Hadoop1.x集群安装部署(VMware)
一、hadoop版本介绍
不收费的Hadoop版本主要有三个(均是国外厂商),分别是:Apache(最原始的版本,所有发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称
CDH)、Hortonworks版本(Hortonworks Data Platform,简称“HDP”),对于国内而言,绝大多数选择CDH版本。
Cloudera的CDH和Apache的Hadoop对应关系:
CDH的两个系列版本分别是CDH3和CDH4,CDH3对应Hadoop 1.0(Apache Hadoop 0.20.x、1.x),CDH4对应Hadoop 2.0(Apache Hadoop 0.23.x、2.x)。
本文选择CDH3进行安装测试
Cloudera下载页面:http://archive.cloudera.com/cdh/3/
Hadoop版本:http://archive.cloudera.com/cdh/3/hadoop-0.20.2-CDH3B4.tar.gz
二、开始安装
系统版本:CentOS Linux release 7.1.1503 (Core)
1、关闭防火墙:部署Hadoop集群时,master与slave的防火墙均要关闭。关闭防火墙的根本目的也是为了图省事儿,因为在使用HDFS与MapReduce时,Hadoop会打开许多监听端口。
此处参见:http://www.open-open.com/lib/view/open1411818940031.html
2、创建一个用户
#新增一个用户组
groupadd hadoop
#新增一个用户并设置为hadoop组成员
useradd -g hadoop hadoop
#设置hadoop用户密码
passwd hadoop
3、解压hadoop
#切换到hadoop用户,再解压
su -l hadoop
4、修改配置
1)修改hadoop-env.sh
修改JAVA_HOME

2)修改core-site.xml

说明一:hadoop分布式文件系统文件存放位置都是基于hadoop.tmp.dir目录的,namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name, datanode数据块的存放地方就是
${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。
说明二:fs.default.name,设置namenode所在主机,端口号是9000
3)修改hdfs-site.xml

dfs.replication,设置数据块的复制次数,默认是3,如果slave节点数少于3,则写成相应的1或者2,副本数设置多余datanode也不会起作用
4)修改mapred-site.xml
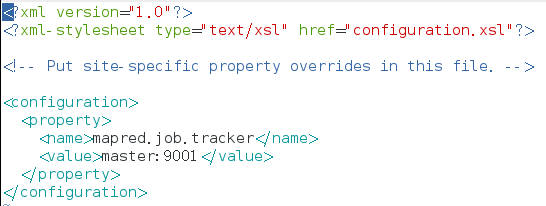
mapred.job.tracker,设置jobtracker所在机器,端口号9001
5)修改masters和slaves文件
masters中

slaves中

5、VMware拷贝(略)
6、配置静态IP
修改文件 vi /etc/sysconfig/network-scripts/ifcfg-enoxxx
BOOTPROTO=static #启用静态IP地址
ONBOOT=yes #开启自动启用网络连接 设置开机启动,一定要记得修改
IPADDR0=192.168.220.128 #设置IP地址
PREFIXO0=255.255.255.0 #设置子网掩码
GATEWAY0=192.168.220.2 #设置网关
配置host /etc/hosts
192.168.220.128 master
192.168.220.129 slave1
192.168.220.130 slave2
6、建立SSH互信
Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果
hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
生成公钥和私钥
这里密钥的存放位置为:/home/hadoop/.ssh/id_rsa下,之前没有按照此方式存放,造成无验证ssh登录失败。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

id_rsa是私钥,id_rsa.pub是公钥

公钥重命名
cp id_rsa.pub authorized_keys
单机ssh免密码登录测试
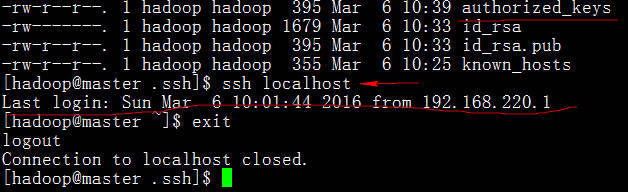
要实现主节点(master)免密码登录登录子节点(slave),slave结点的公钥文件中必须要包含主结点的公钥信息(注:slave节点要各自进行一次密钥生成过程(ssh-keygen))。
scp authorized_keys hadoop@slave1:/home/hadoop/.ssh/

验证一下
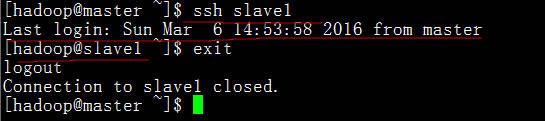
master免密码登录slave1成功
相同的方式,将master的公钥拷贝到slave2节点
scp authorized_keys hadoop@slave2:/home/hadoop/.ssh/
7、运行hadoop
1)配置环境变量
2)在主节点格式化:hadoop namenode -format
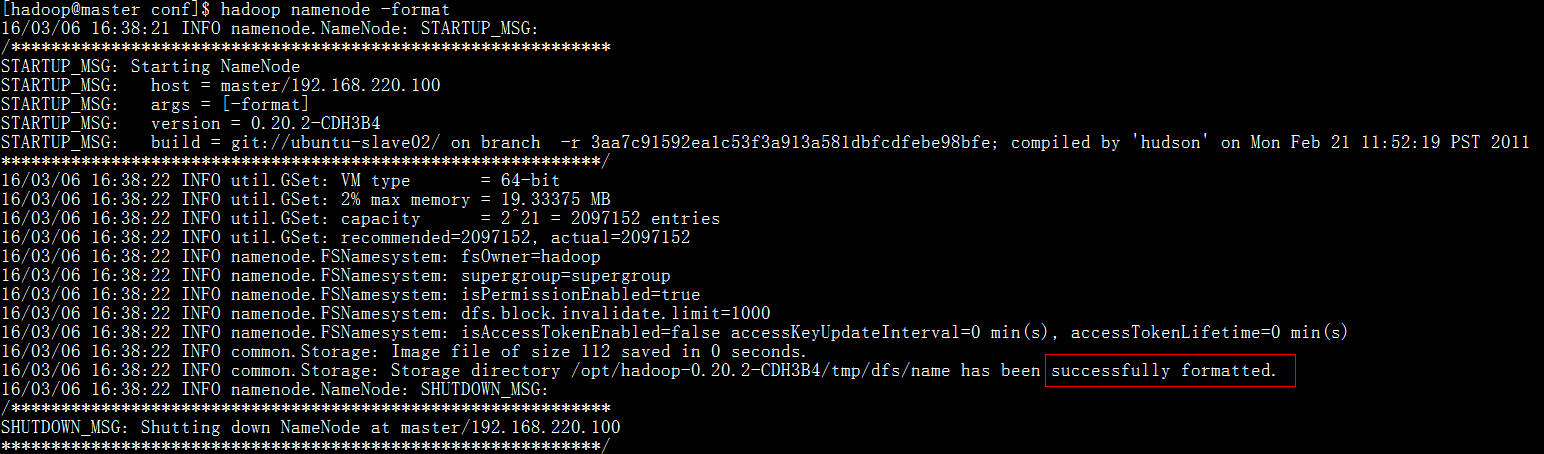
3)启动start-all.sh

4)检查主节点进程
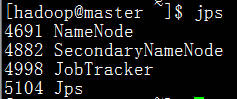
5)检查两个slave节点

至此,所有进程启动成功。
8、通过浏览器访问检查集群情况
http://192.168.220.128:50030/jobtracker.jsp
http://192.168.220.128:50070/dfshealth.jsp
Hadoop1.x集群安装部署(VMware)的更多相关文章
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- K8S集群安装部署
K8S集群安装部署 参考地址:https://www.cnblogs.com/xkops/p/6169034.html 1. 确保系统已经安装epel-release源 # yum -y inst ...
- 【分布式】Zookeeper伪集群安装部署
zookeeper:伪集群安装部署 只有一台linux主机,但却想要模拟搭建一套zookeeper集群的环境.可以使用伪集群模式来搭建.伪集群模式本质上就是在一个linux操作系统里面启动多个zook ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Hadoop2.2集群安装配置-Spark集群安装部署
配置安装Hadoop2.2.0 部署spark 1.0的流程 一.环境描写叙述 本实验在一台Windows7-64下安装Vmware.在Vmware里安装两虚拟机分别例如以下 主机名spark1(19 ...
随机推荐
- 打包python为可执行文件时报错R6034解决方案
R6034 指的是:”An application has made an attempt to load the C runtime library incorrectly. Please cont ...
- html转jsp部分css不可用
解决方法 <%String path = request.getContextPath();String basePath = request.getScheme()+"://&quo ...
- 二)spring 集成 ehcache jgroups 集群
依赖 <dependency> <groupId>org.springframework</groupId> <artifactId>spring-co ...
- passwd: Have exhausted maximum number of retries for service
使用命令passwd修改密码时,遇到如下问题:# echo 'utf8'|passwd zhangsan --stdinChanging password for user zhangsan.pass ...
- hdu 5066 小球碰撞(物理题)
http://acm.hdu.edu.cn/showproblem.php?pid=5066 中学物理题 #include <cstdio> #include <cstdlib> ...
- Oracle sql 优化の常用方式
1.不要用 '*' 代替所有列名,特别是字段比较多的情况下 使用select * 可以列出某个表的所有列名,但是这样的写法对于Oracle来说会存在动态解析问题.Oracle系统通过查询数据字典将 ' ...
- Postgres重置自增长id列(reset sequence)
简单的两个方法,个人比较喜欢第一个 ①ALTER SEQUENCE seq RESTART WITH 1;② SELECT setval('sequence_name', 0); 参考自http:// ...
- 【 PLSQL Developer安装、tnsnames.ora配置 解答】
使用plsql远程连接数据库需要安装plsql工具+ oracle的远程客户端 在不登录的状态打开plsql: 点击工具---首选项:指定oracle客户端的安装路径: C:\javaSoft\PLS ...
- Asp.Net 跨域,Asp.Net MVC 跨域,Session共享,CORS,Asp.Net CORS,Asp.Net MVC CORS,MVC CORS
比如 http://www.test.com 和 http://m.test.com 一.简单粗暴的方法 Web.Config <system.web> <!--其他配置 省略……- ...
- ASP .Net Core路由(Route) - 纸壳CMS的关键
关于纸壳CMS 纸壳CMS是一个开源免费的,可视化设计,在线编辑的内容管理系统.基于ASP .Net Core开发,插件式设计: GitHub:https://github.com/SeriaWei/ ...