Python - Cookie绕过验证码登录
前言
有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。
获取不到也没关系,可以通过添加cookie的方式绕过验证码。
另一篇博文 Python Selenium Cookie 绕过验证码实现登录 介绍了另外一种处理方式,及实际项目应用实战,有兴趣的同学可以点击查看。
一、抓登录cookie
1.登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开博客园登录界面,手动输入账号和密码(勾选下次自动登录)
4.打开fiddler抓包工具,刷新下登录首页,就是登录前的cookie了
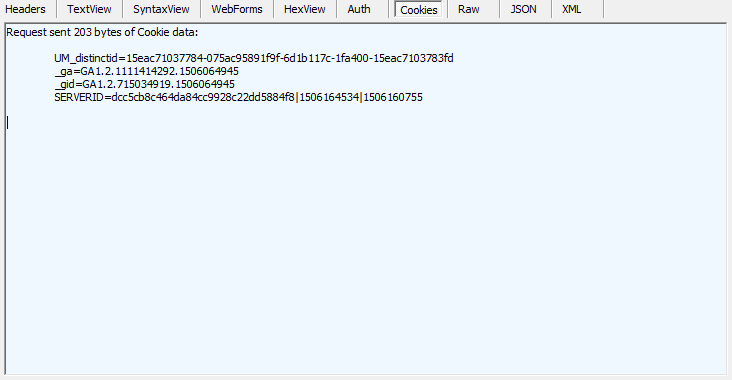
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用

代码实例:
# baseinfo -> __init__
#-*-coding:utf-8-*-
# Time:2017/9/23 17:44
# Author:YangYangJun loginUrl = "https://passport.cnblogs.com/user/signin" loginHeaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36"
} CNBlogsCookie = '通过抓包工具获取该Cookie' CnblogsAspNetCoreCookies = '通过抓包工具获取该Cookie' editUrl = 'https://i.cnblogs.com/EditPosts.aspx?opt=1'
#-*-coding:utf-8-*-
# Time:2017/9/23 10:15
# Author:YangYangJun import requests
#导入配置文件
import baseinfo #登录访问地址
loginUrl = baseinfo.loginUrl
#请求头
loginHeaders = baseinfo.loginHeaders #登录后Cookie1
CNBlogsCookie = baseinfo.CNBlogsCookie
#登录后Cookie2
CnblogsAspNetCoreCookies = baseinfo.CnblogsAspNetCoreCookies
#新建随笔方位地址
editUrl = baseinfo.editUrl
#获取session
s = requests.session() #
#r = s.get(loginUrl,headers = loginHeaders,verify = False ) #获取cookie
c = requests.cookies.RequestsCookieJar() # 添加登录需要的两个cookie
c.set(".CNBlogsCookie",CNBlogsCookie)
c.set('.Cnblogs.AspNetCore.Cookies',CnblogsAspNetCoreCookies)
#更新cookie
s.cookies.update(c) body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是绕过登录的标题: -*- Bluesky -*-",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/Skyyj/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(editUrl, data=body, verify=False)
#获取请求返回的响应信息
print r2.content
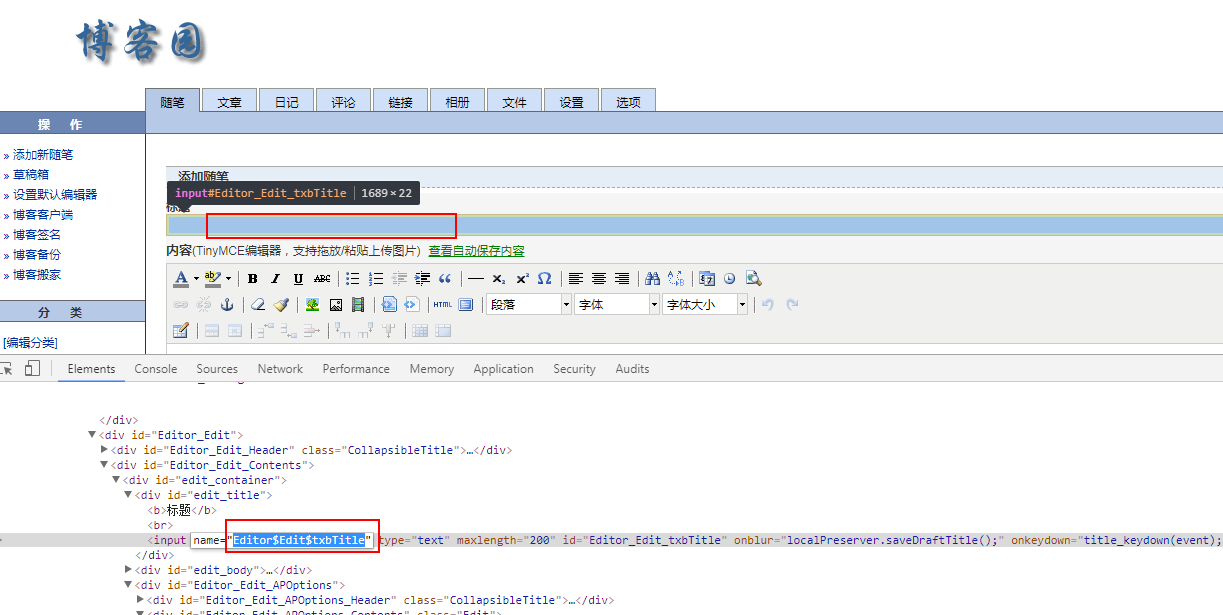
body中的值是可以通过开发者模式查看,如下图:
填写标题
response的返回内容还有其它更多信息
-- r.status_code #响应状态码
-- r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
-- r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
-- r.json() #Requests中内置的JSON解码器
-- r.url # 获取url
-- r.encoding # 编码格式
-- r.cookies # 获取cookie
-- r.raw #返回原始响应体
-- r.text #字符串方式的响应体,会自动根据响应头部的字符编码进行解码
-- r.raise_for_status() #失败请求(非200响应)抛出异常
Python - Cookie绕过验证码登录的更多相关文章
- cookie绕过验证码登录
#coding:utf-8 ''' cookie绕过验证码登录,第一步先访问登录页面获取登录前的cookie,第二步用fiddler抓到的手动登录的cookie加入cookie中,登录成功,第三步登录 ...
