记一次简单爬虫(豆瓣/dytt)
磕磕绊绊学python一个月,这次到正则表达式终于能写点有趣的东西,在此作个记录:
—————————————————————————————————————————————————
1.爬取豆瓣电影榜前250名单
运行环境:
pycharm-professional-2018.2.4
3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)]
成品效果:


相关代码:
from urllib.request import urlopen
import re
# import ssl # 若有数字签名问题可用
# ssl._create_default_https_context = ssl._create_unverified_context # 写正则规则
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?导演:(?P<daoyan>.*?) .*?'
r'主演:(?P<zhuyan>.*?)<br>\n (?P<shijian>.*?) / (?P<diqu>.*?) '
r'/ (?P<leixing>.*?)\n.*?<span class="rating_num" property="v:average">(?P<fen>.*?)</span>.*?<span>'
r'(?P<renshu>.*?)评价</span>.*?<span class="inq">(?P<jianping>.*?)</span>',re.S) # re.S 干掉换行 # 转码 获取内容
def getContent(url):
content = urlopen(url).read().decode("utf-8")
return content # 匹配页面内容 返回一个迭代器
def parseContent(content):
iiter = obj.finditer(content)
for el in iiter:
yield {
"name":el.group("name"),
"daoyan":el.group("daoyan"),
"zhuyan":el.group("zhuyan"),
"shijian":el.group("shijian"),
"diqu":el.group("diqu"),
"leixing":el.group("leixing"),
"fen":el.group("fen"),
"renshu":el.group("renshu"),
"jianping":el.group("jianping")
} for i in range(10):
url = "https://movie.douban.com/top250?start=%s&filter=" % (i*25) # 循环页面10
print(url)
g = parseContent(getContent(url)) # 匹配获取的内容返回给g
f = open("douban_movie.txt",mode="a",encoding="utf-8")
for el in g:
f.write(str(el)+"\n") # 写入到txt 注意加上换行 # f.write("==============================================") # 测试分页
f.close()
2.爬取某站最新电影和下载地址
运行环境:
pycharm-professional-2018.2.4
3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)]
成品效果:
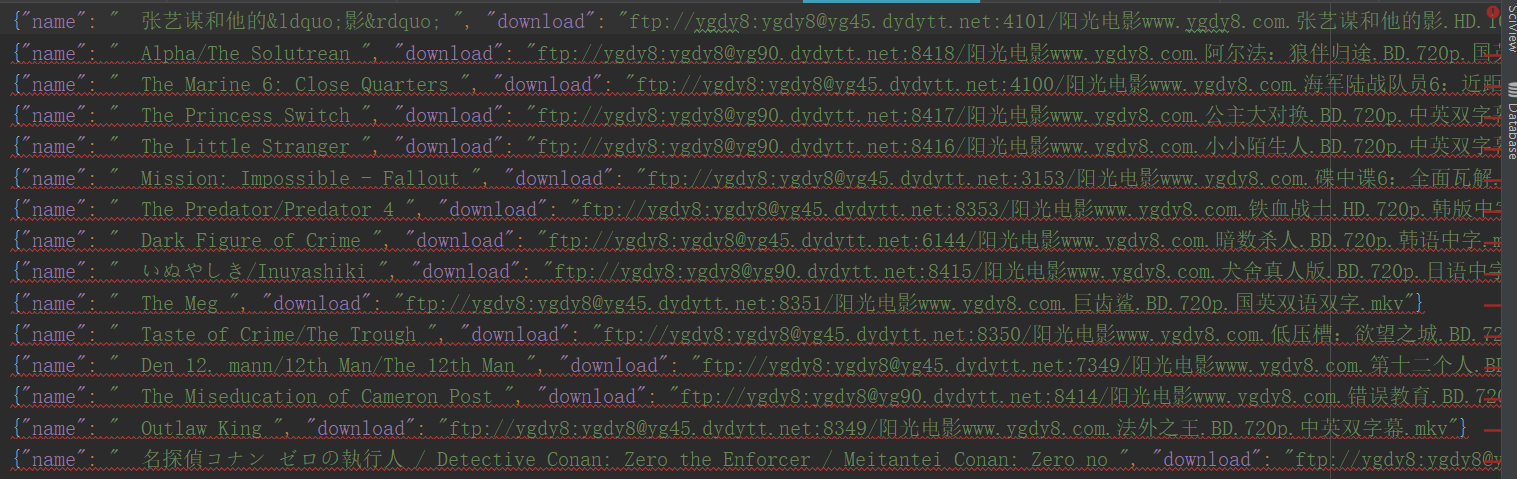
相关代码:
from urllib.request import urlopen
import json
import re # 获取主页面内容
url = "https://www.dytt8.net/"
content = urlopen(url).read().decode("gbk")
# print(content) # 正则
obj = re.compile(r'.*?最新电影下载</a>]<a href=\'(?P<url1>.*?)\'>', re.S)
