优酷上传SDK解析(Python)
1.优酷上传

1)调用优酷的sdk完成优酷视频的上传首先需要将实例化YoukuUpload类实例化,传入的参数为(client_id,access_token,文件地址)
实例化时执行__init__()
2)实例化完成后得到类的对象,通过对象调用upload方法,传入参数为字典(dict),字典内的必传参数为title,其余可为默认,其中的一些参数是为了控制视频一些信息的,具体参见代码的注释
3)在upload方法中
(1)会先判断upload_token 这个参数是否存在,该参数为优酷返回,存在就继续之前的上传,如果不存在的话就判断为新上传。
(2)在新上传中限制性create方法来在服务端创建上传,在此之前会对传进来的参数和默认的参数会放入新的字典中
def prepare_video_params(self, title=None, tags='Others', description='',
copyright_type='original', public_type='all',
category=None, watch_password=None,
latitude=None, longitude=None, shoot_time=None
):
# 准备视频所以需要的一些参数
params = {}
if title is None:
# 如果没有传title的话,title默认等于文件名
title = self.file_name
elif len(title) > 50:
# 如果title过长,长度大于50的话,就截取前50个字符作为title
title = title[:50]
params['title'] = title
params['tags'] = tags
# tags就等于你传进来的那个tags,默认为others
params['description'] = description
# 描述默认为空,可以传进来
params['copyright_type'] = copyright_type
# 版权所有 original: 原创 reproduced: 转载
params['public_type'] = public_type
# 公开类型 all: 公开 friend: 仅好友观看 password: 输入密码观看 private: 私有
if category:
params['category'] = category
# 视频分类 默认为空,可传
if watch_password:
params['watch_password'] = watch_password
# 观看密码,默认为空,可传
"""
latitude/longitude用户记录地理位置信息
shoot_time用来标记视频中正片的开始时间
"""
if latitude:
params['latitude'] = latitude
# 纬度
if longitude:
params['longitude'] = longitude
# 经度
if shoot_time:
params['shoot_time'] = shoot_time
log.debug("prepare_video_params:%s" % params)
return params
(3)在create方法中,会用get方法访问url = 'https://api.youku.com/uploads/create.json',并将参数传过去,创建oss客户端,优酷会返回一些字段
def create(self, params):
# prepare file info
params['file_name'] = self.file_name
params['file_size'] = self.file_size # 在__init__中获取到了,也就是在类的实例化时就已经根据文件的地址获取了文件的大小
params['file_md5'] = self.file_md5 = self.checksum_md5file(self.file)
# 将文件信息做md5 校验,根据文件名打开文件,然后每次读取8192B,进行md5更新后再转为十六进制返回
self.logger.info('upload file %s, size: %d bytes' %
(self.file_name, self.file_size))
self.logger.info('md5 of %s: %s' %
(self.file_name, self.file_md5)) params['client_id'] = self.client_id # client_id
params['access_token'] = self.access_token # access_token url = 'https://api.youku.com/uploads/create.json'
r = requests.get(url, params=params)# 以get方法将文件信息发送到'https://api.youku.com/uploads/create.json'
check_error(r, 201)
result = r.json()
log.debug("file--->vid:%s,return_result:%s" % (self.v_vid, result))
self.upload_token = result['upload_token']
self.logger.info('upload token of %s: %s' %
(self.file_name, self.upload_token))
self.upload_server_ip = socket.gethostbyname(
result['upload_server_uri'])
self.logger.info('upload_server_ip of %s: %s' %
(self.file_name, self.upload_server_ip))
log.debug("file_vid:%s ip:%s" % (self.v_vid, self.upload_server_ip))
(4) 调用create_file方法,将文件的大小、token、每次上传切片大小传到上一步返回的ip所指向的服务器
(5) 调用new_slice方法 告诉服务器才准备上传文件切片,目的在于检查服务器状态和返回服务器中这个新建切片的信息,没有报错就执行_save_slice_state方法
(6)在_save_slice_state方法中,将切片的信息进行更新或者保存,之后判断返回的task_id是否为0,如果为零就直接提交commit完成整个上传,不为0就 调用upload_slice方法上传文件切片
(7)在upload_slice方法中,每次打开文件移动指针位置到上一次上传的地方,然后读取2048kb的数据,之后调用url进行上传。
def upload_slice(self):
# 上传文件切片 seek():移动文件读取指针到指定位置 data = None
with open(self.file, 'rb') as f:
f.seek(self.slice_offset)
data = f.read(self.slice_length) #
params = {
'upload_token': self.upload_token,
'slice_task_id': self.slice_task_id,
'offset': self.slice_offset,
'length': self.slice_length, # Byte
