStorageReport(
HdfsConstants.DatanodeReportType type) throws IOException;
/**
* Get the block size for the given file.
* @param filename The name of the file
* @return The number of bytes in each block
* @throws IOException
* @throws org.apache.hadoop.fs.UnresolvedLinkException if the path contains
* a symlink.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
long getPreferredBlockSize(String filename)
throws IOException;
/**
* Enter, leave or get safe mode.
* <p>
* Safe mode is a name node state when it
* <ol><li>does not accept changes to name space (read-only), and</li>
* <li>does not replicate or delete blocks.</li></ol>
*
* <p>
* Safe mode is entered automatically at name node startup.
* Safe mode can also be entered manually using
* {@link #setSafeMode(HdfsConstants.SafeModeAction,boolean)
* setSafeMode(SafeModeAction.SAFEMODE_ENTER,false)}.
* <p>
* At startup the name node accepts data node reports collecting
* information about block locations.
* In order to leave safe mode it needs to collect a configurable
* percentage called threshold of blocks, which satisfy the minimal
* replication condition.
* The minimal replication condition is that each block must have at least
* {@code dfs.namenode.replication.min} replicas.
* When the threshold is reached the name node extends safe mode
* for a configurable amount of time
* to let the remaining data nodes to check in before it
* will start replicating missing blocks.
* Then the name node leaves safe mode.
* <p>
* If safe mode is turned on manually using
* {@link #setSafeMode(HdfsConstants.SafeModeAction,boolean)
* setSafeMode(SafeModeAction.SAFEMODE_ENTER,false)}
* then the name node stays in safe mode until it is manually turned off
* using {@link #setSafeMode(HdfsConstants.SafeModeAction,boolean)
* setSafeMode(SafeModeAction.SAFEMODE_LEAVE,false)}.
* Current state of the name node can be verified using
* {@link #setSafeMode(HdfsConstants.SafeModeAction,boolean)
* setSafeMode(SafeModeAction.SAFEMODE_GET,false)}
*
* <p><b>Configuration parameters:</b></p>
* {@code dfs.safemode.threshold.pct} is the threshold parameter.<br>
* {@code dfs.safemode.extension} is the safe mode extension parameter.<br>
* {@code dfs.namenode.replication.min} is the minimal replication parameter.
*
* <p><b>Special cases:</b></p>
* The name node does not enter safe mode at startup if the threshold is
* set to 0 or if the name space is empty.<br>
* If the threshold is set to 1 then all blocks need to have at least
* minimal replication.<br>
* If the threshold value is greater than 1 then the name node will not be
* able to turn off safe mode automatically.<br>
* Safe mode can always be turned off manually.
*
* @param action <ul> <li>0 leave safe mode;</li>
* <li>1 enter safe mode;</li>
* <li>2 get safe mode state.</li></ul>
* @param isChecked If true then action will be done only in ActiveNN.
*
* @return <ul><li>0 if the safe mode is OFF or</li>
* <li>1 if the safe mode is ON.</li></ul>
*
* @throws IOException
*/
@Idempotent
boolean setSafeMode(HdfsConstants.SafeModeAction action, boolean isChecked)
throws IOException;
/**
* Save namespace image.
* <p>
* Saves current namespace into storage directories and reset edits log.
* Requires superuser privilege and safe mode.
*
* @param timeWindow NameNode does a checkpoint if the latest checkpoint was
* done beyond the given time period (in seconds).
* @param txGap NameNode does a checkpoint if the gap between the latest
* checkpoint and the latest transaction id is greater this gap.
* @return whether an extra checkpoint has been done
*
* @throws IOException if image creation failed.
*/
@AtMostOnce
boolean saveNamespace(long timeWindow, long txGap) throws IOException;
/**
* Roll the edit log.
* Requires superuser privileges.
*
* @throws org.apache.hadoop.security.AccessControlException if the superuser
* privilege is violated
* @throws IOException if log roll fails
* @return the txid of the new segment
*/
@Idempotent
long rollEdits() throws IOException;
/**
* Enable/Disable restore failed storage.
* <p>
* sets flag to enable restore of failed storage replicas
*
* @throws org.apache.hadoop.security.AccessControlException if the superuser
* privilege is violated.
*/
@Idempotent
boolean restoreFailedStorage(String arg) throws IOException;
/**
* Tells the namenode to reread the hosts and exclude files.
* @throws IOException
*/
@Idempotent
void refreshNodes() throws IOException;
/**
* Finalize previous upgrade.
