批量下载小说网站上的小说(python爬虫)
随便说点什么
因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的。
想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊!
所以我就被这块大蛋糕吸引过来了 :)
想学爬虫自然要去找学习资料了,不过网上有很多,我找了不少,个人觉得崔庆才的爬虫教程写得不错。起码对我来说,入门是够了。
感兴趣的朋友可以点进链接看看:Python爬虫学习系列教程 <==这位兄台博客做得也很好
掌握了基本的爬虫知识,主要是urllib,urlib2,re 这些库,以及Request(),urlopen()的基本用法之后,我就开始寻找爬取目标。
正好女朋友的哥哥让她帮忙下载小说,找我推荐几本,我一时也不知道他哥喜欢什么类型的,心想干脆找个小说网批量下载一些小说。
于是说干就干,用了一个中午时间写了一个粗糙的爬虫脚本,启动发现可以运行,让脚本在这儿跑着,我回去躺在床上呼呼大睡。
起来之后发现脚本遇到错误,停掉了,于是debug,干掉bug之后跑起来陆续又发现几个错误,于是干脆在一些容易出错的地方,例如urlopen()请求服务器的地方,本地write()写入的地方(是的,这也会有超时错误!)加入了try-except捕获错误进行处理,另外加入了socket.timeout网络超时限制,修修补补之后总算可以顺畅的运行。
如此,运行了两天,爬虫脚本把这个小说网上的几乎所有小说都下载到了本地,一共27000+本小说,一共40G。
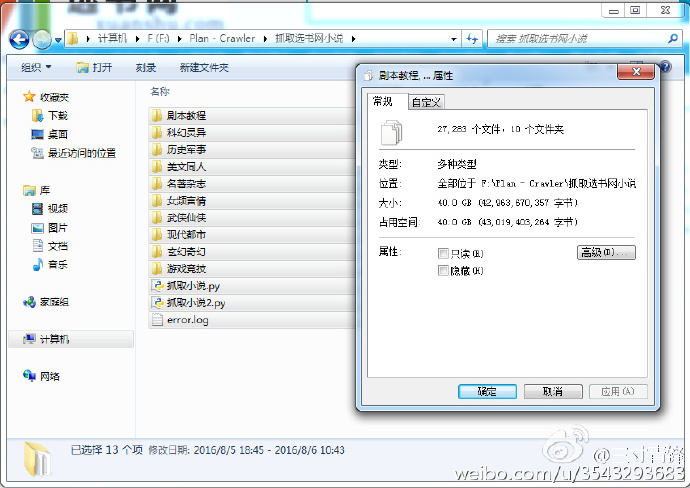
自此,大功告成,打包发了过去。另外说一句,百度云真坑,每次上传数量有限制,分享给朋友文件数量有限制,分享的文件夹大小也有限制,害的我还得整成压缩版才能分享。
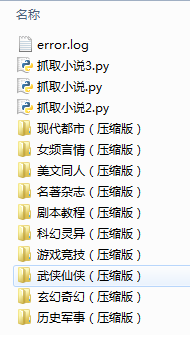
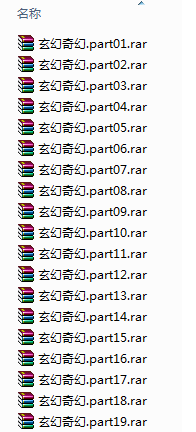
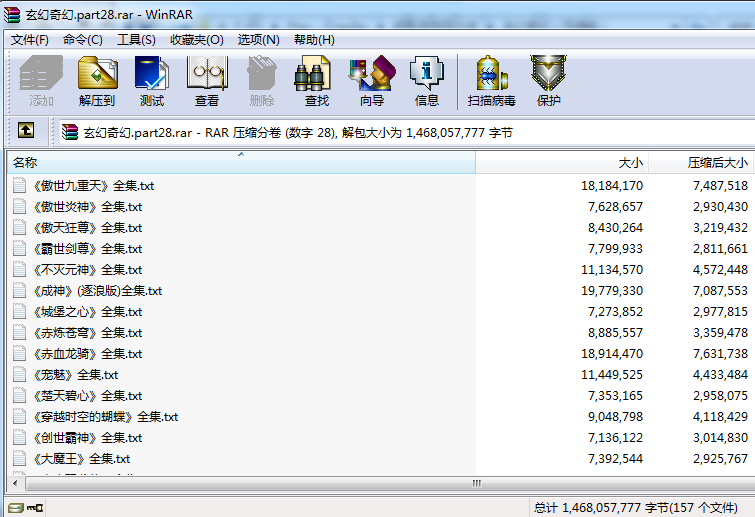
下载界面
下面附上代码
#coding=utf-8
import urllib
import urllib2
import re
import os webroot = 'http://www.xuanshu.com' for page in range(20,220):
print '正在下载第'+str(page)+'页小说' url = 'http://www.xuanshu.com/soft/sort02/index_'+str(page)+'.html'
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6' }
try:
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request,timeout=180)
#print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason html = response.read().decode('utf-8')
#print html
pattern = re.compile(u'<li>.*?<div class="s">.*?target="_blank">(.*?)</a><br />大小:(.*?)<br>.*?</em><br>更新:(.*?)</div>.*?<a href="(.*?)"><img.*?>(.*?)</a>.*?<div class="u">(.*?)</div>',re.S)
items = re.findall(pattern,html)