'hash': self.checksum_md5data(data)# hash这个字段是为了在服务端进行校验,来验证上传的文件有没有出现丢失或错误
}
url = 'http://%s/gupload/upload_slice' % self.upload_server_ip
r = requests.post(url, params=params, data=data)
check_error(r, 201)
self._save_slice_state(r.json())
(8) 循环判断task_id,若task_id为0则结束上传(即调用commit())
整体流程:应该是先本地将文件的信息上传到服务器,在服务器创建同名文件,然后根据文件的size和每次对文件进行切片的大小控制上传,在上传过程中服务端会先返回这次要上传的切片的task_id,如果在服务端的文件大小等于你上传的参数中提交的size,就会返回task_id为0,否则就不为0。本地会根据这个参数来判断是否结束上传。
2. 完整优酷上传sdk代码
"""Youku cloud Python Client doc: http://cloud.youku.com/docs/doc?id=110
""" import os
import requests
import json
import time
import hashlib
import socket
import logging
from time import sleep
from util import check_error, YoukuError if not os.path.exists('/var/log/youku/'):
os.makedirs('/var/log/youku')
log = logging.getLogger()
log.setLevel(logging.DEBUG)
fmt = logging.Formatter("%(asctime)s %(pathname)s %(filename)s %(funcName)s %(lineno)s %(levelname)s - %(message)s",
"%Y-%m-%d %H:%M:%S")
stream_handler = logging.FileHandler(
'/var/log/youku/debug-%s.log' % (time.strftime('%Y-%m-%d', time.localtime(time.time()))))
stream_handler.setLevel(logging.DEBUG)
stream_handler.setFormatter(fmt)
log.addHandler(stream_handler) class YoukuUpload(object):
"""Youku Upload Client. Upload file to Youku Video. Support resume upload if interrupted.
Should use one instance of YoukuUpload for one upload file in one thread,
since it has internal state of upload process. doc: http://cloud.youku.com/docs/doc?id=110
""" def __init__(self, client_id, access_token, file, v_vid = None, logger=None):
"""
Args:
file: string, include path and filename for open(). filename
must contain video file extension.
"""
super(YoukuUpload, self).__init__()
self.client_id = client_id
self.access_token = access_token
self.v_vid = v_vid # 上传的视频id号
self.logger = logger or logging.getLogger(__name__) # file info
self.file = file
self.file_size = os.path.getsize(self.file) # int 获取文件的大小
self.file_dir, self.file_name = os.path.split(self.file) # string 分割路径来获取文件名
if self.file_dir == '':
self.file_dir = '.'
self.file_ext = self.file_name.rsplit('.', 1)[1], # file extension
self.file_md5 = None # string, do later # upload state
self.upload_token = None # string
self.upload_server_ip = None # string
self.slice_task_id = None # int
self.slice_offset = None # int
self.slice_length = None # int
self.transferred = None # int for bytes has uploaded
self.finished = False # boolean # resume upload state
self._read_upload_state_from_file() def prepare_video_params(self, title=None, tags='Others', description='',
copyright_type='original', public_type='all',
category=None, watch_password=None,
latitude=None, longitude=None, shoot_time=None
):
# 准备视频所以需要的一些参数
""" util method for create video params to upload. Only need to provide a minimum of two essential parameters:
title and tags, other video params are optional. All params spec
see: http://cloud.youku.com/docs?id=110#create . Args:
title: string, 2-50 characters.
tags: string, 1-10 tags joind with comma.
description: string, less than 2000 characters.
copyright_type: string, 'original' or 'reproduced'
public_type: string, 'all' or 'friend' or 'password'
watch_password: string, if public_type is password.
latitude: double.
longitude: double.
shoot_time: datetime. Returns:
dict params that upload/create method need.