* Remove file system state saved during the upgrade.
* The upgrade will become irreversible.
*
* @throws IOException
*/
@Idempotent
void finalizeUpgrade() throws IOException;
/**
* Get status of upgrade - finalized or not.
* @return true if upgrade is finalized or if no upgrade is in progress and
* false otherwise.
* @throws IOException
*/
@Idempotent
boolean upgradeStatus() throws IOException;
/**
* Rolling upgrade operations.
* @param action either query, prepare or finalize.
* @return rolling upgrade information. On query, if no upgrade is in
* progress, returns null.
*/
@Idempotent
RollingUpgradeInfo rollingUpgrade(RollingUpgradeAction action)
throws IOException;
/**
* @return CorruptFileBlocks, containing a list of corrupt files (with
* duplicates if there is more than one corrupt block in a file)
* and a cookie
* @throws IOException
*
* Each call returns a subset of the corrupt files in the system. To obtain
* all corrupt files, call this method repeatedly and each time pass in the
* cookie returned from the previous call.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
CorruptFileBlocks listCorruptFileBlocks(String path, String cookie)
throws IOException;
/**
* Dumps namenode data structures into specified file. If the file
* already exists, then append.
*
* @throws IOException
*/
@Idempotent
void metaSave(String filename) throws IOException;
/**
* Tell all datanodes to use a new, non-persistent bandwidth value for
* dfs.datanode.balance.bandwidthPerSec.
*
* @param bandwidth Blanacer bandwidth in bytes per second for this datanode.
* @throws IOException
*/
@Idempotent
void setBalancerBandwidth(long bandwidth) throws IOException;
/**
* Get the file info for a specific file or directory.
* @param src The string representation of the path to the file
*
* @return object containing information regarding the file
* or null if file not found
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException if the path contains
* a symlink.
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
HdfsFileStatus getFileInfo(String src) throws IOException;
/**
* Get the close status of a file.
* @param src The string representation of the path to the file
*
* @return return true if file is closed
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException if the path contains
* a symlink.
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
boolean isFileClosed(String src) throws IOException;
/**
* Get the file info for a specific file or directory. If the path
* refers to a symlink then the FileStatus of the symlink is returned.
* @param src The string representation of the path to the file
*
* @return object containing information regarding the file
* or null if file not found
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
HdfsFileStatus getFileLinkInfo(String src) throws IOException;
/**
* Get the file info for a specific file or directory with
* {@link LocatedBlocks}.
* @param src The string representation of the path to the file
* @param needBlockToken Generate block tokens for {@link LocatedBlocks}
* @return object containing information regarding the file
* or null if file not found
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
HdfsLocatedFileStatus getLocatedFileInfo(String src, boolean needBlockToken)
throws IOException;
/**
* Get {@link ContentSummary} rooted at the specified directory.
* @param path The string representation of the path
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>path</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>path</code>
* contains a symlink.
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
ContentSummary getContentSummary(String path) throws IOException;
/**
* Set the quota for a directory.
* @param path The string representation of the path to the directory
* @param namespaceQuota Limit on the number of names in the tree rooted
* at the directory
* @param storagespaceQuota Limit on storage space occupied all the files
* under this directory.
* @param type StorageType that the space quota is intended to be set on.
* It may be null when called by traditional space/namespace
* quota. When type is is not null, the storagespaceQuota
* parameter is for type specified and namespaceQuota must be
* {@link HdfsConstants#QUOTA_DONT_SET}.
*
* <br><br>
*
* The quota can have three types of values : (1) 0 or more will set
* the quota to that value, (2) {@link HdfsConstants#QUOTA_DONT_SET} implies
* the quota will not be changed, and (3) {@link HdfsConstants#QUOTA_RESET}
* implies the quota will be reset. Any other value is a runtime error.
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>path</code> is not found
* @throws QuotaExceededException if the directory size
* is greater than the given quota
* @throws org.apache.hadoop.fs.UnresolvedLinkException if the
* <code>path</code> contains a symlink.
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@Idempotent
void setQuota(String path, long namespaceQuota, long storagespaceQuota,
StorageType type) throws IOException;
/**
* Write all metadata for this file into persistent storage.
* The file must be currently open for writing.
* @param src The string representation of the path
* @param inodeId The inode ID, or GRANDFATHER_INODE_ID if the client is
* too old to support fsync with inode IDs.
* @param client The string representation of the client
* @param lastBlockLength The length of the last block (under construction)
* to be reported to NameNode
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink.
* @throws IOException If an I/O error occurred
*/
@Idempotent
void fsync(String src, long inodeId, String client, long lastBlockLength)
throws IOException;
/**
* Sets the modification and access time of the file to the specified time.
* @param src The string representation of the path
* @param mtime The number of milliseconds since Jan 1, 1970.
* Setting negative mtime means that modification time should not
* be set by this call.
* @param atime The number of milliseconds since Jan 1, 1970.
* Setting negative atime means that access time should not be
* set by this call.
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>src</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink.
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@Idempotent
void setTimes(String src, long mtime, long atime) throws IOException;
/**
* Create symlink to a file or directory.
* @param target The path of the destination that the
* link points to.
* @param link The path of the link being created.
* @param dirPerm permissions to use when creating parent directories
* @param createParent - if true then missing parent dirs are created
* if false then parent must exist
*
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws org.apache.hadoop.fs.FileAlreadyExistsException If file
* <code>link</code> already exists
* @throws java.io.FileNotFoundException If parent of <code>link</code> does
* not exist and <code>createParent</code> is false
* @throws org.apache.hadoop.fs.ParentNotDirectoryException If parent of
* <code>link</code> is not a directory.
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>link</code>
* contains a symlink.
* @throws SnapshotAccessControlException if path is in RO snapshot
* @throws IOException If an I/O error occurred
*/
@AtMostOnce
void createSymlink(String target, String link, FsPermission dirPerm,
boolean createParent) throws IOException;
/**
* Return the target of the given symlink. If there is an intermediate
* symlink in the path (ie a symlink leading up to the final path component)
* then the given path is returned with this symlink resolved.
*
* @param path The path with a link that needs resolution.
* @return The path after resolving the first symbolic link in the path.
* @throws org.apache.hadoop.security.AccessControlException permission denied
* @throws java.io.FileNotFoundException If <code>path</code> does not exist
* @throws IOException If the given path does not refer to a symlink
* or an I/O error occurred
*/
@Idempotent
@ReadOnly(isCoordinated = true)
String getLinkTarget(String path) throws IOException;
/**
* Get a new generation stamp together with an access token for
* a block under construction
*
* This method is called only when a client needs to recover a failed
* pipeline or set up a pipeline for appending to a block.
*
* @param block a block
* @param clientName the name of the client
* @return a located block with a new generation stamp and an access token
* @throws IOException if any error occurs
*/
@Idempotent
LocatedBlock updateBlockForPipeline(ExtendedBlock block,
String clientName) throws IOException;
/**
* Update a pipeline for a block under construction.
*
* @param clientName the name of the client
* @param oldBlock the old block
* @param newBlock the new block containing new generation stamp and length
* @param newNodes datanodes in the pipeline
* @throws IOException if any error occurs
*/
@AtMostOnce
void updatePipeline(String clientName, ExtendedBlock oldBlock,
ExtendedBlock newBlock, DatanodeID[] newNodes, String[] newStorageIDs)
throws IOException;
/**
* Get a valid Delegation Token.
*
* @param renewer the designated renewer for the token
* @throws IOException
*/
@Idempotent
Token<DelegationTokenIdentifier> getDelegationToken(Text renewer)
throws IOException;
/**
* Renew an existing delegation token.
*
* @param token delegation token obtained earlier
* @return the new expiration time
* @throws IOException
*/
@Idempotent
long renewDelegationToken(Token<DelegationTokenIdentifier> token)
throws IOException;
/**
* Cancel an existing delegation token.
*
* @param token delegation token
* @throws IOException
*/
@Idempotent
void cancelDelegationToken(Token<DelegationTokenIdentifier> token)
throws IOException;
/**
* @return encryption key so a client can encrypt data sent via the
* DataTransferProtocol to/from DataNodes.
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
DataEncryptionKey getDataEncryptionKey() throws IOException;
/**
* Create a snapshot.
* @param snapshotRoot the path that is being snapshotted
* @param snapshotName name of the snapshot created
* @return the snapshot path.
* @throws IOException
*/
@AtMostOnce
String createSnapshot(String snapshotRoot, String snapshotName)
throws IOException;
/**
* Delete a specific snapshot of a snapshottable directory.
