hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html
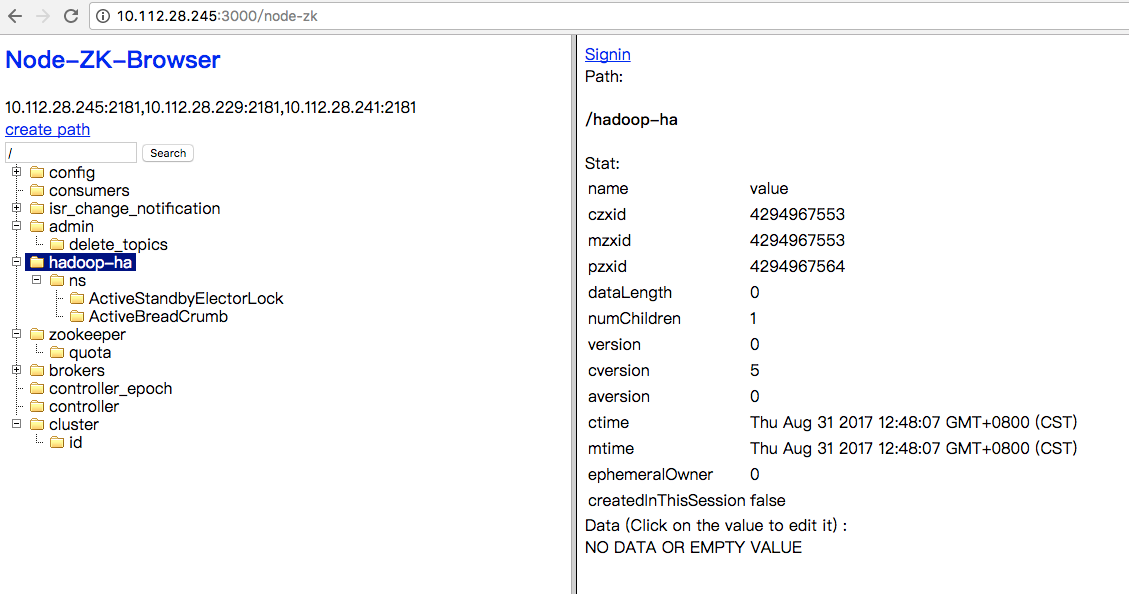
HA集群需要zk, zk搭建:http://www.cnblogs.com/kisf/p/7357184.html zk可视化管理工具:http://www.cnblogs.com/kisf/p/7365690.html
| hostname | ip | 安装软件 | 启动进程 |
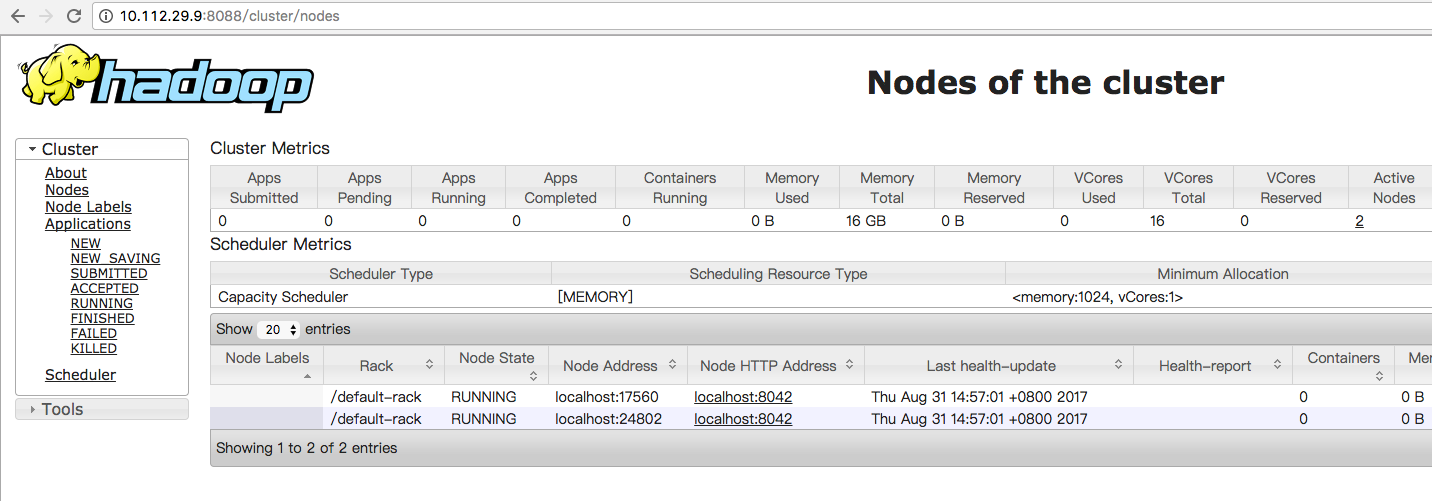
| master1 | 10.112.29.9 | jdk,hadoop | NameNode,ResourceManager,JournalNode,DFSZKFailoverController |
| master2,slave1 | 10.112.29.10 | jdk,hadoop | NameNode,JournalNode,DFSZKFailoverController,DataNode,NodeManager |
| slave2 | 10.112.28.237 | jdk,hadoop | JournalNode,DataNode,NodeManager |
1. 修改/etc/hosts, 三个机器一致。
vim /etc/hosts 10.112.29.9 master1
10.112.29.10 master2
10.112.29.10 slave1
10.112.28.237 slave2
10.112.28.245 zk1
10.112.28.229 zk2
10.112.28.241 zk3
2. 修改core-site.xml, hdfs-site.xml及yarn-site.xml, mapred-site.xml不变。
core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/xxx/soft/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration> <!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property> <!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property> <!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
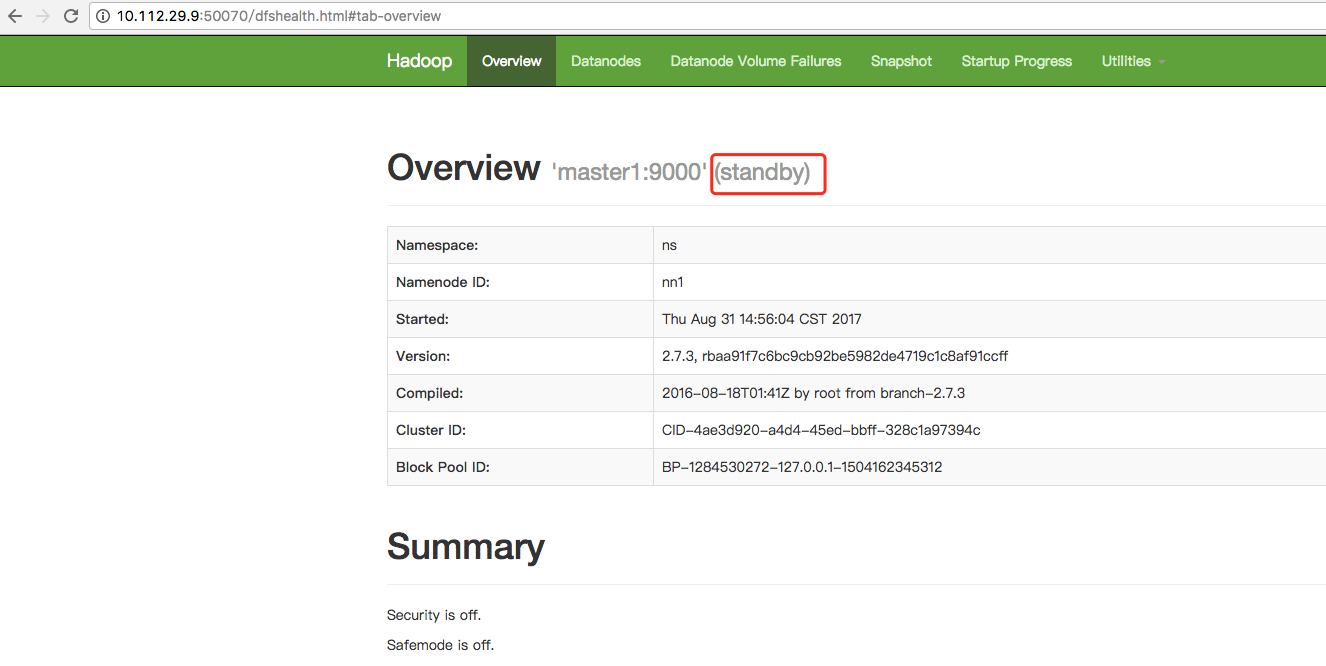
