Hadoop1.x集群安装部署(VMware)
一、hadoop版本介绍
不收费的Hadoop版本主要有三个(均是国外厂商),分别是:Apache(最原始的版本,所有发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称
CDH)、Hortonworks版本(Hortonworks Data Platform,简称“HDP”),对于国内而言,绝大多数选择CDH版本。
Cloudera的CDH和Apache的Hadoop对应关系:
CDH的两个系列版本分别是CDH3和CDH4,CDH3对应Hadoop 1.0(Apache Hadoop 0.20.x、1.x),CDH4对应Hadoop 2.0(Apache Hadoop 0.23.x、2.x)。
本文选择CDH3进行安装测试
Cloudera下载页面:http://archive.cloudera.com/cdh/3/
Hadoop版本:http://archive.cloudera.com/cdh/3/hadoop-0.20.2-CDH3B4.tar.gz
二、开始安装
系统版本:CentOS Linux release 7.1.1503 (Core)
1、关闭防火墙:部署Hadoop集群时,master与slave的防火墙均要关闭。关闭防火墙的根本目的也是为了图省事儿,因为在使用HDFS与MapReduce时,Hadoop会打开许多监听端口。
此处参见:http://www.open-open.com/lib/view/open1411818940031.html
2、创建一个用户
#新增一个用户组
groupadd hadoop
#新增一个用户并设置为hadoop组成员
useradd -g hadoop hadoop
#设置hadoop用户密码
passwd hadoop
3、解压hadoop
#切换到hadoop用户,再解压
su -l hadoop
4、修改配置
1)修改hadoop-env.sh
修改JAVA_HOME

2)修改core-site.xml

说明一:hadoop分布式文件系统文件存放位置都是基于hadoop.tmp.dir目录的,namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name, datanode数据块的存放地方就是
${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。
说明二:fs.default.name,设置namenode所在主机,端口号是9000
3)修改hdfs-site.xml

dfs.replication,设置数据块的复制次数,默认是3,如果slave节点数少于3,则写成相应的1或者2,副本数设置多余datanode也不会起作用
4)修改mapred-site.xml
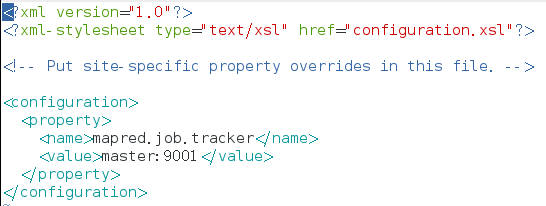
mapred.job.tracker,设置jobtracker所在机器,端口号9001
5)修改masters和slaves文件
masters中

slaves中

5、VMware拷贝(略)
6、配置静态IP
修改文件 vi /etc/sysconfig/network-scripts/ifcfg-enoxxx
BOOTPROTO=static #启用静态IP地址
ONBOOT=yes #开启自动启用网络连接 设置开机启动,一定要记得修改
IPADDR0=192.168.220.128 #设置IP地址
PREFIXO0=255.255.255.0 #设置子网掩码
GATEWAY0=192.168.220.2 #设置网关
配置host /etc/hosts
192.168.220.128 master
192.168.220.129 slave1
192.168.220.130 slave2
6、建立SSH互信
Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果
hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
生成公钥和私钥
这里密钥的存放位置为:/home/hadoop/.ssh/id_rsa下,之前没有按照此方式存放,造成无验证ssh登录失败。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

id_rsa是私钥,id_rsa.pub是公钥

公钥重命名
cp id_rsa.pub authorized_keys
单机ssh免密码登录测试
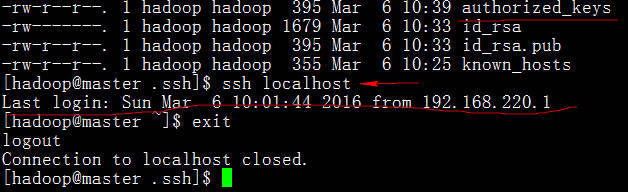
要实现主节点(master)免密码登录登录子节点(slave),slave结点的公钥文件中必须要包含主结点的公钥信息(注:slave节点要各自进行一次密钥生成过程(ssh-keygen))。
scp authorized_keys hadoop@slave1:/home/hadoop/.ssh/

