Erda MSP 系列 - 以服务观测为中心的 APM 系统设计:开篇词
本文首发于 Erda 技术团队知乎账号,更多技术文章可点击 Erda 技术团队
作者:刘浩杨,端点科技 PaaS 技术专家,微服务治理和监控平台负责人,Apache SkyWalking PMC成员
原文链接:https://zhuanlan.zhihu.com/p/367779900
前言
Erda Cloud 是我们即将发布的一站式开发者云平台,为企业开发团队提供 DevOps (DevOps Platform, DOP )、微服务治理 (MicroService Platform,MSP )、多云管理 (Cloud Management Platform,CMP ) 以及快数据管理 (FastData Platform,FDP ) 等云原生服务。
作为 Erda Cloud 中的核心平台,MSP 提供了托管的微服务解决方案,包括 API 网关、注册中心、配置中心、应用监控和日志服务等,来帮助用户解决业务系统进行微服务化而带来技术复杂度难题。伴随着产品的升级,我们也全新设计了以服务观测为中心的 APM (应用性能监控) 产品,探索可观测性在应用监控领域中落地的最佳实践。
为了让大家更好的了解 MSP 中 APM 系统的设计实现,我们将编写一个系列专题,深入 APM 系统的产品、架构设计和基础技术。这是该专题的第一篇,将通过分享我们在可观测性上的一些思考来开启这个专题的序章。