"""
params = {}
if title is None:
# 如果没有传title的话,title默认等于文件名
title = self.file_name
elif len(title) > 50:
# 如果title过长,长度大于50的话,就截取前50个字符作为title
title = title[:50]
params['title'] = title
params['tags'] = tags
# tags就等于你传进来的那个tags,默认为others
params['description'] = description
# 描述默认为空,可以传进来
params['copyright_type'] = copyright_type
# 版权所有 original: 原创 reproduced: 转载
params['public_type'] = public_type
# 公开类型 all: 公开 friend: 仅好友观看 password: 输入密码观看 private: 私有
if category:
params['category'] = category
# 视频分类 默认为空,可传
if watch_password:
params['watch_password'] = watch_password
# 观看密码,默认为空,可传
"""
latitude/longitude用户记录地理位置信息
shoot_time用来标记视频中正片的开始时间
"""
if latitude:
params['latitude'] = latitude
# 纬度
if longitude:
params['longitude'] = longitude
# 经度
if shoot_time:
params['shoot_time'] = shoot_time
log.debug("prepare_video_params:%s" % params)
return params def create(self, params):
# prepare file info
params['file_name'] = self.file_name
params['file_size'] = self.file_size # 在__init__中获取到了,也就是在类的实例化时就已经根据文件的地址获取了文件的大小
params['file_md5'] = self.file_md5 = self.checksum_md5file(self.file)
# 将文件信息做md5 校验,根据文件名打开文件,然后每次读取8192B,进行md5更新后再转为十六进制返回
self.logger.info('upload file %s, size: %d bytes' %
(self.file_name, self.file_size))
self.logger.info('md5 of %s: %s' %
(self.file_name, self.file_md5)) params['client_id'] = self.client_id # client_id
params['access_token'] = self.access_token # access_token url = 'https://api.youku.com/uploads/create.json'
r = requests.get(url, params=params)# 以get方法将文件信息发送到'https://api.youku.com/uploads/create.json'
check_error(r, 201)
result = r.json()
log.debug("file--->vid:%s,return_result:%s" % (self.v_vid, result))
self.upload_token = result['upload_token']
self.logger.info('upload token of %s: %s' %
(self.file_name, self.upload_token))
self.upload_server_ip = socket.gethostbyname(
result['upload_server_uri'])
self.logger.info('upload_server_ip of %s: %s' %
(self.file_name, self.upload_server_ip))
log.debug("file_vid:%s ip:%s" % (self.v_vid, self.upload_server_ip))
def _save_upload_state_to_file(self):
"""if create and create_file has execute, save upload state
to file for next resume upload if current upload process is
interrupted.
"""
# 保存文件的上传信息,先判断文件是否可写、可读、可执行
# 保存的信息包括文件的上传upload_token.上传到的服务器ip
# 保存的文件会在上传完毕之后删除
if os.access(self.file_dir, os.W_OK | os.R_OK | os.X_OK):
save_file = '/tmp' + 'youku.upload'
data = {
'upload_token': self.upload_token,