obj1 = re.compile(r'.*?<div id="Zoom">.*?<br />◎片 名(?P<name>.*?)<br />.*?bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S) def get_content(content):
res = obj.finditer(content)
f = open('movie_dytt.json', mode='w', encoding='utf-8')
for el in res:
res = el.group("url1")
res = url + res # 拼接子页面网址 content1 = urlopen(res).read().decode("gbk") # 获取子页面内容
lst = obj1.findall(content1) # 匹配obj1返回一个列表
# print(lst) # 元组
name = lst[0][0]
download = lst[0][1]
s = json.dumps({"name":name,"download":download},ensure_ascii=False)
f.write(s+"\n")
f.flush()
f.close() get_content(content) # 调用函数 执行
记一次简单爬虫(豆瓣/dytt)的更多相关文章
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
随机推荐
- 【JavaScript】10个重要知识点
1. 立即执行函数 立即执行函数,即Immediately Invoked Function Expression (IIFE),正如它的名字,就是创建函数的同时立即执行.它没有绑定任何事件,也无需等 ...
- 克隆linux虚拟机
背景:有时候,我们在用虚拟机的时候会用到多个进行使用.重新安装会花费大量的时间,此时,我们可以通过vmware虚拟机自带的功能快速克隆出完全相同的系统. 前提:被克隆的虚拟机系统要处于关闭状态 步骤: ...
- day 33js 后续 函数.对象
前情提要: 今天学习的是js的函数以及简单的类的使用 一:函数的初识别 <!DOCTYPE html> <html lang="en"> <head& ...
- docker下 klee第一个测试
被测试的简单函数源文件位于 /klee_src/examples/get_sign 目录下 该源代码分为三个部分 第一个部分为被测试的函数 int get_sign(int x) { if (x = ...
- mysql中授权其它电脑链接指令。
grant all privileges on yourDatabaseName to 'user'@'databaseIPAddress' identified by 'password' with ...
- 【PKUSC2018】【loj6433】最大前缀和 状压dp
这题吼啊... 然而还是想了$2h$,写了$1h$. 我们发现一个性质:若一个序列$p$能作为前缀和,那么在序列$p$中,包含序列$p$最后一个数的所有子序列必然都是非负的. 那么,我们 令$f[i] ...
- WebDriverAPI(10)
操作Frame页面元素 测试网址代码 frameset.html: <html> <head> <title>frameset页面</title> &l ...
- php在浏览器禁止cookie后,仍然能使用session的方法
1.a.php页面 session_start(); $_SESSION['msg'] = "i love you"; $sn = session_id();//获取当前sessi ...
- C++中模板与泛型编程
目录 定义一个通用模板 模板特化和偏特化 模板实例化与匹配 可变参数模板 泛型编程是指独立与任何类型的方式编写代码.泛型编程和面向对象编程,都依赖与某种形式的多态.面向对象编程的多态性在运行时应用于存 ...
- Math.floor,Math.ceil,Math.rint,Math.round用法
一.Math.floor函数讲解 floor原意:地板.Math.floor函数是求一个浮点数的地板,就是求一个最接近它的整数,它的值小于或等于这个浮点数.看下面的例子: package com.qi ...