从监控到可观测性
随着近年来云原生概念和云原生架构设计的流行,越来越多的开发团队开始使用 DevOps 模式进行系统开发,并把大型系统拆解成一个个微小的服务模块,以便系统能更好的进行容器化部署。基于 DevOps、微服务、容器化等云原生的能力,可以帮助业务团队快速、持续、可靠和规模化地交付系统,同时也使得系统的复杂度成倍提升,由此带来前所未有的运维挑战,比如:
• 模块之间的调用从进程内的函数调用变为进程间的调用,而网络总是不可靠的
• 服务的调用路径变长,使得流量的走向变得不可控,故障排查的难度增大
• 引入 Kubernetes、Docker、Service Mesh 等云原生系统,基础设施层对业务开发团队来说变得更加黑盒
在传统的监控系统中,我们往往会关注虚拟机的 CPU、内存、网络、应用服务的接口请求量、资源使用率等指标,但在复杂的云原生系统中,仅仅关注单点或者单个维度的指标,并不足以帮助我们掌握系统的整体运行状况。在此背景下,对分布式系统的“可观测性”应运而生。通常,我们认为可观测性相对于过去监控,最大的变化就是系统需要处理的数据,从指标为主,扩展到了更广的领域。综合起来,大约有几类数据被看作是可观测性的支柱:
• Metrics
• Tracing
• Logging
