Python爬虫个人记录(四)利用Python在豆瓣上写一篇日记
涉及关键词:requests库 requests.post方法 cookies登陆
version 1.5(附录):使用post方法登陆豆瓣,成功! 缺点:无法获得登陆成功后的cookie,要使用js等方法来获得cookie,放弃
versoin 2.0(附录): 使用selenium模拟浏览器登陆豆瓣,使用浏览器自动加载js,并成功获取cookies,可以为后来浏览使用,可行,成功!
一、目的分析
利用cookie登陆豆瓣,并写一篇日记
https://www.douban.com/note/636142594/
二、步骤分析
1、使用浏览器登陆豆瓣,得到并分析cookie
2、使用cookie模拟登陆豆瓣(使用账号密码登陆也可以,需要验证码,cookie的时效一般就几天)
3、分析浏览器写日记行为,在python中模拟post行为
4、源码及测试
三、scrapy shell 模拟登陆
1、使用浏览器登陆豆瓣,在fidder中获得cookie
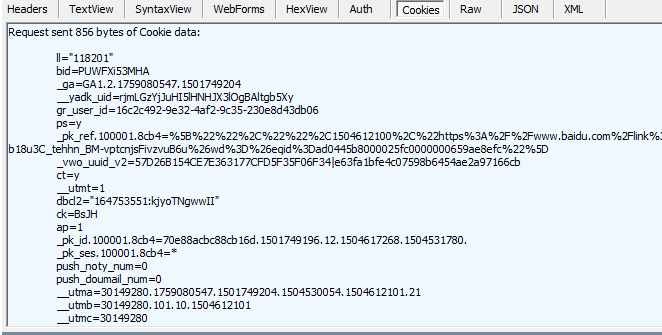
cookie中有许多项(并不是全部需要),经过一条条测试,发现只要包含'dbcl2'就能登录

2、打开scrapy shell 测试登陆
模拟浏览器User-Agent和cookies
$ scrapy shell
...
from scrapy import Request
cookies = {'dbcl2':'"164753551:kjyoTNgwwII"'}
headers={'User-Agent':'Mozilla/5.0'}
req = Request('https://www.douban.com/mine/', headers=headers,cookies = cookies)
fetch(req)
#使用浏览器检查元素得到xpath(方法参考爬虫(一)(二))(日记内容权限未自己可见,若可看见日记内容便模拟登陆成功)
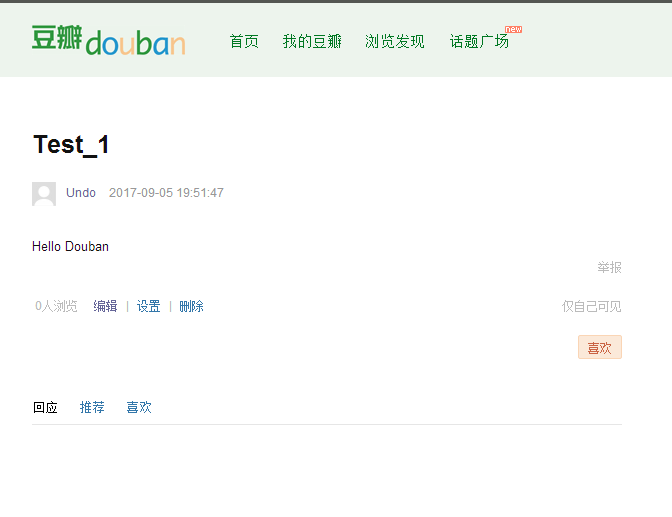
>>> response.xpath('//*[@id="note_636142594_short"]').extract()
['<div class="note" id="note_636142594_short">Hello Douban</div>']
>>> response.xpath('//*[@id="note_636142594_short"]/text()').extract()
['Hello Douban']
>>>
得到日记内容,可见模拟登陆成功,cookie可用
四、python 写豆瓣日记
1、使用浏览器写日记,并在fidder中观察行为
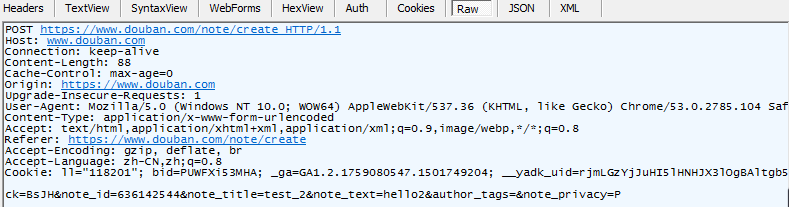
发现浏览器进行了POST https://www.douban.com/note/create HTTP/1.1的行为
post 的内容是ck=BsJH¬e_id=636142544¬e_title=test_2¬e_text=hello2&author_tags=¬e_privacy=P
ck=BsJH 是cookie中的一个值
note_id=636142544(估计是用户id,直接照抄)
note_id=636142544¬e_title=test_2¬e_text=hello2(标题,以及内容)
另外三个参数不重要,使用默认就行
2、使用python模拟post行为
#post 所需要的参数
requests.post(url = url,data = data,headers=headers,verify=False,cookies = cookies)
五、源码及测试
源码
import requests
### 、首先登陆任何页面,获取cookie #使用requests打开https时会产生warming,加上这句屏蔽
requests.packages.urllib3.disable_warnings() headers = dict()
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3387.400 QQBrowser/9.6.11984.400' cookies = dict()
cookies = {#'ll':'"118201"',
#'bid':'PUWFXi53MHA',
#'_ga':'GA1.2.1759080547.1501749204',
#'__yadk_uid':'rjmLGzYjJuHI5lHNHJX3lOgBAltgb5Xy',
#'gr_user_id':'16c2c492-9e32-4af2-9c35-230e8d43db06',
#'ps':'y',
#'_pk_ref.100001.8cb4':'%5B%22%22%2C%22%22%2C1504529257%2C%22https%3A%2F%2Faccounts.douban.com%2Flogin%3Fredir%3Dhttps%253A%252F%252Fwww.baidu.com%252Flink%253Furl%253DEh3nGSbWZ6S0P2OQc7QHrEzCkdwJewBLjFnBpRTRwKv4QwoLScCwKCSh9iQFeDAx%2526wd%253D%2526eqid%253D8191d1c1000627560000000359ad43f4%22%5D',
#'ap':'',
#'_vwo_uuid_v2':'57D26B154CE7E363177CFD5F35F06F34|e63fa1bfe4c07598b6454ae2a97166cb',
'dbcl2':'"164753551:kjyoTNgwwII"'
#'ck':'osar',
#'_pk_id.100001.8cb4':'70e88acbc88cb16d.1501749196.11.1504530290.1504527380.',
#'_pk_ses.100001.8cb4':'*',
#'push_noty_num':'',
#'push_doumail_num':'',
#'__utma':'30149280.1759080547.1501749204.1504529257.1504530054.20',
#'__utmb':'30149280.5.10.1504530054',
#'__utmc':'',
#'__utmz':'30149280.1504530054.20.16.utmcsr',
#'__utmv':'30149280.16475'
} data = {'ck':'BsJH',
'note_id':'',
