[转载] 跳表SkipList
原文: http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html
leveldb中memtable的思想本质上是一个skiplist.
<1>. 聊一聊作者的其人其事
跳表是由William Pugh发明。他在 Communications of the ACM June 1990, 33(6) 668-676 发表了Skip lists: a probabilistic alternative to balanced trees,在该论文中详细解释了跳表的数据结构和插入删除操作。
William Pugh同时还是FindBug(没有使用过,这是一款java的静态代码分析工具,直接对java 的字节码进行分析,能够找出java字节码中潜在很多错误。)作者之一。现在是University of Maryland, College Park(马里兰大学伯克分校,位于马里兰州,全美大学排名在五六十名左右的样子)大学的一名教授。他和他的学生所作的研究深入的影响了java语言中内存池实现。
又是一个计算机的天才!
<2>. 言归正传,跳表简介
这是跳表的作者,上面介绍的William Pugh给出的解释:
Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
下面来研究一下跳表的核心思想:
先从链表开始,如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。

如果是说链表是排序的,并且节点中还存储了指向前面第二个节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。

这基本上就是跳表的核心思想,其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
<3>.跳表的数据存储模型
我们定义:
如果一个基点存在k个向前的指针的话,那么陈该节点是k层的节点。
一个跳表的层MaxLevel义为跳表中所有节点中最大的层数。
下面给出一个完整的跳表的图示:

那么我们该如何将该数据结构使用二进制存储呢?通过上面的跳表的很容易设计这样的数据结构:
定义每个节点类型:
typedef struct nodeStructure

上面的每个结构体对应着图中的每个节点,如果一个节点是一层的节点的话(如7,12等节点),那么对应的forward将指向一个只含一个元素的数组,以此类推。
定义跳表数据类型:
} * list;
跳表数据类型中包含了维护跳表的必要信息,level表明跳表的层数,header如下所示:
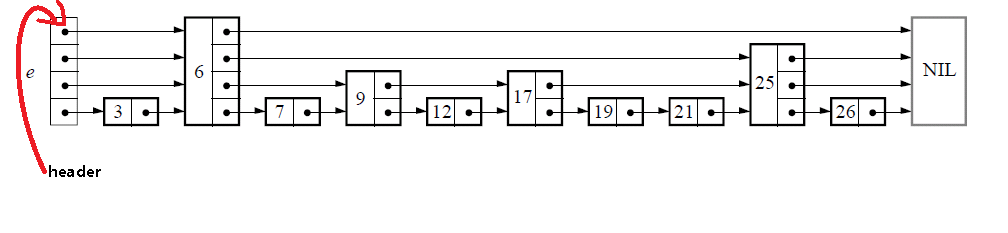
定义辅助变量:
定义上图中的NIL变量:node NIL;
#define MaxLevel (MaxNumberOfLevels-1)
定义辅助方法:
好的基本的数据结构定义已经完成,接下来来分析对于跳表的一个操作。
<4>. 跳表的代码实现分析
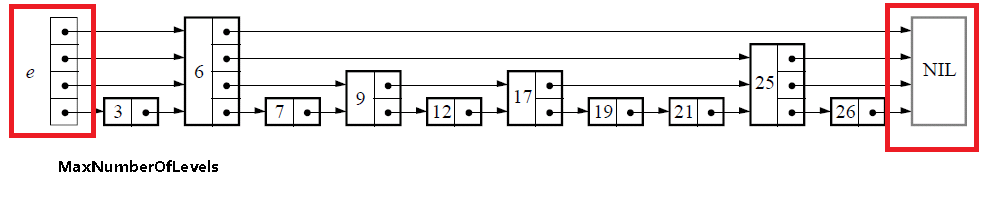
4.1 初始化
初始化的过程很简单,仅仅是生成下图中红线区域内的部分,也就是跳表的基础结构:
};
4.2 插入操作
由于跳表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳表的level变量。
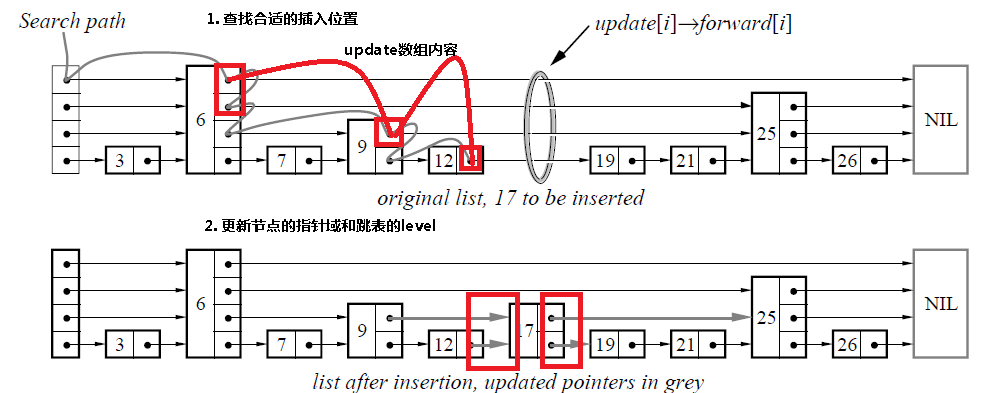
}
4.3 删除某个节点
和插入是相同的,首先查找需要删除的节点,如果找到了该节点的话,那么只需要更新指针域,如果跳表的level需要更新的话,进行更新。
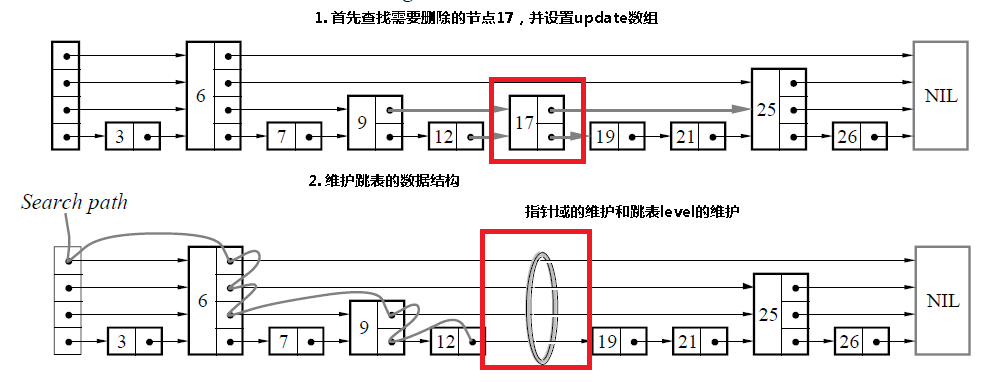
}
4.4 查找
查找操作其实已经在插入和删除过程中包含,比较简单,可以参考源代码。
<5>. 论文,代码下载及参考资料
//--------------------------------------------------------------------------------
增加跳表c#实现代码 2011-5-29下午
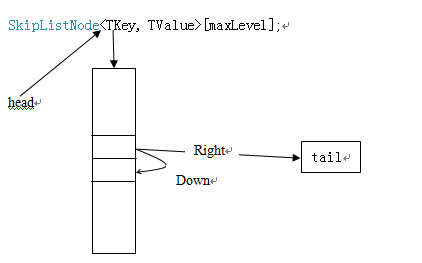
上面给出的数据结构的模型是直接按照跳表的模型得到的,另外还有一种数据结构的模型:
跳表节点类型,每个跳表类型中仅仅存储了左侧的节点和下面的节点:
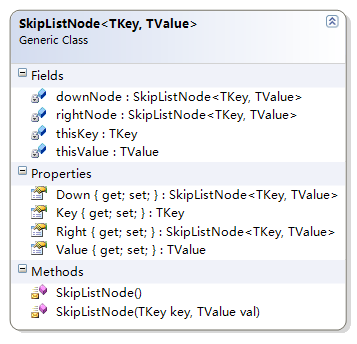
我们现在来看对于这种模型的操作代码:
1. 初始化完成了如下的操作:
2. 插入操作:和上面介绍的插入操作是类似的,首先查找到插入的位置,生成update数组,然后随机生成一个level,然后修改指针。
3. 删除操作:和上面介绍的删除操作是类似的,查找到需要删除的节点,如果查找不到,抛出异常,如果查找到的需要删除的节点的话,修改指针,释放删除节点的内存。
代码下载:
/Files/xuqiang/skiplist_csharp.rar
[转载] 跳表SkipList的更多相关文章
- 跳表SkipList
原文:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html 跳表SkipList 1.聊一聊跳表作者的其人其事 2. 言归正 ...