* @param snapshotRoot The snapshottable directory
* @param snapshotName Name of the snapshot for the snapshottable directory
* @throws IOException
*/
@AtMostOnce
void deleteSnapshot(String snapshotRoot, String snapshotName)
throws IOException;
/**
* Rename a snapshot.
* @param snapshotRoot the directory path where the snapshot was taken
* @param snapshotOldName old name of the snapshot
* @param snapshotNewName new name of the snapshot
* @throws IOException
*/
@AtMostOnce
void renameSnapshot(String snapshotRoot, String snapshotOldName,
String snapshotNewName) throws IOException;
/**
* Allow snapshot on a directory.
* @param snapshotRoot the directory to be snapped
* @throws IOException on error
*/
@Idempotent
void allowSnapshot(String snapshotRoot)
throws IOException;
/**
* Disallow snapshot on a directory.
* @param snapshotRoot the directory to disallow snapshot
* @throws IOException on error
*/
@Idempotent
void disallowSnapshot(String snapshotRoot)
throws IOException;
/**
* Get the difference between two snapshots, or between a snapshot and the
* current tree of a directory.
*
* @param snapshotRoot
* full path of the directory where snapshots are taken
* @param fromSnapshot
* snapshot name of the from point. Null indicates the current
* tree
* @param toSnapshot
* snapshot name of the to point. Null indicates the current
* tree.
* @return The difference report represented as a {@link SnapshotDiffReport}.
* @throws IOException on error
*/
@Idempotent
@ReadOnly(isCoordinated = true)
SnapshotDiffReport getSnapshotDiffReport(String snapshotRoot,
String fromSnapshot, String toSnapshot) throws IOException;
/**
* Get the difference between two snapshots of a directory iteratively.
*
* @param snapshotRoot
* full path of the directory where snapshots are taken
* @param fromSnapshot
* snapshot name of the from point. Null indicates the current
* tree
* @param toSnapshot
* snapshot name of the to point. Null indicates the current
* tree.
* @param startPath
* path relative to the snapshottable root directory from where the
* snapshotdiff computation needs to start across multiple rpc calls
* @param index
* index in the created or deleted list of the directory at which
* the snapshotdiff computation stopped during the last rpc call
* as the no of entries exceeded the snapshotdiffentry limit. -1
* indicates, the snapshotdiff compuatation needs to start right
* from the startPath provided.
* @return The difference report represented as a {@link SnapshotDiffReport}.
* @throws IOException on error
*/
@Idempotent
@ReadOnly(isCoordinated = true)
SnapshotDiffReportListing getSnapshotDiffReportListing(String snapshotRoot,
String fromSnapshot, String toSnapshot, byte[] startPath, int index)
throws IOException;
/**
* Add a CacheDirective to the CacheManager.
*
* @param directive A CacheDirectiveInfo to be added
* @param flags {@link CacheFlag}s to use for this operation.
* @return A CacheDirectiveInfo associated with the added directive
* @throws IOException if the directive could not be added
*/
@AtMostOnce
long addCacheDirective(CacheDirectiveInfo directive,
EnumSet<CacheFlag> flags) throws IOException;
/**
* Modify a CacheDirective in the CacheManager.
*
* @param flags {@link CacheFlag}s to use for this operation.
* @throws IOException if the directive could not be modified
*/
@AtMostOnce
void modifyCacheDirective(CacheDirectiveInfo directive,
EnumSet<CacheFlag> flags) throws IOException;
/**
* Remove a CacheDirectiveInfo from the CacheManager.
*
* @param id of a CacheDirectiveInfo
* @throws IOException if the cache directive could not be removed
*/
@AtMostOnce
void removeCacheDirective(long id) throws IOException;
/**
* List the set of cached paths of a cache pool. Incrementally fetches results
* from the server.
*
* @param prevId The last listed entry ID, or -1 if this is the first call to
* listCacheDirectives.
* @param filter Parameters to use to filter the list results,
* or null to display all directives visible to us.
* @return A batch of CacheDirectiveEntry objects.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BatchedEntries<CacheDirectiveEntry> listCacheDirectives(
long prevId, CacheDirectiveInfo filter) throws IOException;
/**
* Add a new cache pool.
*
* @param info Description of the new cache pool
* @throws IOException If the request could not be completed.
*/
@AtMostOnce
void addCachePool(CachePoolInfo info) throws IOException;
/**
* Modify an existing cache pool.
*
* @param req
* The request to modify a cache pool.
* @throws IOException
* If the request could not be completed.