<value>master1:9000</value>
</property> <!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master1:50070</value>
</property> <!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
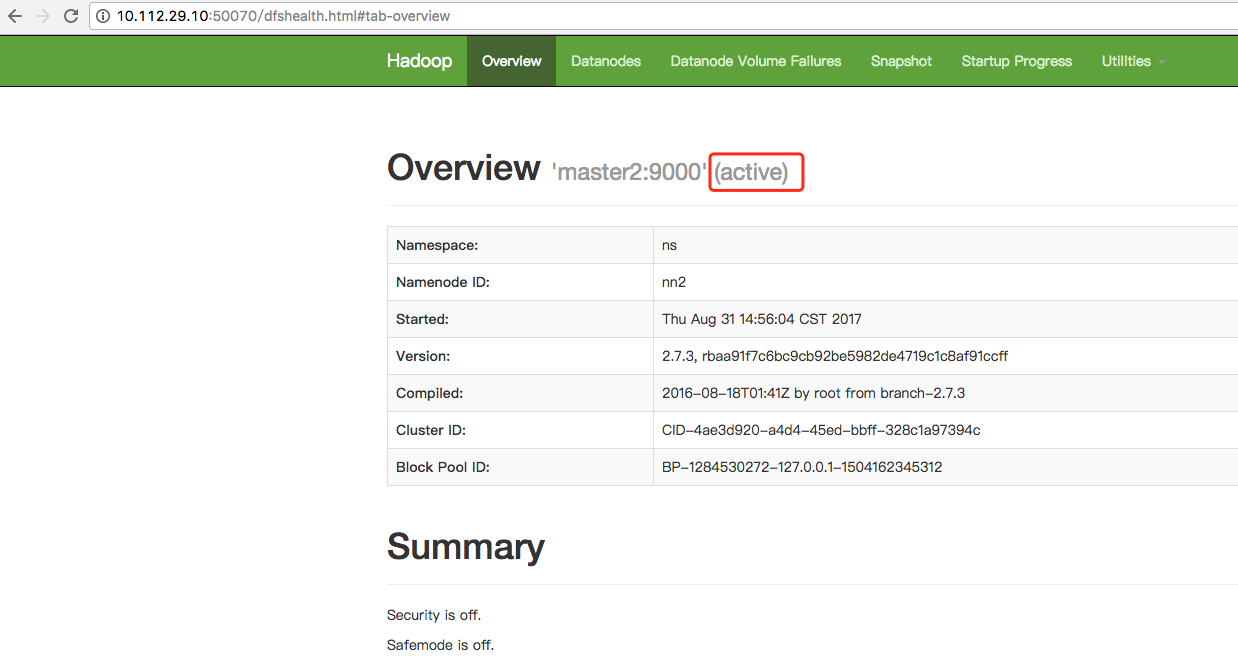
<value>master2:9000</value>
</property> <!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>master2:50070</value>
</property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485/ns</value>
</property> <!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/xxx/soft/hadoop-2.7.3/journal</value>
</property> <!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property> <!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/xxx/soft/hadoop-2.7.3/tmp/name</value>
</property> <!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property> <!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/xxx/soft/hadoop-2.7.3/tmp/data</value>
</property> <!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property> </configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master1</value>
</property> <!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> </configuration>
3. 将/xxx/soft/hadoop-2.7.3 scp至其他机器。注意清理一下 logs, tmp下文件。
4. 启动
(1)格式化zkfc
./bin/hdfs zkfc -formatZK
(2)格式化namenode,格式化namenode之前需要在master1, slave1, slave2上分别启动journalnode。特别注意,如果不启动,namenode格式化会抛错。
在master1, slave1, slave2上分别启动journalnode。(单独启动进程用hadoop-daemon.sh start xxx)
./sbin/hadoop-daemon.sh start journalnode
在master1上格式化namenode
./bin/hdfs namenode -format ns
将./tmp 拷贝至master2
scp -r ./tmp/ master2:/xxx/soft/hadoop-2.7.3/
(3)启动namenode和yarn
./sbin/start-dfs.sh ./sbin/start-yarn.sh
5. 查看进程
[root@vm-10-112-29-9 hadoop-2.7.3]# jps
13349 NameNode
13704 DFSZKFailoverController
13018 JournalNode
14108 Jps
13836 ResourceManager [root@vm-10-112-29-10 hadoop-2.7.3]# jps
31412 NodeManager
30566 JournalNode
31174 DataNode
31576 Jps
31307 DFSZKFailoverController
31069 NameNode [root@vm-10-112-28-237 hadoop-2.7.3]# jps
27482 Jps
27338 NodeManager
27180 DataNode
26686 JournalNode
6. 验证HDFS
hadoop fs -put ./NOTICE.txt hdfs://ns/
7. 访问
hadoop namenode HA集群搭建的更多相关文章
- hadoop yarn HA集群搭建
可先完成hadoop namenode HA的搭建:http://www.cnblogs.com/kisf/p/7458519.html 搭建yarnde HA只需要在namenode HA配置基础上 ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- hadoop2.8 ha 集群搭建
简介: 最近在看hadoop的一些知识,下面搭建一个ha (高可用)的hadoop完整分布式集群: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop ...
- Hadoop的HA集群启动和停止流程
假设我们有3台虚拟机,主机名分别是hadoop01.hadoop02和hadoop03. 这3台虚拟机的Hadoop的HA集群部署计划如下: 3台虚拟机的Hadoop的HA集群部署计划 hadoop0 ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
- hadoop HA+kerberos HA集群搭建
IP.主机名规划 hadoop集群规划: hostname IP hadoop 备注 hadoop1 110.185.225.158 NameNode,ResourceManager,DFSZKFai ...
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
随机推荐
- js如何判断Object是否为空?(属性是否为空)
js 判断一个 object 对象是否为空 转载原文 判断一个对象是否为空对象,本文给出三种判断方法: 1.最常见的思路,for...in... 遍历属性,为真则为“非空数组”:否则为“空数组” fo ...
- js Tab切换实例
js 实现 tab 切换 实现如下效果: 1.图片每1秒钟切换1次. 2.当鼠标停留在整个页面上时,图片不进行轮播. 3.当点击切换页的选项上时,出现该选项的对应图片,而且切换页选项的背景颜色发生相应 ...
- find-if-an-item-is-in-a-javascript-array
http://stackoverflow.com/questions/143847/best-way-to-find-if-an-item-is-in-a-javascript-array Best ...
- rrdtool ubuntu python snmpwalk
rrdtool install: apt-get install libpango1.0-dev libxml2-dev wget https://packages.debian.org/wheezy ...
- Redis的基本使用(基于maven和spring)
使用redis基本测试 maven导包 <dependency> <groupId>redis.clients</groupId> <artifactId&g ...
- python 时间与时间戳之间的转换
https://blog.csdn.net/kl28978113/article/details/79271518 对于时间数据,如2016-05-05 20:28:54,有时需要与时间戳进行相互的运 ...
- linux下的时间管理概述
2017/6/21 时间这一概念在生活中至关重要,而在操作系统中也同样重要,其在系统中的功能绝不仅仅是给用户提供时间这么简单,内核的许多机制都依赖于时间子系统.但凡是要在某个精确的时间执行某个事件,必 ...
- 给Django后台富文本编辑器添加上传文件的功能
使用富文本编辑器上传的文件是要放到服务器上的,所以这是一个request.既然是一个request,就需要urls.py进行转发请求views.py进行处理.views.py处理完了返回一个文件所在的 ...
- Linux命令(基础2)
1.命令概要介绍: 查看目录内容:ls 切换目录命令:cd 创建与删除目录:touch(创建文件).rm(移除文件与目录).mkdir(创建目录) 拷贝与移动命令:cp(拷贝).mv(移动) 查看文件 ...
- 从CPU/OS到虚拟机和云计算
从CPU/OS到虚拟机和云计算 作者:张冬 关于软硬件谁为主导这个话题,套用一句谚语就是三十年河东三十年河西.风水轮流转.软件和硬件一定是相互促进.相互拆台又相互搭台的. ...