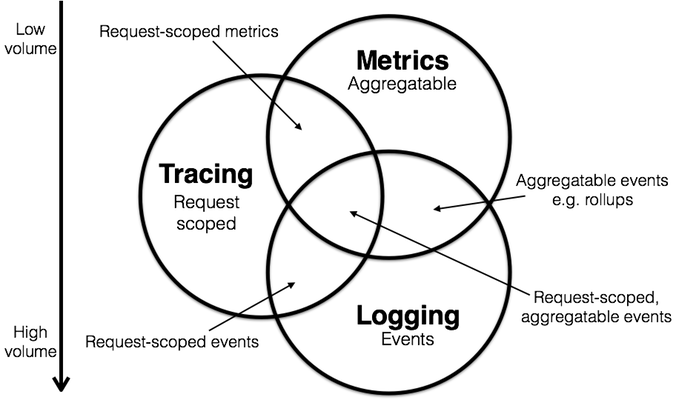
为了统一可观测性系统中的数据采集和标准规范,同时提供与供应商无关的接口,CNCF 把 OpenTracing 和 OpenCensus 合并成 OpenTelemetry 项目。OpenTelemetry 通过 Spec 规范了观测数据的数据模型以及采集、处理、导出方法,但对于数据如何去使用、存储、展示和告警是不涉及的,官方目前的推荐方案是:
• 使用 Prometheus 和 Grafana 做 Metrics 的存储和展示
• 使用 Jaeger 做分布式追踪的存储和展示
得益于云原生开源生态的蓬勃发展,技术团队可以轻而易举建设一套监控体系,比如使用 Prometheus + Grafana 搭建基础监控,使用 SkyWalking 或 Jaeger 搭建追踪系统,使用 ELK 或 Loki 搭建日志系统。但对于可观测性系统的用户来说,不同类型的观测数据分散存储在不同的后端,排查问题仍需要在多个系统之间跳转,效率和用户体验都得不到保证。为解决可观测性数据的融合存储和分析,我们自研的统一存储和查询引擎,提供了指标、追踪和日志数据的无缝关联分析。在本文的其他部分,将详细介绍我们是如何提供针对服务的可观测性分析能力。
观测的入口:可观测性拓扑