*/
@AtMostOnce
void modifyCachePool(CachePoolInfo req) throws IOException;
/**
* Remove a cache pool.
*
* @param pool name of the cache pool to remove.
* @throws IOException if the cache pool did not exist, or could not be
* removed.
*/
@AtMostOnce
void removeCachePool(String pool) throws IOException;
/**
* List the set of cache pools. Incrementally fetches results from the server.
*
* @param prevPool name of the last pool listed, or the empty string if this
* is the first invocation of listCachePools
* @return A batch of CachePoolEntry objects.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BatchedEntries<CachePoolEntry> listCachePools(String prevPool)
throws IOException;
/**
* Modifies ACL entries of files and directories. This method can add new ACL
* entries or modify the permissions on existing ACL entries. All existing
* ACL entries that are not specified in this call are retained without
* changes. (Modifications are merged into the current ACL.)
*/
@Idempotent
void modifyAclEntries(String src, List<AclEntry> aclSpec)
throws IOException;
/**
* Removes ACL entries from files and directories. Other ACL entries are
* retained.
*/
@Idempotent
void removeAclEntries(String src, List<AclEntry> aclSpec)
throws IOException;
/**
* Removes all default ACL entries from files and directories.
*/
@Idempotent
void removeDefaultAcl(String src) throws IOException;
/**
* Removes all but the base ACL entries of files and directories. The entries
* for user, group, and others are retained for compatibility with permission
* bits.
*/
@Idempotent
void removeAcl(String src) throws IOException;
/**
* Fully replaces ACL of files and directories, discarding all existing
* entries.
*/
@Idempotent
void setAcl(String src, List<AclEntry> aclSpec) throws IOException;
/**
* Gets the ACLs of files and directories.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
AclStatus getAclStatus(String src) throws IOException;
/**
* Create an encryption zone.
*/
@AtMostOnce
void createEncryptionZone(String src, String keyName)
throws IOException;
/**
* Get the encryption zone for a path.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
EncryptionZone getEZForPath(String src)
throws IOException;
/**
* Used to implement cursor-based batched listing of {@link EncryptionZone}s.
*
* @param prevId ID of the last item in the previous batch. If there is no
* previous batch, a negative value can be used.
* @return Batch of encryption zones.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BatchedEntries<EncryptionZone> listEncryptionZones(
long prevId) throws IOException;
/**
* Used to implement re-encryption of encryption zones.
*
* @param zone the encryption zone to re-encrypt.
* @param action the action for the re-encryption.
* @throws IOException
*/
@AtMostOnce
void reencryptEncryptionZone(String zone, ReencryptAction action)
throws IOException;
/**
* Used to implement cursor-based batched listing of
* {@link ZoneReencryptionStatus}s.
*
* @param prevId ID of the last item in the previous batch. If there is no
* previous batch, a negative value can be used.
* @return Batch of encryption zones.
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BatchedEntries<ZoneReencryptionStatus> listReencryptionStatus(long prevId)
throws IOException;
/**
* Set xattr of a file or directory.
* The name must be prefixed with the namespace followed by ".". For example,
* "user.attr".
* <p>
* Refer to the HDFS extended attributes user documentation for details.
*
* @param src file or directory
* @param xAttr <code>XAttr</code> to set
* @param flag set flag
* @throws IOException
*/
@AtMostOnce
void setXAttr(String src, XAttr xAttr, EnumSet<XAttrSetFlag> flag)
throws IOException;
/**
* Get xattrs of a file or directory. Values in xAttrs parameter are ignored.
* If xAttrs is null or empty, this is the same as getting all xattrs of the
* file or directory. Only those xattrs for which the logged-in user has
* permissions to view are returned.
* <p>
* Refer to the HDFS extended attributes user documentation for details.
*
* @param src file or directory
* @param xAttrs xAttrs to get
* @return <code>XAttr</code> list
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
List<XAttr> getXAttrs(String src, List<XAttr> xAttrs)
throws IOException;
/**
* List the xattrs names for a file or directory.
* Only the xattr names for which the logged in user has the permissions to
* access will be returned.
* <p>
* Refer to the HDFS extended attributes user documentation for details.
*
* @param src file or directory
* @return <code>XAttr</code> list
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
List<XAttr> listXAttrs(String src)
throws IOException;
/**
* Remove xattr of a file or directory.Value in xAttr parameter is ignored.
* The name must be prefixed with the namespace followed by ".". For example,
* "user.attr".