'upload_server_ip': self.upload_server_ip
}
with open(save_file, 'w') as f:
json.dump(data, f) def _read_upload_state_from_file(self):
save_file = '/tmp' + 'youku.upload'
try:
with open(save_file) as f:
data = json.load(f)
self.upload_token = data['upload_token']
self.upload_server_ip = data['upload_server_ip']
# check upload_token expired
try:
self.check()
except YoukuError, e:
if e.code == 120010223:
# Expired upload token
self.upload_token = None
self.upload_server_ip = None
self._delete_upload_state_file()
except:
pass def _delete_upload_state_file(self):
try:
os.remove('/tmp' + 'youku.upload')
except:
pass def checksum_md5file(self, filename):
md5 = hashlib.md5()
with open(filename, 'rb') as f:
for chunk in iter(lambda: f.read(8192), b''):
md5.update(chunk)
return md5.hexdigest() def checksum_md5data(self, data):
md5 = hashlib.md5()
md5.update(data)
return md5.hexdigest() def create_file(self):
params = {
'upload_token': self.upload_token,
'file_size': self.file_size, # Byte
'ext': self.file_ext,
'slice_length': 2048 # KB
}
# 上传文件每次传2048KB
url = 'http://%s/gupload/create_file' % self.upload_server_ip
r = requests.post(url, data=params)
check_error(r, 201) # save upload state to resume upload
self._save_upload_state_to_file() def new_slice(self):
params = {
'upload_token': self.upload_token
}
url = 'http://%s/gupload/new_slice' % self.upload_server_ip
r = requests.get(url, params=params)
check_error(r, 201)
self._save_slice_state(r.json()) def _save_slice_state(self, result):
# 更新切片状态
self.slice_task_id = result['slice_task_id']
self.slice_offset = result['offset']
self.slice_length = result['length']
self.transferred = result['transferred']
self.finished = result['finished'] def upload_slice(self):
# 上传文件切片 seek():移动文件读取指针到指定位置 data = None
with open(self.file, 'rb') as f:
f.seek(self.slice_offset)
data = f.read(self.slice_length) #
params = {
'upload_token': self.upload_token,
'slice_task_id': self.slice_task_id,
'offset': self.slice_offset,
'length': self.slice_length, # Byte
'hash': self.checksum_md5data(data)
}
url = 'http://%s/gupload/upload_slice' % self.upload_server_ip
r = requests.post(url, params=params, data=data)
check_error(r, 201)
self._save_slice_state(r.json()) def check(self):
params = {
'upload_token': self.upload_token
}
url = 'http://%s/gupload/check' % self.upload_server_ip
r = requests.get(url, params=params)
check_error(r, 200)
return r.json() def commit(self):