'note_title':'HelloPython',
'note_text':'HelloPython'
#'author_tags':'',
#'note_privacy':'P'
}
url = 'https://www.douban.com/note/create'
#注意访问https链接时要加上verify=False参数,否则回报错
ret = requests.post(url = url,
data = data,
headers=headers,
verify=False,
cookies = cookies
)
print(ret.text[:])
print(ret.cookies.get_dict())
测试结果

大功告成!
五、总结分析
1、这次使用cookie登陆免去了验证码麻烦,下次希望能研究验证码的破解
2、cookie的使用时间有限,隔一段时间就要更换
3、requests对https的限制挺严格的,需要加入verify=False,并且要屏蔽警告信息
#使用requests打开https时会产生warming,加上这句屏蔽
requests.packages.urllib3.disable_warnings()
附录(一)
vesion 1.5
import requests
from lxml import etree
import time #使用requests打开https时会产生warming,加上这句屏蔽
requests.packages.urllib3.disable_warnings() def get_github_html(url):
'''
这里用于获取登录页的html,以及cookie
:param url: https://github.com/login
:return: 登录页面的HTML,以及第一次的cookei
'''
response = requests.get(url,verify=False)
first_cookie = response.cookies.get_dict()
return response.text,first_cookie def get_token(html,xrule):
'''
处理登录后页面的html
:param html:
:return: 获取csrftoken
'''
selector = etree.HTML(html)
token = selector.xpath(xrule)[0]
#print(token) return token def gihub_login(url,cookie):
'''
这个是用于登录
:param url: https://github.com/session
:param token: csrftoken
:param cookie: 第一次登录时候的cookie
:return: 返回第一次和第二次合并后的cooke
''' data={
"source":"movie",
"redir":"https://movie.douban.com/chart",
"form_email":"***********",
"form_password":"***********",
"login":u'登录',
"remember":"on"
}
response = requests.post(url,data=data,cookies=cookie,verify=False)
print(response.status_code)
print(response.url)
print(response.cookies.get_dict())
cookie2 = response.cookies.get_dict()
#这里注释的解释一下,是因为之前github是通过将两次的cookie进行合并的
#现在不用了可以直接获取就行
cookie.update(cookie2)
print(cookie)
#print(response.text)
return cookie if __name__ == '__main__':
Base_URL = "https://movie.douban.com/?_t_t_t=0.6509884103763016"
Login_URL = "https://www.douban.com/accounts/login"
html,cookie = get_github_html(Base_URL)
print(cookie)
#xrule = '//*[@id="login"]/form/div[1]/input[2]/@value'
#token = get_token(html,xrule)
#print(token)
time.sleep(3)
cookie2 = gihub_login(Login_URL,cookie)
time.sleep(3)
response = requests.get("https://www.douban.com/mine/",verify=False,cookies=cookie2)
print(response.cookies.get_dict())
print(response.url,response.status_code)
#print(response.text)
vesion 1.5
vesion 2.0
from selenium import webdriver Base_URL = "https://movie.douban.com/?_t_t_t=0.6509884103763016"
Login_URL = "https://www.douban.com/accounts/login" browser = webdriver.Firefox()
browser.get('https://movie.douban.com/')
cookies = browser.get_cookies()
#print(cookies) #打开网址
browser.get('https://www.douban.com/accounts/login')
#browser.maximize_window()#窗口最大化,可有可无,看情况 #输入账户密码
#我请求的页面的账户输入框的'id'是username和密码输入框的'id'是password
browser.find_element_by_id('email').clear()
browser.find_element_by_id('email').send_keys(u'***********')
browser.find_element_by_id('password').clear()
browser.find_element_by_id('password').send_keys(u'***********') #remember me