* <p>
* Refer to the HDFS extended attributes user documentation for details.
*
* @param src file or directory
* @param xAttr <code>XAttr</code> to remove
* @throws IOException
*/
@AtMostOnce
void removeXAttr(String src, XAttr xAttr) throws IOException;
/**
* Checks if the user can access a path. The mode specifies which access
* checks to perform. If the requested permissions are granted, then the
* method returns normally. If access is denied, then the method throws an
* {@link org.apache.hadoop.security.AccessControlException}.
* In general, applications should avoid using this method, due to the risk of
* time-of-check/time-of-use race conditions. The permissions on a file may
* change immediately after the access call returns.
*
* @param path Path to check
* @param mode type of access to check
* @throws org.apache.hadoop.security.AccessControlException if access is
* denied
* @throws java.io.FileNotFoundException if the path does not exist
* @throws IOException see specific implementation
*/
@Idempotent
@ReadOnly(isCoordinated = true)
void checkAccess(String path, FsAction mode) throws IOException;
/**
* Get the highest txid the NameNode knows has been written to the edit
* log, or -1 if the NameNode's edit log is not yet open for write. Used as
* the starting point for the inotify event stream.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
long getCurrentEditLogTxid() throws IOException;
/**
* Get an ordered list of batches of events corresponding to the edit log
* transactions for txids equal to or greater than txid.
*/
@Idempotent
@ReadOnly(isCoordinated = true)
EventBatchList getEditsFromTxid(long txid) throws IOException;
/**
* Set an erasure coding policy on a specified path.
* @param src The path to set policy on.
* @param ecPolicyName The erasure coding policy name.
*/
@AtMostOnce
void setErasureCodingPolicy(String src, String ecPolicyName)
throws IOException;
/**
* Add Erasure coding policies to HDFS. For each policy input, schema and
* cellSize are musts, name and id are ignored. They will be automatically
* created and assigned by Namenode once the policy is successfully added, and
* will be returned in the response.
*
* @param policies The user defined ec policy list to add.
* @return Return the response list of adding operations.
* @throws IOException
*/
@AtMostOnce
AddErasureCodingPolicyResponse[] addErasureCodingPolicies(
ErasureCodingPolicy[] policies) throws IOException;
/**
* Remove erasure coding policy.
* @param ecPolicyName The name of the policy to be removed.
* @throws IOException
*/
@AtMostOnce
void removeErasureCodingPolicy(String ecPolicyName) throws IOException;
/**
* Enable erasure coding policy.
* @param ecPolicyName The name of the policy to be enabled.
* @throws IOException
*/
@AtMostOnce
void enableErasureCodingPolicy(String ecPolicyName) throws IOException;
/**
* Disable erasure coding policy.
* @param ecPolicyName The name of the policy to be disabled.
* @throws IOException
*/
@AtMostOnce
void disableErasureCodingPolicy(String ecPolicyName) throws IOException;
/**
* Get the erasure coding policies loaded in Namenode, excluding REPLICATION
* policy.
*
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
ErasureCodingPolicyInfo[] getErasureCodingPolicies() throws IOException;
/**
* Get the erasure coding codecs loaded in Namenode.
*
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
Map<String, String> getErasureCodingCodecs() throws IOException;
/**
* Get the information about the EC policy for the path. Null will be returned
* if directory or file has REPLICATION policy.
*
* @param src path to get the info for
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
ErasureCodingPolicy getErasureCodingPolicy(String src) throws IOException;
/**
* Unset erasure coding policy from a specified path.
* @param src The path to unset policy.
*/
@AtMostOnce
void unsetErasureCodingPolicy(String src) throws IOException;
/**
* Verifies if the given policies are supported in the given cluster setup.
* If not policy is specified checks for all enabled policies.
* @param policyNames name of policies.
* @return the result if the given policies are supported in the cluster setup
* @throws IOException
*/
@Idempotent
@ReadOnly
ECTopologyVerifierResult getECTopologyResultForPolicies(String... policyNames)
throws IOException;
/**
* Get {@link QuotaUsage} rooted at the specified directory.
*
* Note: due to HDFS-6763, standby/observer doesn't keep up-to-date info
* about quota usage, and thus even though this is ReadOnly, it can only be
* directed to the active namenode.
*
* @param path The string representation of the path
*
* @throws AccessControlException permission denied
* @throws java.io.FileNotFoundException file <code>path</code> is not found
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>path</code>
* contains a symlink.
