MapReduce实例(数据去重)
数据去重:
原理(理解):Mapreduce程序首先应该确认<k3,v3>,根据<k3,v3>确定<k2,v2>,原始数据中出现次数超过一次的数据在输出文件中只出现一次。Reduce的输出是不重复的数据,也就是每一行数据作为key,即k3。而v3为空或不需要设值。根据<k3,v3>得到k2为每一行的数据,v2为空。根据MapReduce框架设值可知,k1为每行的起始位置,v1为每行的内容。因此,v1需要赋值给k2,使得原来的v1作为新的k2,从而两个或更多文件通过在Reduce端聚合,得到去重后的数据。
数据:
file1.txt
2016-6-1 b
2016-6-2 a
2016-6-3 b
2016-6-4 d
2016-6-5 a
2016-6-6 c
2016-6-7 d
2016-6-3 c
file2.txt
2016-6-1 a
2016-6-2 b
2016-6-3 c
2016-6-4 d
2016-6-5 a
2016-6-6 b
2016-6-7 c
2016-6-3 c
*创建文件夹dedup_in并创建上述两文件,将该文件夹上传到HDFS中
[root@neusoft-master filecontent]# hadoop dfs -put dedup_in/ /neusoft/

[root@neusoft-master filecontent]# hadoop dfs -ls /neusoft

(1)自定义Mapper任务
private static class MyMapper extends Mapper<Object, Text, Text, Text>{
private static Text line=new Text();
@Override
protected void map(Object k1, Text v1,
Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
line=v1;//v1为每行数据,赋值给line
context.write(line, new Text(""));
}
}
(2)自定义Reduce任务
private static class MyReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text k2, Iterable<Text> v2s,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
context.write(k2, new Text(""));
}
}
(3)主函数(组织map和reduce)
public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=DataDeduplication.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName);
//*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(DataDeduplication.class);
//3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path(args[0]));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//7分区(默认1个),排序,分组,规约 采用 默认
job.setCombinerClass(MyReducer.class);
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
}
数据去重源代码:
package Mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class DataDeduplication {
public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=DataDeduplication.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName); //*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(DataDeduplication.class); //3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path(args[0]));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//7分区(默认1个),排序,分组,规约 采用 默认
job.setCombinerClass(MyReducer.class);
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); //12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
}
private static class MyMapper extends Mapper<Object, Text, Text, Text>{
private static Text line=new Text();
@Override
protected void map(Object k1, Text v1,
Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
line=v1;//v1为每行数据,赋值给line
context.write(line, new Text(""));
}
}
private static class MyReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text k2, Iterable<Text> v2s,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
context.write(k2, new Text(""));
}
}
}
数据去重
运行结果:
[root@neusoft-master filecontent]# hadoop jar DataDeduplication.jar /neusoft/dedup_in /out12
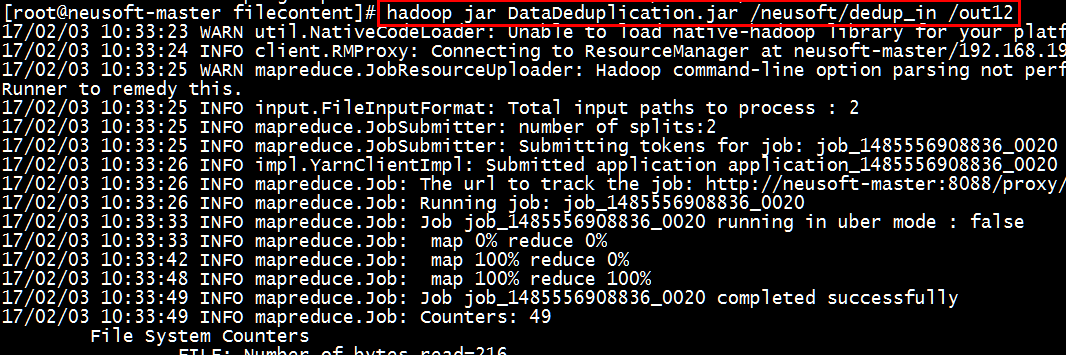
[root@neusoft-master filecontent]# hadoop dfs -text /out12/part-r-00000
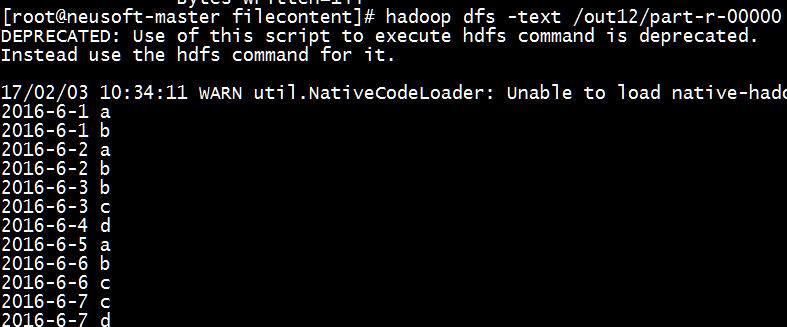
结果验证正确~
注意:HDFS的显示形式
[root@neusoft-master filecontent]# hadoop dfs -ls hdfs://neusoft-master:9000/out12
[root@neusoft-master filecontent]# hadoop dfs -ls /out12