可观测性提出了三种数据之间的关系,让我们可以使用标签关联 Metrics 和 Tracing,使用请求上下文去打通 Tracing 和 Log。因此,通常可以使用下面的方法去定位线上应用系统的接口异常:使用 Metrics 和 告警发现问题,然后使用 Tracing 定位到可能发生异常的模块,最后使用 Logging 定位到错误根源。
虽然在大多数时间里这个方法是行之有效的,但我们并不认为这是一个对系统进行观测的最佳实践:
• 虽然基于 Metrics 可以帮助我们及时发现问题,但往往我们发现的是大量单点问题,没有一个全局的视角来观测整个系统的状态
• 业务开发团队需要去熟悉 Metrics、Tracing 和 Logging 系统的各种概念和使用。如果基于开源组件搭配的监控系统,还需要在各个系统之间不断跳转才能完成一次问题的排查,这在今天很多公司里是经常见的
我们在不同领域用户的监控需求的实践中,发现拓扑可以天然的作为观测系统的入口。不同于常见的分布式追踪平台,我们不仅仅把拓扑作为应用系统的运行时架构展示,在基于 100% 采样的真实请求关系绘制出拓扑后,更进一步在拓扑节点上透出服务的请求和服务实例状态(未来还会透出更多的观测数据,比如流量比例、物理节点的状态等)。
在拓扑页面的布局上,我们把页面切分为左右两栏,右边的状态栏会显示我们需要观测的系统关键指标,如服务实例数、服务的错误请求、代码异常和告警次数等。当我们点击拓扑节点时,状态栏会检测节点类型的不同而显示不同的状态数据。当前我们支持展示状态的节点类型有 API Gateway、服务、外部服务和中间件。