- 3.3.7 跳表 SkipList
一.前言 concurrentHashMap与ConcurrentSkipListMap性能测试 在4线程1.6万数据的条件下,ConcurrentHashMap 存取速度是ConcurrentSki ...
- 跳表 SkipList
跳表是平衡树的一种替代的数据结构,和红黑树不同,跳表对树的平衡的实现是基于一种随机化的算法,这样就使得跳表的插入和删除的工作比较简单. 跳表是一种复杂的链表,在简单链表的节点信息之上又增加了额 ...
- 存储系统的基本数据结构之一: 跳表 (SkipList)
在接下来的系列文章中,我们将介绍一系列应用于存储以及IO子系统的数据结构.这些数据结构相互关联又有着巨大的区别,希望我们能够不辱使命的将他们分门别类的介绍清楚.本文为第一节,介绍一个简单而又有用的数据 ...
- 跳表(SkipList)设计与实现(Java)
微信搜一搜「bigsai」关注这个有趣的程序员 文章已收录在 我的Github bigsai-algorithm 欢迎star 前言 跳表是面试常问的一种数据结构,它在很多中间件和语言中得到应用,我们 ...
- 跳表(skiplist)Python实现
# coding=utf-8 # 跳表的Python实现 import random # 最高层数设置为4 MAX_LEVEL = 4 def randomLevel(): ""& ...
- C语言跳表(skiplist)实现
一.简介 跳表(skiplist)是一个非常优秀的数据结构,实现简单,插入.删除.查找的复杂度均为O(logN).LevelDB的核心数据结构是用跳表实现的,redis的sorted set数据结构也 ...
- 跳表(SkipList)原理篇
1.什么是跳表? 维基百科:跳表是一种数据结构.它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度.快速的查询效果是通过维护一个多层次的链表实 ...
- redis笔记_源码_跳表skiplist
参照:https://juejin.im/post/57fa935b0e3dd90057c50fbc#comment http://redisbook.com/preview/skiplist/dat ...
随机推荐
- Mac系统之----教你怎么显示隐藏文件,或者关闭显示隐藏文件
缺省情况下,在 Mac 下是不显示隐藏文件的,Finder 也未提供设置是否显示隐藏文件的选项,不像 Windows 下,有一个“文件夹选项“设置界面里可以控制,但这并不表示 Mac 下无法显示隐藏文 ...
- Oracle 11gR2新建空表不分配Segment
一.引言: 在看<收获,不止Oracle>的神奇,走进逻辑体系世界一章时,需要新建一张表查看Extents的情况,由于该书的环境是ORACLE10G的,因此新建空表以后立刻就分配Segme ...
- cookie学习
cookie是储存于访问者的计算机中的变量,每当同一台计算机通过浏览器请求某个页面时,就会发送这个cookie,可以使用javascript来创建和取回cookie的值. 创建和存储cookie 首先 ...
- JavaScript DOM 编程艺术(第2版)读书笔记 (7)
动态创建标记 一些传统方法 document.write document.write()方法可以方便快捷的把字符串插入到文档里. 请把以下标记代码保存为一个文件,文件名就用test.html 好了. ...
- Integer Inquiry -TJU1112
作为最简单的高精度加法,要注意的是如下几点, 第一,因为是数位达到上百位的大数,所以只能用字符串数组来存贮. 第二,为了方便之后的相加操作,应该把字符串数组逆序转化为一个整型数组. 第三,在控制进位的 ...
- C++智能指针管理类
1.程序员明确的进行内存释放 对于c++程序员,最头脑的莫过于对动态分配的内存进行管理了.c++在堆上分配的内存,需要程序员负责对分配的内存进行释放.但有时内存的释放看起来并不件很轻松的事,如下程序 ...
- Session机制(是对cookie的作用的提升,使用较多)
1.Session作用类似于购物车,第一次,放入物品,可以获得Session的id,并可以设置id失效的时间,这样便于多次将物品放在购物车里面,使用的就是获取的Session的id: 2.Sessio ...
- Maximum Value(哈希)
B. Maximum Value time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- 列出本机JCE提供者,支持消息摘要算法,支持公钥私钥算法
import java.security.Provider; import java.security.Security; public class TestBouncyCastle { public ...
- ord函数-php
摘录自http://php.net/manual/zh/function.ord.php (PHP 4, PHP 5, PHP 7) ord — 返回字符的 ASCII 码值 说明 int ord ( ...