等价表示形式

/out12的完整表达形式hdfs://neusoft-master:9000/out12
MapReduce实例(数据去重)的更多相关文章
- 利用MapReduce实现数据去重
数据去重主要是为了利用并行化的思想对数据进行有意义的筛选. 统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 示例文件内容: 此处应有示例文件 设计思路 数据 ...
- hadoop mapreduce实现数据去重
实现原理分析: map函数数将输入的文本按照行读取, 并将Key--每一行的内容 输出 value--空. reduce 会自动统计所有的key,我们让reduce输出key-> ...
- MapReduce实现数据去重
一.原理分析 Mapreduce的处理过程,由于Mapreduce会在Map~reduce中,将重复的Key合并在一起,所以Mapreduce很容易就去除重复的行.Map无须做任何处理,设置Map中写 ...
- [Hadoop]-从数据去重认识MapReduce
这学期刚好开了一门大数据的课,就是完完全全简简单单的介绍的那种,然后就接触到这里面最被人熟知的Hadoop了.看了官网的教程[吐槽一下,果然英语还是很重要!],嗯啊,一知半解地搭建了本地和伪分布式的, ...
- hadoop —— MapReduce例子 (数据去重)
参考:http://eric-gcm.iteye.com/blog/1807468 例子1: 概要:数据去重 描述:将file1.txt.file2.txt中的数据合并到一个文件中的同时去掉重复的内容 ...
- Mapreduce实例--去重
数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选.统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 数据去重的最终目标是让原始数据中 ...
- MapReduce实例
1.WordCount(统计单词) 经典的运用MapReuce编程模型的实例 1.1 Description 给定一系列的单词/数据,输出每个单词/数据的数量 1.2 Sample a is b is ...
- Hadoop 数据去重
数据去重这个实例主要是为了读者掌握并利用并行化思想对数据进行有意义的筛选.统计大数据集上的数据种类个数.从网站日志中计算访问等这些看似庞杂的任务都会涉及数据去重.下面就进入这个实例的MapReduce ...
- map/reduce实现数据去重
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.co ...
随机推荐
- 使用d3.v3插件绘制出svg图
众所周知,这个插件使用的svg技术,而IE8(包括IE8)之前的浏览器是不支持svg的 接下来看代码吧 从后台获取到带id和父id的目录数据[json格式] var module = requestU ...
- cordova开发ios炸鸡
cordova/lib/copy-www-build-step.sh: Permission denied 解决办法: cd platforms/ios/cordova/lib sudo chmod ...
- APP图标制作以及替换步骤
1 首先要有一张1024X1024像素以上的的大图片(长宽最好相等) 2 如果app图标需要的是圆角的,那先通过以下这个工具转换一下: http://www.360doc.com/content/ ...
- JS有趣的单线程
一.JS的执行特点 源于单线程的特性, JS在一段时间内只能执行一部分代码, 那么, 当有多块代码需要执行时, 就需要排队等候了. 二.单线程与异步事件 (1) 什么是异步事件? 异 ...
- [Windows] Windows 8.x 取消触摸板切换界面
在鼠标中选中UltraNav,找到Application Gestures - Edge Swipes,取消Enable Edge Swipes.
- gradle 两种更新方法
第一种.Android studio更新 第一步:在你所在项目文件夹下:你项目根目录gradlewrappergradle-wrapper.properties 替换 distributionUrl= ...
- ISD9160学习笔记03_ISD9160音频解码代码分析
录音例程涉及了录音和播放两大块内容,这篇笔记就先来说说播放,暂且先击破解码这部分功能. 我的锤子便签中有上个月记下的一句话,“斯蒂芬·平克说,写作之难,在于把网状思考,用树状结构,体现在线性展开的语句 ...
- iOS 在已有项目添加CoreData
本文转载至 http://cnbin.github.io/blog/2016/03/11/ios-zai-yi-you-xiang-mu-tian-jia-coredata/ 如果是新项目很好说,新建 ...
- 如何创建圆角 UITextField 与内阴影
本文转自http://www.itstrike.cn/Question/9309fbd6-ef5d-4392-b361-a60fd0a3b18e.html 主要学习如何创建内阴影 我自定义 UITex ...
- 关于bat中使用rar压缩命令
数据库备份,导出的dmp 文件比较大,需要压缩,压缩后大小能变为原来十分之一左右吧. 写的是批处理的语句,每天调用,自动导出dmp 文件,压缩删除原文件. 首先写下路径 先将压缩软件的路径写入系统的环 ...