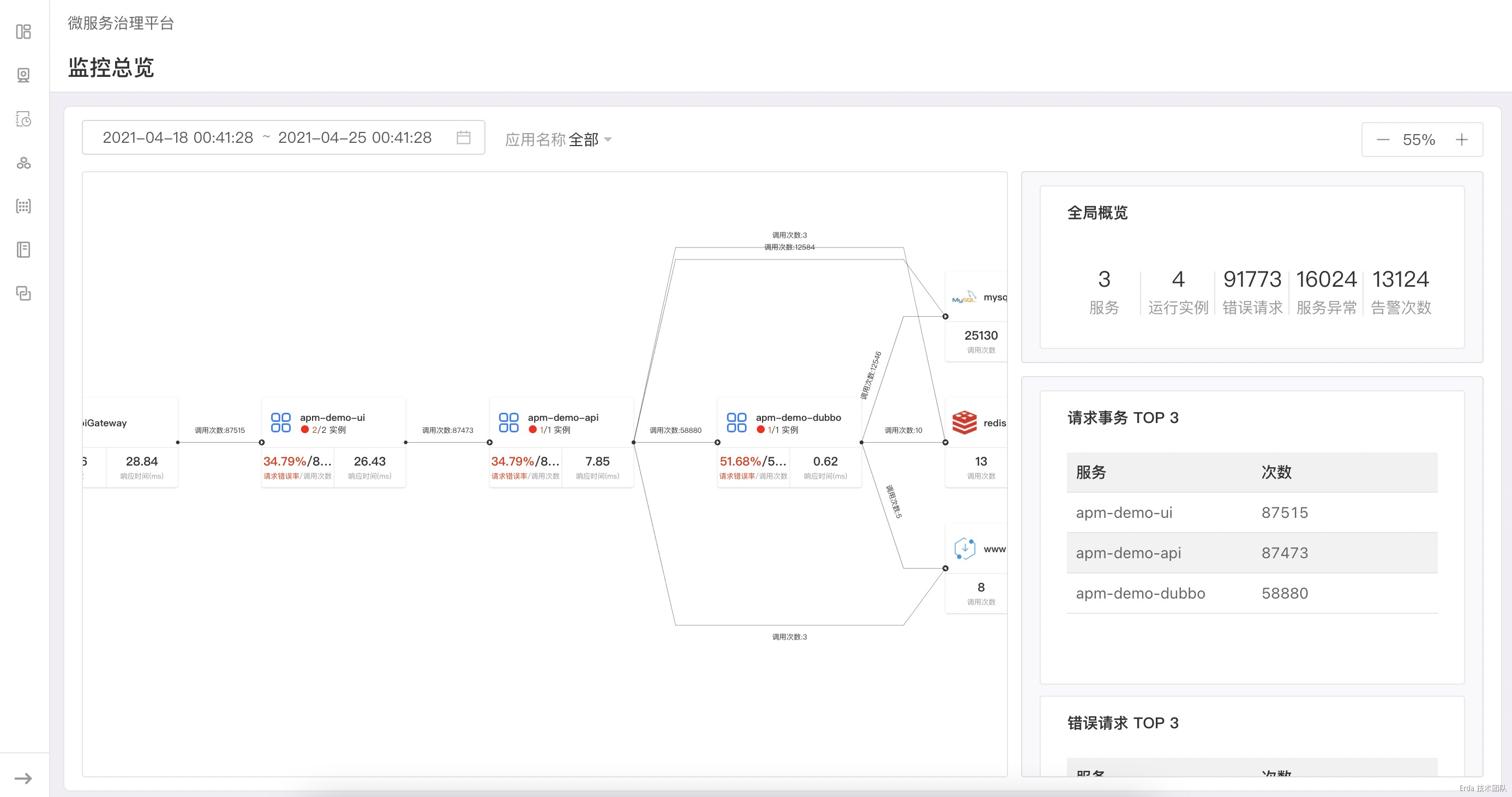
当点击服务节点时,状态栏会显示服务的状态概览、事务调用概览和 QPS 折线图
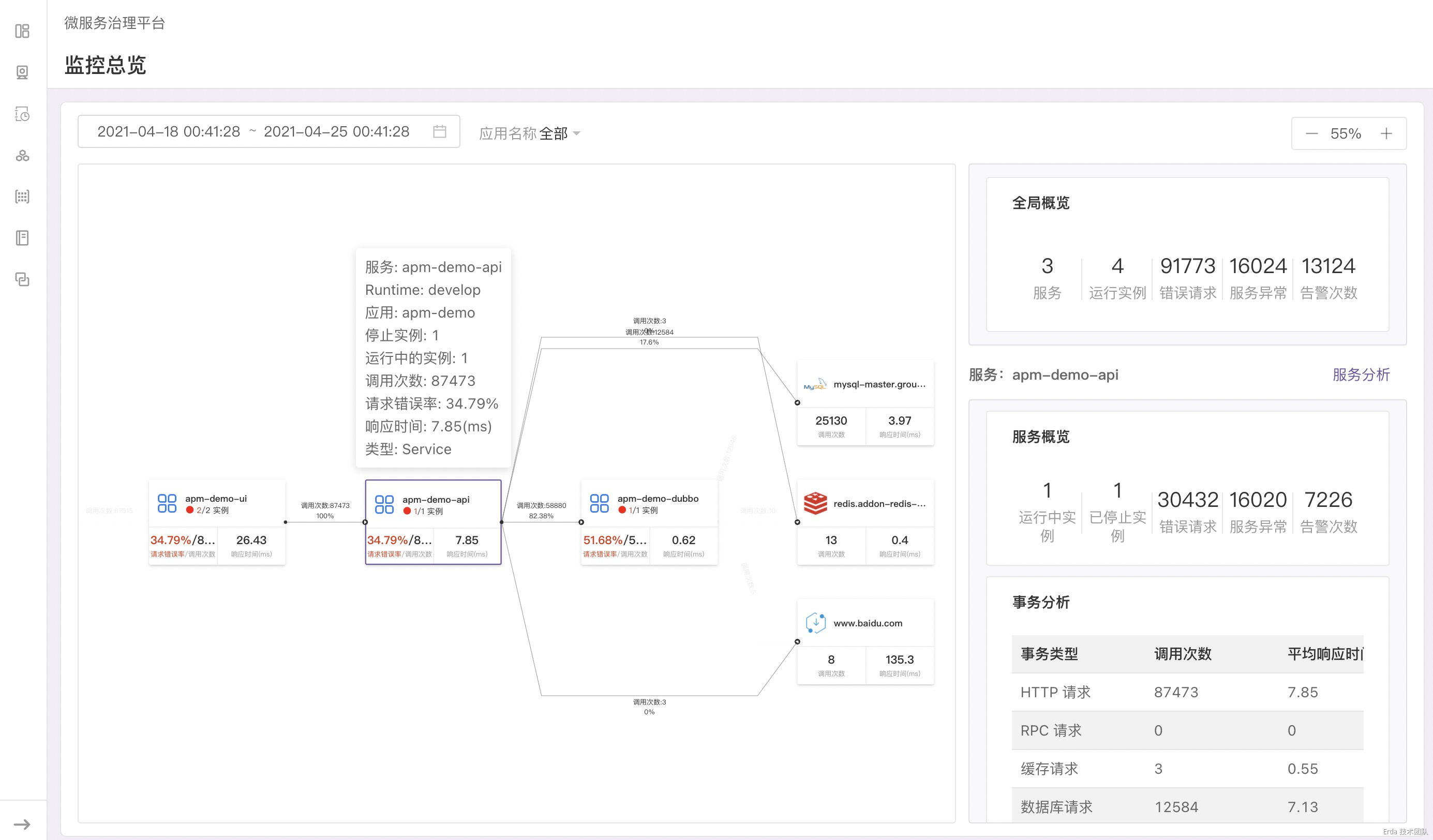
再进一步:如何观测服务
基于可观测拓扑,我们可以很容易在全局的视角下观察系统的整体状态,同时我们还提供了一种从拓扑下钻到服务以便快速定位服务故障的观测方式。当发现服务异常时,我们允许链接到服务分析,在该页面提供了事务、异常和进程三个维度的观测分析。
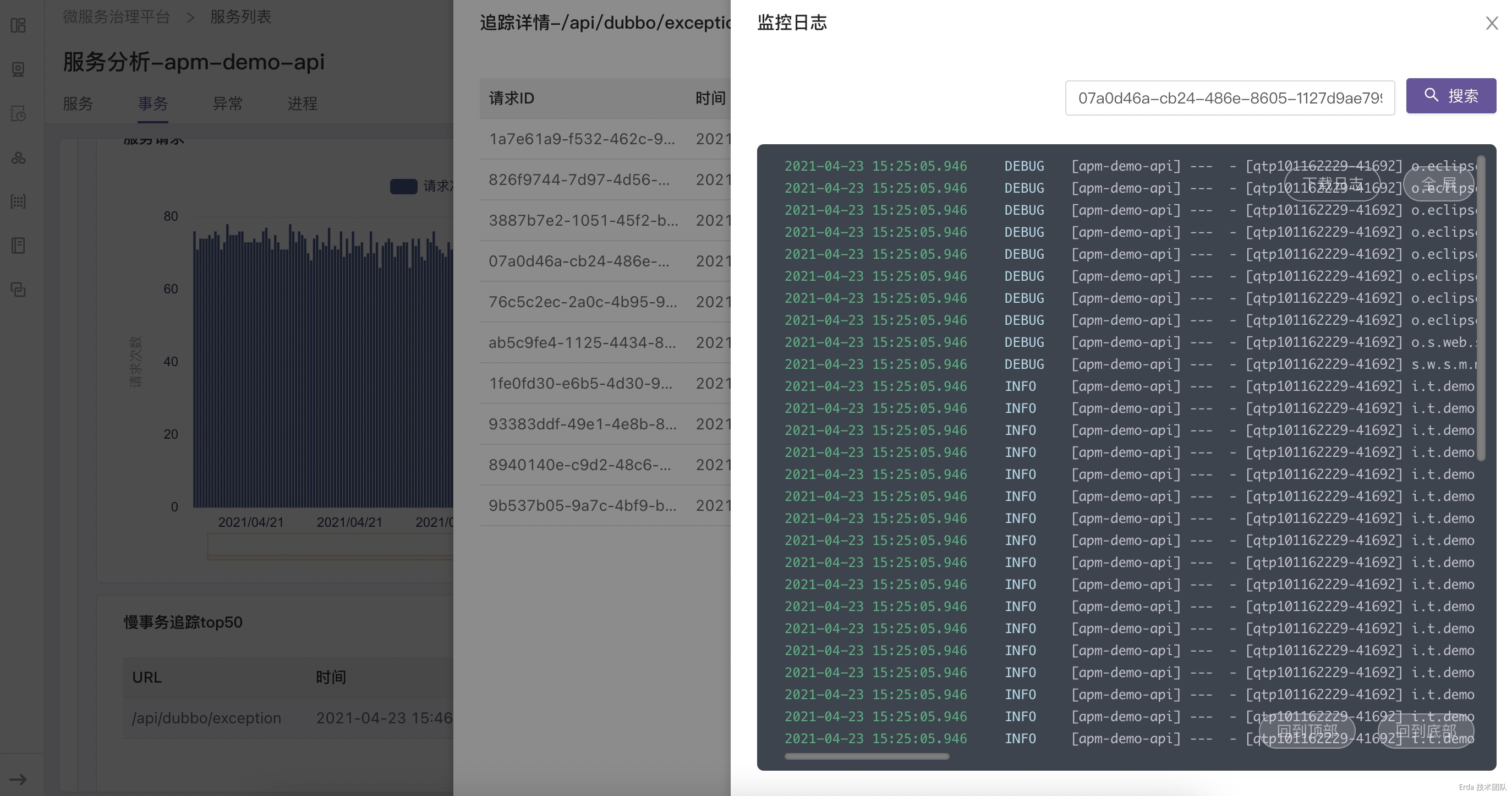
拿上面提到的接口异常为例,我们的故障排查方式为:在事务分析页查询触发异常的接口 */exception ,然后点击请求或延迟趋势图上的数据点关联接口采样到的慢事务追踪和错误事务追踪,在弹出的追踪列表中查看请求链路详情和请求关联的日志定位错误根源。
找到故障的事务请求
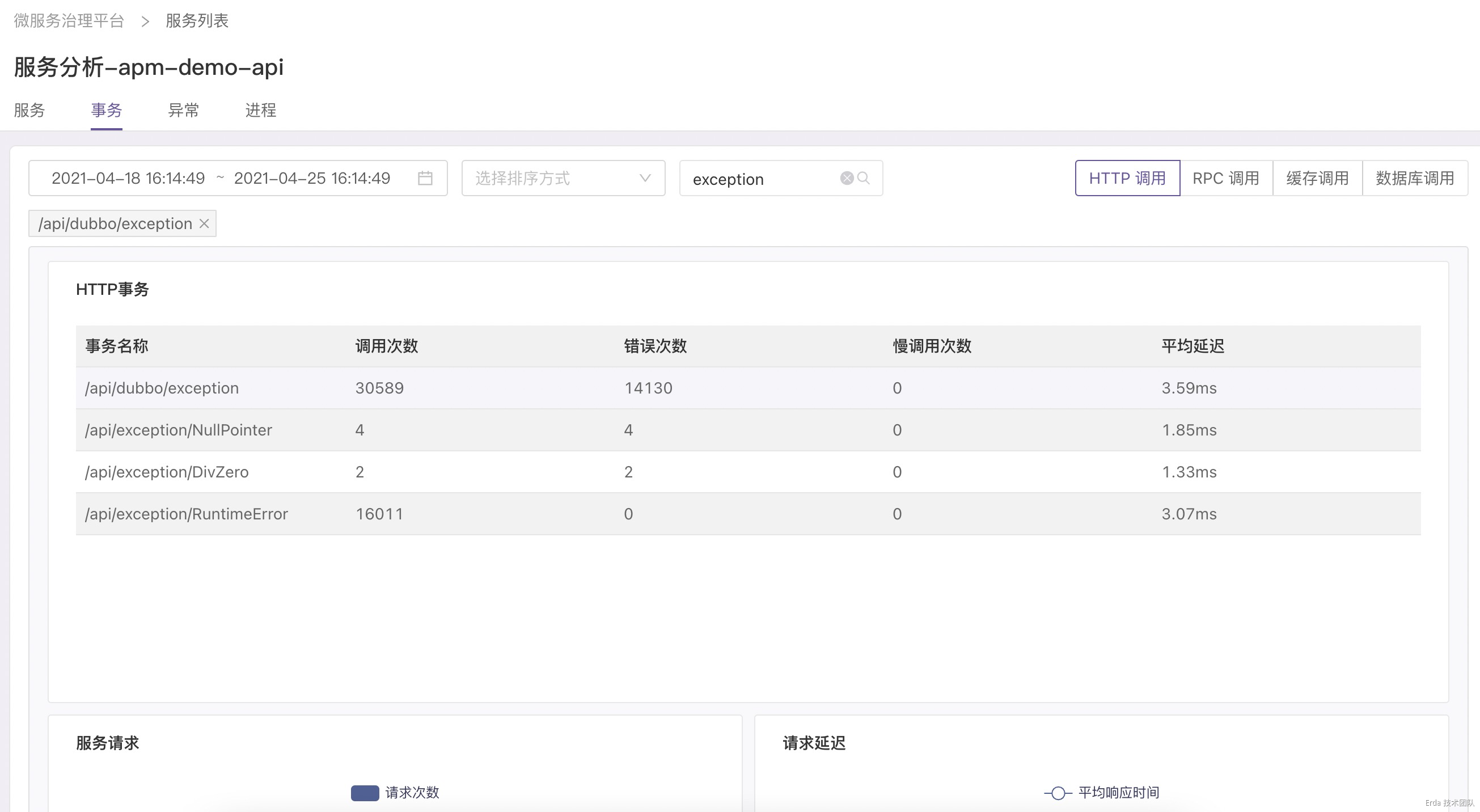
自动关联该请求的调用链路
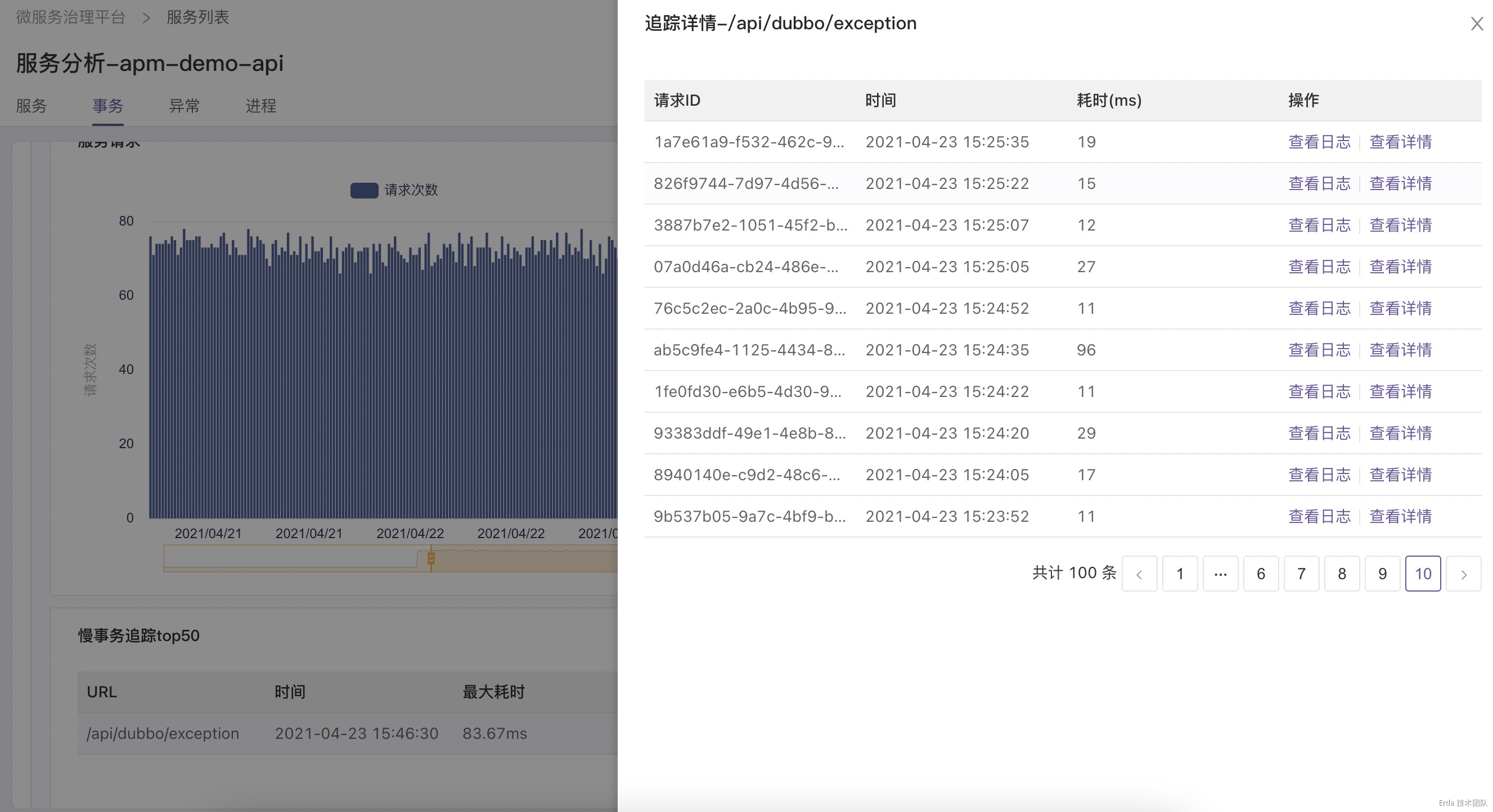
为请求链路自动关联日志上下文