* @throws IOException If an I/O error occurred
*/
@Idempotent
@ReadOnly(activeOnly = true)
QuotaUsage getQuotaUsage(String path) throws IOException;
/**
* List open files in the system in batches. INode id is the cursor and the
* open files returned in a batch will have their INode ids greater than
* the cursor INode id. Open files can only be requested by super user and
* the the list across batches are not atomic.
*
* @param prevId the cursor INode id.
* @throws IOException
*/
@Idempotent
@Deprecated
@ReadOnly(isCoordinated = true)
BatchedEntries<OpenFileEntry> listOpenFiles(long prevId) throws IOException;
/**
* List open files in the system in batches. INode id is the cursor and the
* open files returned in a batch will have their INode ids greater than
* the cursor INode id. Open files can only be requested by super user and
* the the list across batches are not atomic.
*
* @param prevId the cursor INode id.
* @param openFilesTypes types to filter the open files.
* @param path path to filter the open files.
* @throws IOException
*/
@Idempotent
@ReadOnly(isCoordinated = true)
BatchedEntries<OpenFileEntry> listOpenFiles(long prevId,
EnumSet<OpenFilesType> openFilesTypes, String path) throws IOException;
/**
* Get HA service state of the server.
*
* @return server HA state
* @throws IOException
*/
@Idempotent
@ReadOnly
HAServiceProtocol.HAServiceState getHAServiceState() throws IOException;
/**
* Called by client to wait until the server has reached the state id of the
* client. The client and server state id are given by client side and server
* side alignment context respectively. This can be a blocking call.
*
* @throws IOException
*/
@Idempotent
@ReadOnly(activeOnly = true)
void msync() throws IOException;
/**
* Satisfy the storage policy for a file/directory.
* @param path Path of an existing file/directory.
* @throws AccessControlException If access is denied.
* @throws org.apache.hadoop.fs.UnresolvedLinkException if <code>src</code>
* contains a symlink.
* @throws java.io.FileNotFoundException If file/dir <code>src</code> is not
* found.
* @throws org.apache.hadoop.hdfs.server.namenode.SafeModeException append not
* allowed in safemode.
*/
@AtMostOnce
void satisfyStoragePolicy(String path) throws IOException;
}
这么多方法我们是无法一一分析的,我们可以分下类:
- HDFS文件读相关的操作。
- HDFS文件写以及追加写的相关操作。
- 管理HDFS命名空间的相关操作。
- 系统问题与管理相关的操作。
- 快照相关的操作。
- 缓存相关的操作。
- 其他操作。
读数据相关方法
ClientProtocol中与客户端读取文件相关的方法有两个:getBlockLocations()和reportBadBlocks()。
getBlockLocations()方法可以获取HDFS文件执行范围内所有数据块的位置信息,这个方法的参数是HDFS文件的文件名以及读取范围,返回值是文件指定范围内所有数据块的文件名以及它们的位置信息,使用了LocatedBlocks对象来封装。每个数据块的位置信息指的是存储这个数据块副本的所有DataNode的信息,这些DataNode会以与当前客户端的距离远近排序。在读取到位置信息后,在从返回的数据节点读取真正的信息:
@Idempotent
@ReadOnly(atimeAffected = true, isCoordinated = true)
LocatedBlocks getBlockLocations(String src, long offset, long length)
throws IOException;客户端会调用reportBadBlocks()方法向NameNode汇报错误的数据块,当客户端从数据节点读取数据块且发现数据块的校验和不正确时,就会调用这个方法向NameNode汇报这个错误的数据块信息:
@Idempotent
void reportBadBlocks(LocatedBlock[] blocks) throws IOException;写、追加写数据的相关方法
在HDFS客户端操作中最重要的一个部分就是写入一个新的HDFS文件,或者打开一个已有的HDFS文件并执行追加写操作。ClientProtocol里面定义了8个通俗易懂的方法支持HDFS文件的写操作:create()、append()、addBlock、complete()、abandonBlock()、getAddtionnalDatanodes()、updateBlockForPipeline()和updatePipeline()。
HDFS源码解析系列一——HDFS通信协议的更多相关文章
- HDFS源码解析:教你用HDFS客户端写数据
摘要:终于开始了这个很感兴趣但是一直觉得困难重重的源码解析工作,也算是一个好的开端. 本文分享自华为云社区<hdfs源码解析之客户端写数据>,作者: dayu_dls. 在我们客户端写数据 ...
