RDD的缓存
RDD的缓存/持久化
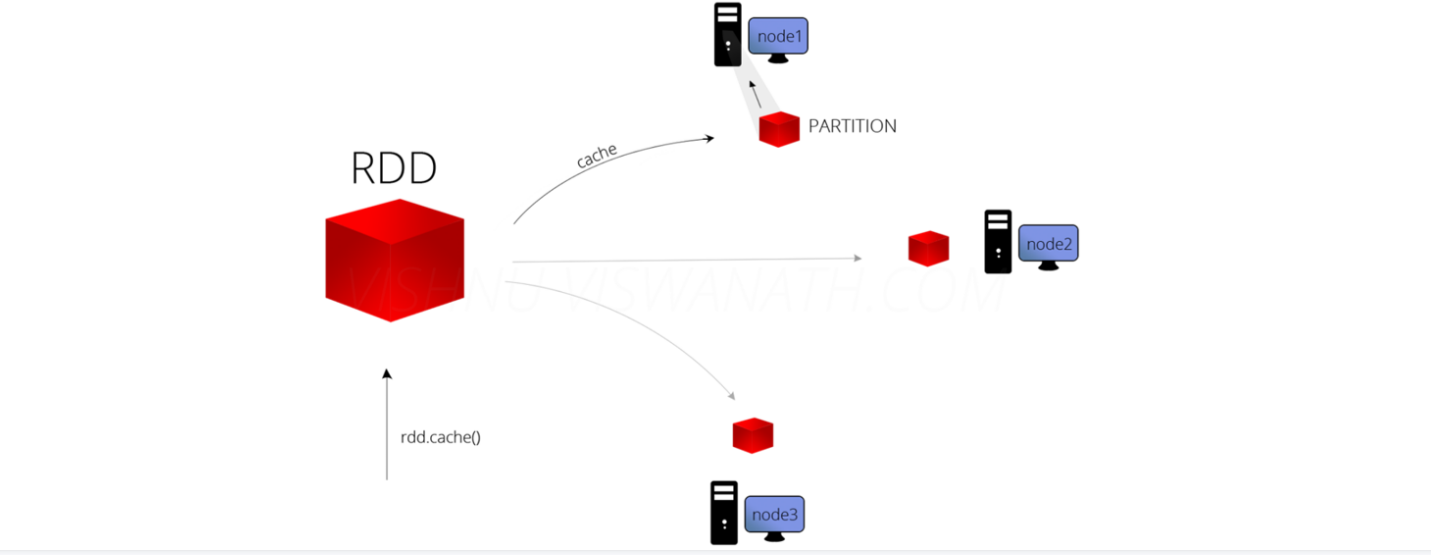
缓存解决的问题
缓存解决什么问题?-解决的是热点数据频繁访问的效率问题
在Spark开发中某些RDD的计算或转换可能会比较耗费时间,
如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,
这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo16Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("****").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
//加入缓存的三种方式
//方式一
linesRDD.cache()//将常用的RDD放入缓存中,增加效率
//StorageLevel.MEMORY_ONLY 默认只放在缓存中
//方式二
//linesRDD.persist()
//def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
//指定缓存存储方式
linesRDD.persist(StorageLevel.MEMORY_AND_DISK)
/**
* 缓存的存储方式:推荐使用MEMORY_AND_DISK
* object StorageLevel {
* val NONE = new StorageLevel(false, false, false, false)
* val DISK_ONLY = new StorageLevel(true, false, false, false)
* val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
* val MEMORY_ONLY = new StorageLevel(false, true, false, true)
* val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
* val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
* val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
* val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
* val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
* val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
* val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
* val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
*/
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
//释放缓存
linesRDD.unpersist()
}
}
RDD中的checkpoint
RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
也可以把数据放在磁盘上,也并不是完全可靠的,
我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object Demo17CheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
/**
* RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
* 也可以把数据放在磁盘上,也并不是完全可靠的
* 我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
*
*/
//设置HDFS的目录
sc.setCheckpointDir("spark/data/checkPoint")
//对需要缓存的RDD进行checkPoint
linesRDD.checkpoint()
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
}
}
RDD的缓存的更多相关文章
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- RDD(八)——缓存与检查点
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中. 但是并不是这两个方法被调用时立即缓存,而是触发 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- RDD缓存
RDD的缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存数据集.当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他 ...
- Spark RDD详解 | RDD特性、lineage、缓存、checkpoint、依赖关系
RDD(Resilient Distributed Datasets)弹性的分布式数据集,又称Spark core,它代表一个只读的.不可变.可分区,里面的元素可分布式并行计算的数据集. RDD是一个 ...
- RDD:基于内存的集群计算容错抽象(转)
原文:http://shiyanjun.cn/archives/744.html 该论文来自Berkeley实验室,英文标题为:Resilient Distributed Datasets: A Fa ...
- Spark RDD Operations(2)
处理数据类型为Value型的Transformation算子可以根据RDD变换算子的输入分区与输出分区关系分为以下几种类型. 1)输入分区与输出分区一对一型. 2)输入分区与输出分区多对一型. 3)输 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
随机推荐
- python3中文乱码解决方法
解决方法: 修改pycharm配置: File->Settings->Editor->File encodings 把Global encoding设置成GBK即可
- P4424-[HNOI/AHOI2018]寻宝游戏【结论】
正题 题目链接:https://www.luogu.com.cn/problem/P4424 题目大意 \(n\)个\(m\)位二进制数,开始是一个\(0\). 然后依次对所有二进制数进行\(n\)次 ...
- mqtt网关服务器连接阿里云关联物模型
mqtt网关服务器连接阿里云关联物模型 卓岚专门为工业环境设计的RS485设备数据采集器/物联网网关,兼具串口服务器.Modbus网关.MQTT网关.RS485转JSON等多种功能于一体. 可以连接阿 ...
- mysql从零开始之MySQL 安装
MySQL 安装 所有平台的 MySQL 下载地址为: MySQL 下载 . 挑选你需要的 MySQL Community Server 版本及对应的平台. 注意:安装过程我们需要通过开启管理员权限来 ...
- enum 试图表达64位数
enum AttributeType: unsigned long long{ aa = 1, bb = 2, cc = 0x842AC1040000}; int main() { DWORD64 b ...
- The Data Way Vol.3|做到最后只能删库跑路?DBA 能做的还有很多
关于「The Data Way」 「The Data Way」是由 SphereEx 公司出品的一档播客节目.这里有开源.数据.技术的故事,同时我们关注开发者的工作日常,也讨论开发者的生活日常:我们聚 ...
- WEB 标准以及 W3C 的理解与认识
01. WEB标准 ① web标准 简单来说可以分为结构.表现和行为. ② 结构:主要是有HTML标签组成(通俗点说,在页面body里面我们写入的标签都是为了页面的结构) 表现:即指css样 ...
- uoj22 外星人(dp)
题目大意: 给定一个\(n\)个数的序列\(a\),给定一个\(x\),其中\(a\)数组可以进行顺序的调换,每一个\(a_i\)都能使$x=x \mod a_i \(, 求最后经过一系列计算后的\) ...
- 2020.5.4-ICPC Pacific Northwest Regional Contest 2019
A. Radio Prize All boring tree-shaped lands are alike, while all exciting tree-shaped lands are exci ...
- 初学python-day6 for循环和流程控制(已更新循环做三角形图形!!)
for循环 1.格式 for 变量 in 集合: 循环体 2.概述 当程序执行for循环,按顺序从集合中获取元素变量保存当前循环得到的值,再去执行循环体.当集合中数据都被取完,则此刻跳 ...