结语:我们要走向哪里
基于本文篇幅的限制不再过多的去展示产品细节,我们借助上面的场景抛砖引玉提出一个可观测性 APM 产品设计的方向:基于系统和服务观测的角度把不同数据在后端融合分析,而不是刻意强调系统支持可观测性三种数据的分别查询,在产品功能和交互逻辑上尽可能对用户屏蔽 Metrics、Tracing、Logging 的割裂。除此之外,我们也将继续探索代码级诊断、全链路分析和智能运维在可观测性领域的无限可能性。
附:专题目录
产品篇
- 我们如何定义 APM
- 数据大盘,随心所欲
- 你需要什么样的告警产品
- 彻底打通监控和日志的边界
基础技术篇
- 详解 Metrics , Tracing 和 Logging
- 剖析 Java Agent
- NodeJS 的自动探针实现
- 浏览器探针知多少
- 可扩展 Telegraf
- 容器化日志采集的实践
- 流消息的处理利器: Kafka
- 基于 Flink 实现实时计算
- 为什么我们需要时序数据库
- ElasticSearch 在时序数据场景的应用
- 了解高性能NoSQL: Cassandra
架构设计篇
- 异构系统的可观测数据采集架构设计
- 流分析和告警引擎架构设计
- 查询计算和存储分离的弹性监控架构设计
参考
《DevOps专题 |监控,可观测性与数据存储》