- 【原】Android热更新开源项目Tinker源码解析系列之三:so热更新
本系列将从以下三个方面对Tinker进行源码解析: Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Android热更新开源项目Tinker源码解析系列之二:资源文件热更新 A ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
- 【原】Android热更新开源项目Tinker源码解析系列之二:资源文件热更新
上一篇文章介绍了Dex文件的热更新流程,本文将会分析Tinker中对资源文件的热更新流程. 同Dex,资源文件的热更新同样包括三个部分:资源补丁生成,资源补丁合成及资源补丁加载. 本系列将从以下三个方 ...
- Cwinux源码解析系列
Cwinux源码解析系列
- 【安卓网络请求开源框架Volley源码解析系列】定制自己的Request请求及Volley框架源码剖析
通过前面的学习我们已经掌握了Volley的基本用法,没看过的建议大家先去阅读我的博文[安卓网络请求开源框架Volley源码解析系列]初识Volley及其基本用法.如StringRequest用来请求一 ...
- TiKV 源码解析系列文章(三)Prometheus(上)
本文为 TiKV 源码解析系列的第三篇,继续为大家介绍 TiKV 依赖的周边库 rust-prometheus,本篇主要介绍基础知识以及最基本的几个指标的内部工作机制,下篇会介绍一些高级功能的实现原理 ...
- TiKV 源码解析系列 - Raft 的优化
本系列文章主要面向 TiKV 社区开发者,重点介绍 TiKV 的系统架构,源码结构,流程解析.目的是使得开发者阅读之后,能对 TiKV 项目有一个初步了解,更好的参与进入 TiKV 的开发中.本文是本 ...
- Android源码解析系列
转载请标明出处:一片枫叶的专栏 知乎上看了一篇非常不错的博文:有没有必要阅读Android源码 看完之后痛定思过,平时所学往往是知其然然不知其所以然,所以为了更好的深入Android体系,决定学习an ...
随机推荐
- DB2给表批量赋权
使用DB2的for循环语句给表批量赋权,同理,稍加修改可作为其他批量操作. 值得注意的是: grant语句无法直接执行,需要使用execute immediate才能执行. 授权操作表的所有权限:gr ...
- Pytest_allure报告(11)
一.allure工具环境配置 windows安装allure 1.下载allure工具包 进入工具包官网:https://github.com/allure-framework/allure2/rel ...
- java 使用 ArrayList 排序【包括数字和字符串】
1.数字排序 /** * 数字排序 */ @Test public void t2() { List<Integer> list = new ArrayList<>(); li ...
- 微信小程序配置域名的时候提示“校验文件验证失败”
在微信小程序后台配置web-view的业务域名跟扫普通链接二维码打开小程序两项功能时, 一直提示"校验文件验证失败,请下载校验文件,上传到服务器指定的目录" 实际访问校验文件的路径 ...
- [login] 调用失败 Error: errCode: -404011 cloud function execution error | errMsg: cloud.callFunction:fail requestID , cloud function service error code -501000, error message Environment not found;
按照微信开放文档,创建完云开发项目,运行,点击获取openid,报如下错: [login] 调用失败 Error: errCode: -404011 cloud function execution ...
- Spring循环依赖原理
Spring循环依赖的原理解析 1.什么是循环依赖? 我们使用Spring的时候,在一个对象中注入另一个对象,但是另外的一个对象中也包含该对象.如图: 在Student中包含了teacher的一个 ...
- leetcode 83. 删除排序链表中的重复元素 及 82. 删除排序链表中的重复元素 II
83. 删除排序链表中的重复元素 问题描述 给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次. 示例 1: 输入: 1->1->2 输出: 1->2 示例 2: 输入: ...
- [JavaWeb]反序列化分析(二)--CommonCollections1
反序列化分析(二)--CommonCollections1 链子分析 首先新建一个TransformedMap,其中二三参数为可控,后续要用到 当TransformedMap执行put方法时,会分别执 ...
- synergy最佳解决方案——barrier
synergy最佳解决方案--barrier 不知道大家有没有一套键盘鼠标控制多台电脑的需求,主流的硬件或说软件有大神整理如下: 软件方案: Windows 之间:Mouse Without Bo ...
- gorm中的scope
作用域允许您重用常用逻辑,共享逻辑需要定义为类型 func(*gorm.DB) *gorm.DB 查询 func Scope1(db *gorm.DB) *gorm.DB { return db.Wh ...