验证一下
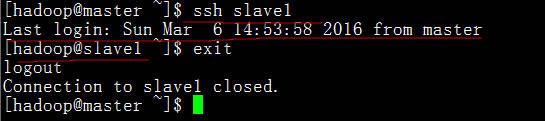
master免密码登录slave1成功
相同的方式,将master的公钥拷贝到slave2节点
scp authorized_keys hadoop@slave2:/home/hadoop/.ssh/
7、运行hadoop
1)配置环境变量
2)在主节点格式化:hadoop namenode -format
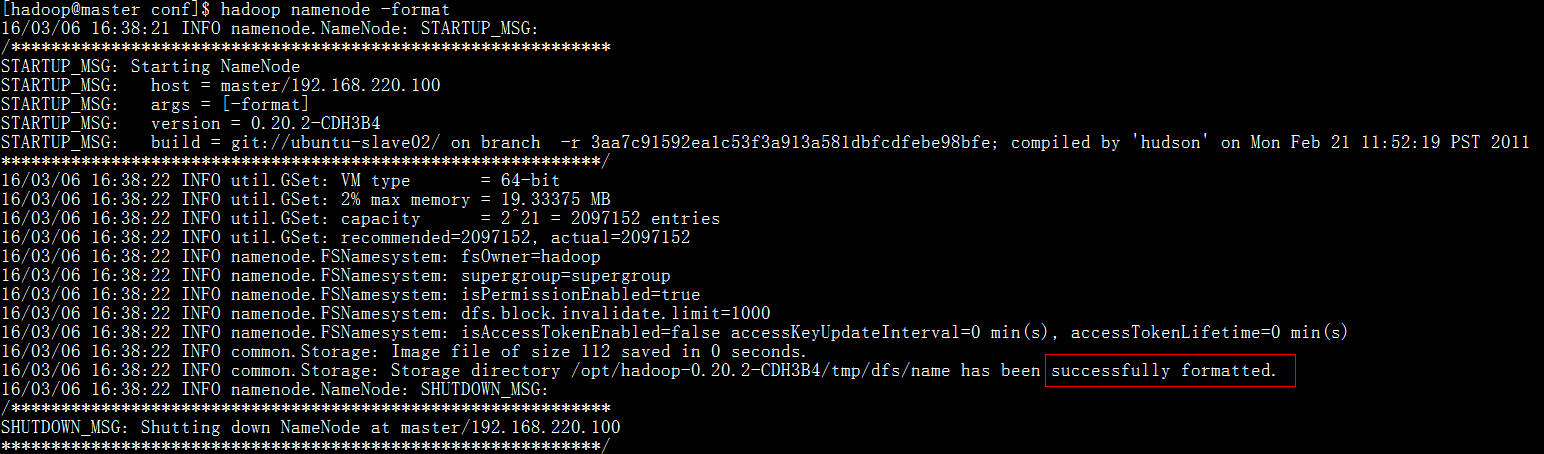
3)启动start-all.sh

4)检查主节点进程
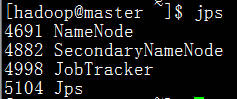
5)检查两个slave节点

至此,所有进程启动成功。
8、通过浏览器访问检查集群情况
http://192.168.220.128:50030/jobtracker.jsp
http://192.168.220.128:50070/dfshealth.jsp
Hadoop1.x集群安装部署(VMware)的更多相关文章
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- K8S集群安装部署
K8S集群安装部署 参考地址:https://www.cnblogs.com/xkops/p/6169034.html 1. 确保系统已经安装epel-release源 # yum -y inst ...
- 【分布式】Zookeeper伪集群安装部署
zookeeper:伪集群安装部署 只有一台linux主机,但却想要模拟搭建一套zookeeper集群的环境.可以使用伪集群模式来搭建.伪集群模式本质上就是在一个linux操作系统里面启动多个zook ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Hadoop2.2集群安装配置-Spark集群安装部署
配置安装Hadoop2.2.0 部署spark 1.0的流程 一.环境描写叙述 本实验在一台Windows7-64下安装Vmware.在Vmware里安装两虚拟机分别例如以下 主机名spark1(19 ...
随机推荐
- POJ 1061 青蛙的约会(扩展欧几里德算法)
题意:两只青蛙在同一个纬度上跳跃,给定每个青蛙的开始坐标和每秒跳几个单位,纬度长为L,求它们相遇的最短时间. 析:开始,一看只有一组数据,就想模拟一下,觉得应该不会超时,但是不幸的是TLE了,我知道这 ...
- LA 4670 Dominating Patterns (AC自动机)
题意:给定n个字符串和一个文本串,查找哪个字符串出现的次数的最多. 析:一匹配多,很明显是AC自动机.只需要对原来的进行修改一下,就可以得到这个题的答案, 计算过程中,要更新次数,并且要映射字符串.如 ...
- MEF程序设计指南
############################################################################################## ##### ...
- SSH整合 第四篇 Spring的IoC和AOP
这篇主要是在整合Hibernate后,测试IoC和AOP的应用. 1.工程目录(SRC) 2.IoC 1).一个Service测试类 /* * 加入spring容器 */ private Applic ...
- Intellij IDEA 14的注册机(Java版)
import java.math.BigInteger; import java.util.Date; import java.util.Random; import java.util.zip.CR ...
- Java核心编程快速学习(转载)
http://www.cnblogs.com/wanliwang01/p/java_core.html Java核心编程部分的基础学习内容就不一一介绍了,本文的重点是JAVA中相对复杂的一些概念,主体 ...
- ABP 基础设施层——集成 Entity Framework
本文翻译自ABP的官方教程<EntityFramework Integration>,地址为:http://aspnetboilerplate.com/Pages/Documents/En ...
- 使用jetty-maven-plugin运行maven多项目
1.准备工作 org.eclipse.jetty jetty-maven-plugin 9.2.11.v20150529 jdk 1.7 maven 3.1 2.采用maven管理多项目 ...
- [翻译]NUnit---Range and Repeat Attributes(十五)
RangeAttribute (NUnit 2.5) Range特性用于为参数话测试方法的参数的值范围指定一个值,与Random特性一样,NUnit会将每个参数的值组合为一些了测试用例,所以如果为一个 ...
- QuartzNet3.0实现作业调度
Quartz是一个完全由JAVA编写的开源作业调度框架. Quartz.NET是Quartz的.NET移植,它用C#写成,可用于.Net以及.Net Core的应用中. 目前最新的quartz.net ...