《Metrics, tracing 和 logging 的关系》
Erda MSP 系列 - 以服务观测为中心的 APM 系统设计:开篇词的更多相关文章
- 极速体验|使用 Erda 微服务观测接入 Jaeger Trace
在大型网站系统设计中,随着分布式架构,特别是微服务架构的流行,我们将系统解耦成更小的单元,通过不断的添加新的.小的模块或者重用已经有的模块来构建复杂的系统.随着模块的不断增多,一次请求可能会涉及到十几 ...
- SpringCloud系列——Feign 服务调用
前言 前面我们已经实现了服务的注册与发现(请戳:SpringCloud系列——Eureka 服务注册与发现),并且在注册中心注册了一个服务myspringboot,本文记录多个服务之间使用Feign调 ...
- 微服务---Eureka注册中心(服务治理)
在上一篇的初识SpringCloud微服务中,我们简单讲解到服务的提供者与消费者,当服务多了之后,会存在依赖与管理之间混乱的问题,以及需要对外暴露自己的地址,为了解决此等问题,我们学习Eureka注册 ...
- (九)分布式服务----Zookeeper注册中心
==>>点击查看本系列文章目录 首先看一下几种注册中心: 最老的就是Zookeeper了, 比较新的有Eureka,Consul 都可以做注册中心.可以自行搜索对比三者的优缺点. Zook ...