status = self.check()# 检查上传状态
if status['status'] == 4:
raise ValueError('upload has not complete, should not commit')
while status['status'] != 1: # status is 2 or 3
sleep(10)
status = self.check() params = {
'access_token': self.access_token,
'client_id': self.client_id,
'upload_token': self.upload_token,
'upload_server_ip': status['upload_server_ip']
}
url = 'https://api.youku.com/uploads/commit.json'
r = requests.post(url, data=params)
check_error(r, 200)
self.finished = True
self._delete_upload_state_file()# 删除记录视频上传信息的文件
log.debug("sdk---->vid:%s youku video_id:%s" % (self.v_vid, r.json()['video_id']))
return r.json()['video_id'] def cancel(self):
status = self.check()
params = {
'access_token': self.access_token,
'client_id': self.client_id,
'upload_token': self.upload_token,
'upload_server_ip': status['upload_server_ip']
}
url = 'https://api.youku.com/uploads/cancel.json'
r = requests.get(url, params=params)
check_error(r, 200)
self._delete_upload_state_file()
return r.json()['upload_token'] def spec(self):
url = 'https://api.youku.com/schemas/upload/spec.json'
r = requests.get(url)
check_error(r, 200)
return r.json() def transferred_percent(self):
"""return current transferred percent
"""
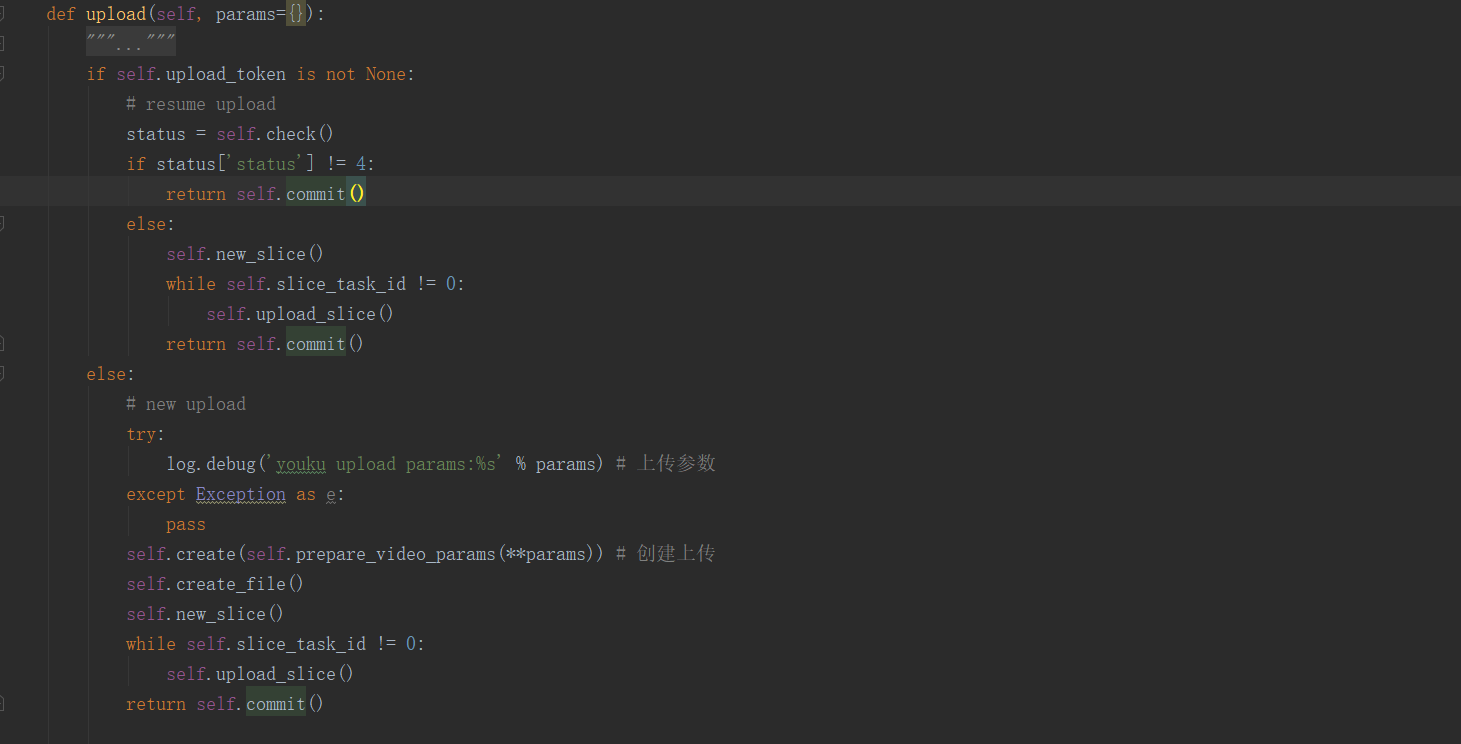
return int(self.transferred / self.file_size) def upload(self, params={}):
"""start uploading the file until upload is complete or error.
This is the main method to used, If you do not care about
state of process. Args:
params: a dict object describe video info, eg title,
tags, description, category.
all video params see the doc of prepare_video_params. Returns:
return video_id if upload successfully
"""
if self.upload_token is not None:
# resume upload
status = self.check()
if status['status'] != 4:
return self.commit()
else:
self.new_slice()
while self.slice_task_id != 0:
self.upload_slice()
return self.commit()
else:
# new upload
try:
log.debug('youku upload params:%s' % params) # 记录上传参数
except Exception as e:
pass
self.create(self.prepare_video_params(**params)) # 创建上传
self.create_file()
self.new_slice()
while self.slice_task_id != 0:
self.upload_slice()
return self.commit()
优酷上传SDK解析(Python)的更多相关文章
- IT轮子系列(六)——Excel上传与解析,一套代码解决所有Excel业务上传,你Get到了吗
前言 在日常开发当中,excel的上传与解析是很常见的.根据业务不同,解析的数据模型也都不一样.不同的数据模型也就需要不同的校验逻辑,这往往需要写多套的代码进行字段的检验,如必填项,数据格式.为了避免 ...
- php文件上传代码解析
php文件上传代码解析 is_uploaded_file() //函数判断指定的文件是否是通过 HTTP POST 上传的,返回一个布尔值. $_FILES['upfile']['tmp_name' ...