- python接口自动化(十三)--cookie绕过验证码登录(详解)
简介 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接).获取不到也没关系,可以通过添加cookie的方式绕过验证码.(注意:并不是所有的 ...
- 通过cookie绕过验证码登录
在我们做自动化的时候碰到一些比较难破解的验证码时是非常头疼的,一般来说最好的办法就是让开发屏蔽,这样最有益身心健康. 那么今天我介绍的这个方法也挺简单的,就是通过添加cookie的方式绕过验证码直接登 ...
- Requests方法 -- cookie绕过验证码登录操作
前言有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接).获取不到也没关系,可以通过添加 cookie 的方式绕过验证码. 1.这里以登录博 ...
- Python Selenium Cookie 绕过验证码实现登录
Python Selenium Cookie 绕过验证码实现登录 之前介绍过博客园的通过cookie 绕过验证码实现登录的方法.这里并不多余,会增加分析和另外一种方法实现登录. 1.思路介绍 1.1. ...
- python接口自动化(Cookie_绕过验证码登录)
python接口自动化(Cookie_绕过验证码登录) 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以 ...
- Python+fiddler(基于Cookie绕过验证码自动登录)
案例:使用Cookie绕过百度验证码自动登录账户 步骤: 1.浏览器进入百度首页,点击登录按钮,输入相关信息(注意:暂时不要点击登录按钮) 2.进入fiddler,首先获取证书,Tools--> ...
- python接口自动化-Cookie_绕过验证码登录
前言 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以通过添加Cookie的方式绕过验证码 前面在“pyt ...
- python接口自动化:绕过验证码登录
上线产品的登录接口会有验证码,一般可以通过添加cookie的方式绕过验证码. 一.抓登录的cookie 1. 先手动登录一次,然后用fiddler抓取这个cookie,再直接把这个值添加到cookie ...
随机推荐
- Twitter OA prepare: Rational Sum
In mathematics, a rational number is any number that can be expressed in the form of a fraction p/q ...
- 关于DOM2级事件的事件捕获和事件冒泡
DOM2级事件中addEventListener的执行机制,多个addEventListener同时添加时的执行先后规律: W3C的DOM事件触发分为三个阶段:①.事件捕获阶段,即由最顶层元素(一般是 ...
- 在liferay中如何使用Ajax的请求
1:首先在界面上写一个路径,这个路径就是要找后台中的哪一个操作比如:
- zw版【转发·台湾nvp系列Delphi例程】HALCON Regiongrowing
zw版[转发·台湾nvp系列Delphi例程]HALCON Regiongrowing procedure TForm1.Button1Click(Sender: TObject);var img : ...
- Root :: AOAPC I: Beginning Algorithm Contests (Rujia Liu) Volume 7. Graph Algorithms and Implementation Techniques
uva 10803 计算从任何一个点到图中的另一个点经历的途中必须每隔10千米 都必须有一个点然后就这样 floy 及解决了 ************************************* ...
- Swift Optional
拆包和解包的原因: 其实所谓的 nil 就是 Optional.None, 非 nil 就是Optional.Some, 然后会通过Some(T)包装(wrap)原始值,这也是为什么在使用 Optio ...
- REST服务安全-双向认证
1. 创建服务器密钥,其密钥库为 d:/mykeys/server.ks,注意keypass和storepass保持一致,它们分别代表 密钥密码和密钥库密码,注意 CN=localhost 中,loc ...
- JSP禁用缓存常用方法
内容主要转自:http://www.cnblogs.com/linjiqin/archive/2011/07/20/2111627.html jsp页面禁止缓存设置 1.客户端缓存要在<head ...
- python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码
python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码 python的json.dumps方法默认会输出成这种格式"\u535a\u ...
- Python3.x(windows系统)安装requests库
Python3.x(windows系统)安装requests库 cmd命令: pip install requests 执行结果: