大数据-Hadoop虚拟机的准备以及配置(三台机子)
虚拟机的准备
修改静态IP(克隆的虚拟机)
vim /etc/udev/rules.d/70-persistent-net.rules
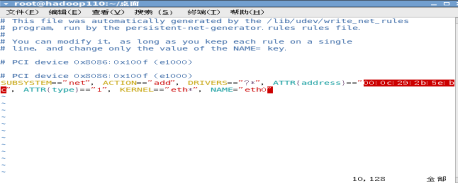
配置网络:
Vim /etc/sysconfig/network-scripts/ifcfg-eth0
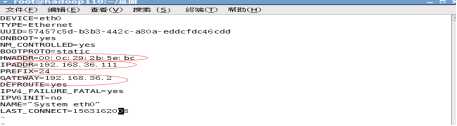
修改主机名
Vim /etc/sysconfig/network

查看主机:vim /etc/hosts
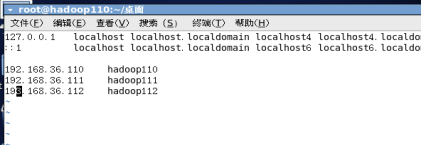
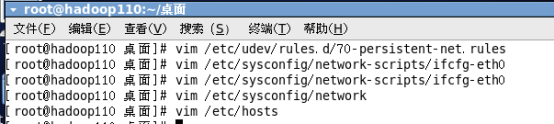
查看是否成功:

关闭防火墙
1. 永久性生效
开启:chkconfig iptables on
关闭:chkconfig iptables off
2. 即时生效,重启后失效
开启:service iptables start
关闭:service iptables stop
创建用户
Useradd xxxx
Passwd xxxx
配置用户具有root权限
vim /etc/sudoers

在opt下面创建一个文件夹software和module(一个放文件,一个挤压文件)
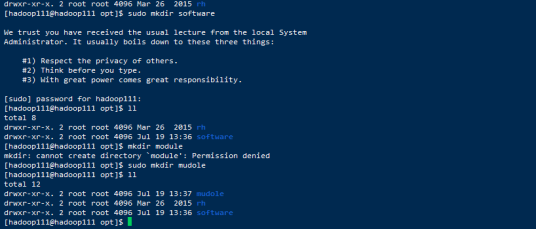
修改文件夹的所有组和所有者
sudo chown hadoop110:hadoop110 module/ software/

安装jdk
(1)查询是否安装Java软件:
[atguigu@hadoop101 opt]$ rpm -qa | grep java

(2)如果安装的版本低于1.7,卸载该JDK:
[atguigu@hadoop101 opt]$ sudo rpm -e 软件包
(3)查看JDK安装路径:
[atguigu@hadoop101 ~]$ which java
- 在Linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop101 opt]$ cd software/
[atguigu@hadoop101 software]$ ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz

- 解压JDK到/opt/module目录下
[atguigu@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/

5. 配置JDK环境变量
(1)先获取JDK路径
[atguigu@hadoop101 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
`
(2)打开/etc/profile文件
[atguigu@hadoop101 software]$ sudo vi /etc/profile
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin

(3)保存后退出
:wq
(4)让修改后的文件生效
[atguigu@hadoop101 jdk1.8.0_144]$ source /etc/profile
6. 测试JDK是否安装成功
[atguigu@hadoop101 jdk1.8.0_144]# java -version
java version "1.8.0_144"
注意:重启(如果java -version可以用就不用重启)
[atguigu@hadoop101 jdk1.8.0_144]$ sync
[atguigu@hadoop101 jdk1.8.0_144]$ sudo reboot
大数据-Hadoop虚拟机的准备以及配置(三台机子)的更多相关文章
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 跟着我一起学习大数据——Hadoop
hadoop配置文件:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.9.0/ 一:Hadoop简介 总结下起源于Nutch项目,社区 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
随机推荐
- SpringMVC Jackson 库解析 json 串属性名大小写自动转换问题
问题描述 在项目开发中,当实体类和表中定义的某个字段为 RMBPrice,首字母是大写的,sql 查询出来的列名也是大写的 RMBPrice,但是使用 jquery 的 ajax 返回请求响应时却出错 ...
- 2.7循环_while
循环 目标 程序的三大流程 while 循环基本使用 break 和 continue while 循环嵌套 01. 程序的三大流程 在程序开发中,一共有三种流程方式: 顺序 -- 从上向下,顺序执行 ...
- VFB FEEDBACK
- Scrum Master 生存指南
近年来,出现了一批新兴且广受关注的岗位,以 Scrum Master 为典型代表.2018年,Scrum Master 的平均工资为98239美元.领英更是将其列为2019年最有前途的工作之一.但对于 ...
- 阿里云服务器安装Docker并部署nginx、jdk、redis、mysql
阿里云服务器安装Docker并部署nginx.jdk.redis.mysql 一.安装Docker 1.安装Docker的依赖库 yum install -y yum-utils device-map ...
- .Net Redis实战——实现文章投票并排序
本系列文章为学习Redis实战一书记录的随笔. 软件和环境版本:Redis:5.0.7 .Net 5.0 文中不会对Redis基础概念做过多介绍. Redis数据类型和命令可在菜鸟教程学习:http ...
- docker容器与镜像的区别
今天抛开原理,抛开底层.通俗的讲解docker中容器与镜像的区别. 对于初学者来说,刚刚接触docker会有点迷,特别是镜像与容器.其实我们可以理解镜像与容器为一对多的关系. 下图错误的示范,为什么是 ...
- 看懂redis配置文件
看懂redis 配置文件: https://blog.csdn.net/liqingtx/article/details/60330555 redis 数据库缓存双写一致性解决方案: https:// ...
- 【模板】 RMQ求区间最值
RMQ RMQ简单来说就是求区间的最大值(最小值) 核心算法:动态规划 RMQ(以下以求最大值为例) F[i,j]表示 从 i 开始 到i+2j -1这个区间中的最大值 状态转移方程 F[i,j]=m ...
- Java8新特性代码示例(附注释)- 方法引用,Optional, Stream
/** * java8中的函数式接口,java中规定:函数式接口必须只有一个抽象方法,可以有多个非抽象方法,同时,如果继承实现了 * Object中的方法,那么也是合法的 * <p> * ...