- Web攻防系列教程之文件上传攻防解析(转载)
Web攻防系列教程之文件上传攻防解析: 文件上传是WEB应用很常见的一种功能,本身是一项正常的业务需求,不存在什么问题.但如果在上传时没有对文件进行正确处理,则很可能会发生安全问题.本文将对文件上传的 ...
- springMVC:为MultipartFilte配置了上传文件解析器,报错或不能使用
一.问题描述为支持restful风格请求,并且应对可能上传文件的情况,需要在配置hiddenHttpMethodFilter过滤器之前配置MultipartFilter.目的是让MultipartFi ...
- java 文件上传与解析(excel,txt)
excel上传与解析 https://blog.csdn.net/zsysu_it/article/details/79074067 txt解析 https://blog.csdn.net/CSDNw ...
- salesforce lightning零基础学习(十七) 实现上传 Excel解析其内容
本篇参考: https://developer.mozilla.org/zh-CN/docs/Web/API/FileReader https://github.com/SheetJS/sheetjs ...
- Salesforce LWC学习(三十二)实现上传 Excel解析其内容
本篇参考:salesforce lightning零基础学习(十七) 实现上传 Excel解析其内容 上一篇我们写了aura方式上传excel解析其内容.lwc作为salesforce的新宠儿,逐渐的 ...
- 实现Excel文件的上传和解析
前言 本文思维导图 一.需求描述 实现一个页面上传excel的功能,并对excel中的内容做解析,最后存储在数据库中. 二.代码实现 需求实现思路: 先对上传的文件做校验和解析,这里我们通过Excel ...
- 上传自己的Python代码到PyPI
一.需要准备的事情 1.当然是自己的Python代码包了: 2.注册PyPI的一个账号. 二.详细介绍 1.代码包的结构: application \application __init__.py m ...
随机推荐
- 长期更新系列:C#知识点
PS:写这个主要是基础差,写这么一个主要是为了自己查漏补缺,不会的搞会了.会了搞的更会.顺便整理知识. 目录 1.C#知识点:值类型和引用类型 2.C#知识点:I/0 3.C#知识点:is和as 4. ...
- jQuery设置下拉框select 默认选中第一个option
$("#id option:first").prop("selected", 'selected');
- VS本地调试 Visual Studio远程调试监视器(MSVSMON.EXE)的32位版本不能用于调试64位进程或64位转储
vs2017 调试一致都没啥问题,今天莫名报这个错误,感觉好奇怪,网上搜索了半天也没解决,最后看着错误信息感觉很诡异,我本地调试你给我启动远程调试监测器干嘛,localhost也访问不了,ping了一 ...
- django 数据库 ORM创建表单是出错
WARNINGS: ?: (mysql.W002) MySQL Strict Mode is not set for database connection 'default' HINT: MySQL ...
- 自定义TableViewCell 的方式实现自定义TableView(带源码)
转载于:http://www.cnblogs.com/macroxu-1982/archive/2012/08/30/2664121.html 实现的效果 实现过程 Step One 创建 自定义Ta ...
- curl 封装类
<?php /** * author: zbseoag * QQ: 617937424 用法: $content = Curl::instance()->url($url)->get ...
- PHP通过api上传图片
参考:接口实现图片上传 提交端: $url="localhost:805/rdyc/123.jpg"; $img=file_get_contents($url); $img_api ...
- Google JavaScript样式指南
Google JavaScript样式指南 目录 1简介 1.1术语说明 1.2指南说明 2源文件基础知识 2.1文件名 2.2文件编码:UTF-8 2.3特殊字符 3源文件结构 3.1许可或版权 ...
- OTSU算法学习 OTSU公式证明
OTSU算法学习 OTSU公式证明 1 otsu的公式如下,如果当前阈值为t, w0 前景点所占比例 w1 = 1- w0 背景点所占比例 u0 = 前景灰度均值 u1 = 背景灰度均值 u = ...
- spring boot(14)-pom.xml配置
继承spring-boot-starter-parent 要成为一个spring boot项目,首先就必须在pom.xml中继承spring-boot-starter-parent,同时指定其版本 & ...