- Spring Cloud 系列之 Alibaba Nacos 注册中心(二)
本篇文章为系列文章,未读第一集的同学请猛戳这里:Spring Cloud 系列之 Alibaba Nacos 注册中心(一) 本篇文章讲解 Nacos 注册中心集群环境搭建. Nacos 集群环境搭建 ...
- Dubbo系列之服务暴露过程
点赞再看,养成习惯,微信搜一搜[三太子敖丙]关注这个喜欢写情怀的程序员. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的系 ...
- .Net Core with 微服务 - Consul 配置中心
上一次我们介绍了Elastic APM组件.这一次我们继续介绍微服务相关组件配置中心的使用方法.本来打算介绍下携程开源的重型配置中心框架 apollo 但是体系实在是太过于庞大,还是让我爱不起来.因为 ...
- 玩转Windows服务系列——Windows服务小技巧
伴随着研究Windows服务,逐渐掌握了一些小技巧,现在与大家分享一下. 将Windows服务转变为控制台程序 由于默认的Windows服务程序,编译后为Win32的窗口程序.我们在程序启动或运行过程 ...
- 玩转Windows服务系列——Windows服务启动超时时间
最近有客户反映,机房出现断电情况,服务器的系统重新启动后,数据库服务自启动失败.第一次遇到这种情况,为了查看是不是断电情况导致数据库文件损坏,从客户的服务器拿到数据库的日志,进行分析. 数据库工作机制 ...
随机推荐
- 8.Vue组件三---slot插槽
主要内容: 1. 什么是插槽 2. 组件的插槽 3. 插槽的使用方法 4. 插槽的具名 5. 变量的作用域 6. slot的作用域 一. 什么是插槽呢? 1. 生活中的插槽有哪些呢? usb插槽, ...
- CodeBlocks的安装配置以及使用教程
CodeBlocks的安装配置以及使用教程 教程写的很啰嗦,本来几句话就能搞定的,但为了照顾到那部分真正的小白还请大家见谅! 一.下载 前往CodeBlocks官网下载带编译器的版本,目前的最新版本为 ...
- 「视频小课堂」ELK和Kafka是怎么就玩在一起成了日志采集解决方案文字版
视频地址:ELK和Kafka是怎么就玩在一起成了日志采集解决方案 视频文字版 今天呢我就带来了一期视频,主要就是讲ELK和Kafka之间的通讯关系通过对一张通讯图,和一些操作命令,让我们能更深入的去理 ...
- [LeetCode 279.] Perfect Squres
LeetCode 279. Perfect Squres DP 是笨办法中的高效办法,又是一道可以被好办法打败的 DP 题. 题目描述 Given a positive integer n, find ...
- hessian简单介绍
Hessian是基于HTTP的轻量级远程服务解决方案,Hessian像Rmi一样,使用二进制消息进行客户端和服务器端交互.但与其他二进制远程调用技术(例如Rmi)不同的是,它的二进制消息可以移植其他非 ...
- 正则表达式如何直接在EXCEL中使用?
正则表达式,相信大家都不陌生.但在我们最常用的办公软件EXCEL中,目前没有可直接使用正则表达式的函数(至少10版本的EXCEL没有),那么今天我就分享下如何在EXCEL中自定义正则函数. 一.提需求 ...
- Python-tkinter-window
示例代码讲解 1.加载tkinter模块 2.创建一个窗口 3.设置窗口的主题 4.开始窗口的事件循环 import tkinter 2 win = tkinter.Tk() 3 win.title( ...
- 电影AI修复,让重温经典有了新的可能
摘要:有没有一种呈现,不以追求商业为第一目的,不用花大价钱,不用翻拍,没有画蛇添足,低成本的可共赏的让经典更清晰? 本文分享自华为云社区<除了重映和翻拍,重温经典的第三种可能>,原文作者: ...
- C语言结构体及其内存布局
code[class*="language-"], pre[class*="language-"] { color: rgba(51, 51, 51, 1); ...
- 【Azure 应用程序见解】 Application Insights 对App Service的支持问题
问题描述 Web App 发布后, Application Insights 收集不到数据了 问题分析 在应用服务(App Service)中收集应用的监控数据(如Request,Exception, ...