#print items for item in items:
try:
book_auther = item[0].encode('gbk')
book_size = item[1].encode('gbk')
book_updatetime = item[2].encode('gbk')
book_link = item[3].encode('gbk')
book_name = item[4].encode('gbk')
book_note = item[5].encode('gbk') book_full_link = webroot + book_link # 构建书的绝对地址 #请求地址
try:
request = urllib2.Request(book_full_link,headers=headers)
response = urllib2.urlopen(request,timeout=180)
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
html = response.read().decode('utf-8')
#print html
pattern = re.compile('<a class="downButton.*?<a class="downButton" href=\'(.*?)\'.*?Txt.*?</a>',re.S)
down_link = re.findall(pattern,html)
print book_name
print down_link # down txt
try:
request = urllib2.Request(down_link[0].encode('utf-8'),headers=headers)
response = urllib2.urlopen(request,timeout=180)
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
try:
fp = open(book_name+'.txt','w')
except IOError,e:
pattern = re.compile('<strong>.*?>(.*?)<.*?</strong>',re.S)
book_name = re.findall(pattern,book_name)
fp = open(book_name[0]+'.txt','w')
print 'start download'
fp.write(response.read())
print 'down finish\n'
fp.close()
except Exception,e:
print '该条目解析出现错误,忽略'
print e
print ''
fp = open('error.log','a')
fp.write('page:'+str(page)+'\n')
fp.write(item[4].encode('gbk'))
#fp.write(e)
fp.write('\nThere is an error in parsing process.\n\n')
fp.close()
注意
该脚本只定向抓取“选书网”小说站,“玄幻奇幻”分类下的小说。供网友们参考,可自行修改。
写得比较粗糙,勿喷……
Freecode# : www.cnblogs.com/yym2013
批量下载小说网站上的小说(python爬虫)的更多相关文章
- 利用SkyDrive Pro 迅速批量下载SharePoint Server 上已上传的文件
在上一篇<SharePoint Server 2013 让上传文件更精彩>,我们一起了解了如何快速的方便的上传批量文件到SharePoint Server 2013 ,而在这一篇日志中您将 ...