browser.find_element_by_id('remember').click() #输入完用户密码当然就是提交了,通过'name'为login来找到提交按钮
browser.find_element_by_name('login').click() #print(browser.current_url) if browser.current_url =='https://www.douban.com/accounts/login':
#输入账户密码
#我请求的页面的账户输入框的'id'是username和密码输入框的'id'是password
browser.find_element_by_id('email').clear()
browser.find_element_by_id('email').send_keys(u'***********')
browser.find_element_by_id('password').clear()
browser.find_element_by_id('password').send_keys(u'***********')
captcha_field = input("请输入验证码:")
captcha_field = str(captcha_field)
browser.find_element_by_id('captcha_field').clear()
browser.find_element_by_id('captcha_field').send_keys(captcha_field)
#remember me
browser.find_element_by_id('remember').click()
#输入完用户密码当然就是提交了,通过'name'为login来找到提交按钮
browser.find_element_by_name('login').click() browser.get("https://www.douban.com/mine/") cookies2 = browser.get_cookies()
print(browser.current_url)
print(cookies2) #浏览器退出
browser.quit()
vesion 2.0
Python爬虫个人记录(四)利用Python在豆瓣上写一篇日记的更多相关文章
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- 孤荷凌寒自学python第三十四天python的文件操作对file类的对象学习
孤荷凌寒自学python第三十四天python的文件操作对file类的对象学习 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 一.close() 当一个file对象执行此方法时,将关闭当前 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python学习系列(四)Python 入门语法规则2
Python学习系列(四)Python 入门语法规则2 2017-4-3 09:18:04 编码和解码 Unicode.gbk,utf8之间的关系 2.对于py2.7, 如果utf8>gbk, ...
- Python 爬虫个人记录(一)豆瓣电影250
一.爬虫环境 Python3.6 scrapy1.4 火狐浏览器 qq浏览器 二.scrapy shell 测试并获取 xpath 1.进入scrapy shell 2 .获取html fetch(' ...
- python爬虫学习过程记录
项目为爬取Python词条的信息. 项目代码在我的码云仓库. https://gitee.com/libo-sober/learn-python/tree/master/baike_spider 1. ...
随机推荐
- presto架构和原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- IFrame跨域处理方法-Javascript
在漫长的前端开发旅途上,无可避免的会接触到ajax,而且一般情况下都是用在同一域下的ajax请求:但是如果请求是发生在不同的域下,请求就无法执行,并且会抛出异常提示不允许跨域请求,目前我没有找到明确的 ...
- iframe中的历史记录问题汇总及解决方案[转]
在做页面统计的时候遇到了两个问题: 1.包含iframe的页面,在IE下按后退按钮不能刷新主页面.隐藏Iframe的src是统计程序的url,每点一次后退,就会发出一次页面加载时间请求. 2.由js动 ...
- LintCode 204: Singleton
LintCode 204: Singleton 题目描述 单例是最为最常见的设计模式之一.对于任何时刻,如果某个类只存在且最多存在一个具体的实例,那么我们称这种设计模式为单例.例如,对于class M ...
- java学习第02天(语言基础组成:关键字、标识符、注释、常量和变量)
Java语言基础组成 1. 关键字 就是指的一些单词,这些单词被赋予了特殊的java含义,就不再叫单词了. 例如: class Demo{ public static void main(String ...
- HDU 2097 Sky数 进制转换
解题报告:这题就用一个进制转换的函数就可以了,不需要转换成相应的进制数,只要求出相应进制的数的各位的和就可以了. #include<cstdio> #include<string&g ...
- [转]Laplace算子和Laplacian矩阵
1 Laplace算子的物理意义 Laplace算子的定义为梯度的散度. 在Cartesian坐标系下也可表示为: 或者,它是Hessian矩阵的迹: 以热传导方程为例,因为热流与温度的梯度成正比,那 ...
- 查看linux系统的信息
#!/bin/sh ################################################## #function:get host's information #Autho ...
- scp加端口号
scp -P 21110 root@192.168.0.1:/home/abc.txt root@192.168.0.2:/root 注意: 参数-P 的位置一定要紧跟在scp命令后面 参数-P 指的 ...
- maven package exec 及 maven 配置文件详解
maven package test包下执行test 的配置文件 生成target目录,编译.测试代码,生成测试报告,生成jar/war文件 maven 配置文件详解 http://blog.csdn ...