- Linux运维之批量下载指定网站的100个图片文件,并找出大于200KB的文件
题目为: 有一百个图片文件,它们的地址都是http://down.fengge.com/img/1.pnghttp://down.fengge.com/img/2.png…一直到http://dow ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
- Scrapy采集某小说网站的全部小说
链接: https://pan.baidu.com/s/1hrgYDzhgQIDrf4KmZxhW1w 密码: h1m6 源码以及运行图
- 在 Windows Azure 网站上使用 Django、Python 和 MySQL:创建博客应用程序
编辑人员注释:本文章由 Windows Azure 网站团队的项目经理 Sunitha Muthukrishna 撰写. 根据您编写的应用程序,Windows Azure 网站上的基本Python 堆 ...
- 基于七牛Python SDK写的一个批量下载脚本
前言 上一篇基于七牛Python SDK写的一个同步脚本所写的脚本只支持上传,不支持文件下载. 虽然这个需求不太强烈,但有可能有人(在备份.迁移时)需要,而官方有没提供对应的工具,所以我就把这个功能也 ...
- KRPano资源分析工具使用说明(KRPano XML/JS解密 切片图批量下载 球面图还原 加密混淆JS还原美化)
软件交流群:571171251(软件免费版本在群内提供) krpano技术交流群:551278936(软件免费版本在群内提供) 最新博客地址:blog.turenlong.com 限时下载地址:htt ...
- 使用KRPano资源分析工具一键下载全景网站切片图
软件交流群:571171251(软件免费版本在群内提供) krpano技术交流群:551278936(软件免费版本在群内提供) 最新博客地址:blog.turenlong.com 限时下载地址:htt ...
- python爬虫实战1
转载于:http://blog.csdn.net/dongnanyanhai/article/details/5552431 首先推荐一个网站:中医世家,这个网站上有很多关于中医的资料,光是提供的中医 ...
随机推荐
- Linux虚拟机中配置JDK环境变量
前提准备: 1,安装好Linux系统 2,下载好可以将文件传输到Linux系统工具例如:WinSCP 3,在windows中下载Linux版JDK: http://download.oracle.co ...
- IRequiresSessionState接口控制
刚刚接触.net web端的朋友都会被Session坑过,莫名其妙的不能读取Session数据,后来知道原来有IRequiresSessionState这个接口,不继承的就不能读取Session里面的 ...
- 检查Linux服务器性能
如果你的Linux服务器突然负载暴增,告警短信快发爆你的手机,如何在最短时间内找出Linux性能问题所在? 概述通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解. • uptime• ...
- 跟我一起学习VIM
跟我一起学习VIM - The Life Changing Editor 前两天同事让我在小组内部分享一下VIM,于是我花了一点时间写了个简短的教程.虽然准备有限,但分享过程中大家大多带着一种惊叹 ...
- emulator control无法使用问题
请使用Google 自带的控制器:
- linux下安装postgresql
环境:Linux localhost.localdomain 2.6.32-431 GNU/Linux x86_64 Postgresql版本:postgresql.9.5.3 添加开启自启设置:ht ...
- 2. web前端开发分享-css,js进阶篇
一,css进阶篇: 等css哪些事儿看了两三遍之后,需要对看过的知识综合应用,这时候需要大量的实践经验, 简单的想法:把qq首页全屏另存为jpg然后通过ps工具切图结合css转换成html,有无从下手 ...
- [从产品角度学EXCEL 03]-单元格的秘密
这是<从产品角度学EXCEL>系列——单元格的秘密. 前言请看: 0 为什么要关注EXCEL的本质 1 EXCEL是怎样运作的 2 EXCEL里的树形结构 或者你可以去微信公众号@尾巴说数 ...
- User space 与 Kernel space
学习 Linux 时,经常可以看到两个词:User space(用户空间)和 Kernel space(内核空间). 简单说,Kernel space 是 Linux 内核的运行空间,User spa ...
- [mark] 使用Sublime Text 2时如何将Tab配置为4个空格
在Mac OS X系统下,Sublime Text是一款比较赞的编辑器. 作为空格党的自觉,今天mark一下使用Sublime Text 2时如何将Tab配置为4个空格: 方法来自以下两个链接: ht ...