sqoop 数据导入hive
一. sqoop: mysql->hive
sqoop import -m 1 --hive-import --connect "jdbc:mysql://127.0.0.1:3306/TEST?zeroDateTimeBehavior=CONVERT_TO_NULL&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai" --username sa --password-file /user/root/_sqoop/pwd127.txt --table user --hive-database TEST --hive-table user
这里jdbc url后面跟了一些连接参数,看情况可有可无;
二.sqoop: oracle->hive
# 使用oracle 服务名jdbc url
sqoop import --connect jdbc:oracle:thin:@//127.0.0.1:1521/ORCL --username sa --password 123456 --table TEST.user--hive-import --hive-database test --hive-table user -m 1
# 使用oracle SID jdbs url
sqoop import --connect jdbc:oracle:thin:@127.0.0.1:1521:ORCL --username sa --password 123456 --table TEST.user --hive-import --hive-database test --hive-table user -m 1
三.建立增量任务
1.启动sqoop metastore服务存储job
sqoop metastore
2.创建增量任务
sqoop job [metastore] --create <job_name> -- <import_task> --incremental append --check-column id --last-value <last_id> sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --create sync_test -- \
import -m 1 --hive-import --connect "jdbc:mysql://192.168.1.196:3306/TEST" --username sa --password-file /user/root/_sqoop/pwd127.txt --table user --hive-database TEST --hive-table user \
--incremental append --check-column id --last-value 0
TIPS: 不指定metastore时默认使用本地的hsql,分布式的时候不可用;
--check-cloumn 须要是 not null ,有序字段
--last-value 如果是第一次导入可以是 0,(一开始就使用增量导入)
3.运行任务
sqoop job [metastore] --exec <job_name>
sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --exec sync_test
sqoop job [metastore] --list 可以查看任务列表
四,HUE 任务
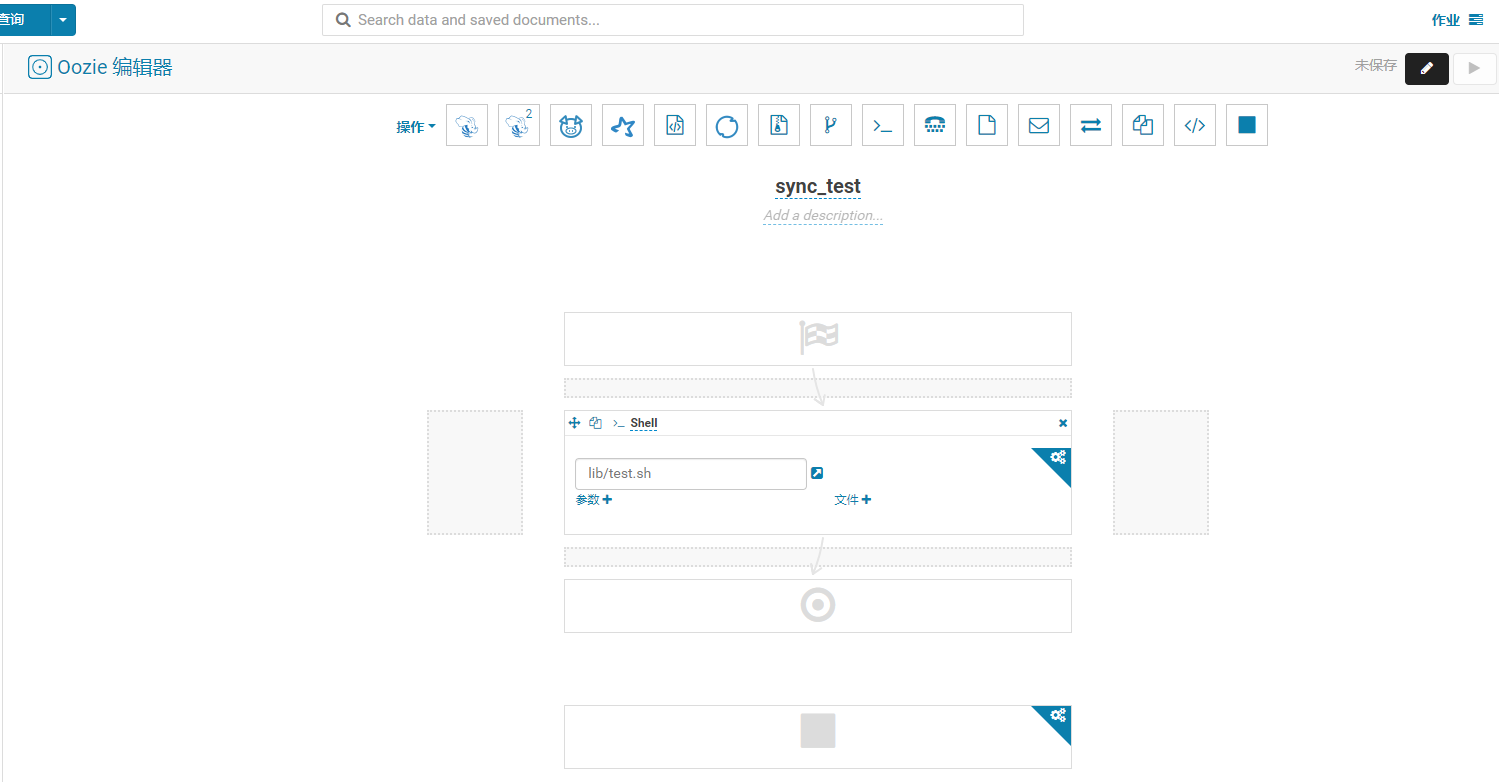
1.建立workflow;
2.在workspace 空间中建立sh文件
3.在sh中写入增量任务命令::sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --exec sync_test
4.再编辑workflow 添加shell组件,选择workspace中的sh文件, 测试
5.建立schedule,将workflow添加进来,编辑运行规则;
更多细节可参考:
https://www.cnblogs.com/canyangfeixue/p/4731520.html
.http://archive.cloudera.com/cdh/3/sqoop/SqoopUserGuide.html
sqoop 数据导入hive的更多相关文章
- 使用sqoop把mysql数据导入hive
使用sqoop把mysql数据导入hive export HADOOP_COMMON_HOME=/hadoop export HADOOP_MAPRED_HOME=/hadoop cp /hive ...
- sqoop数据导入到Hdfs 或者hive
用java代码调用shell脚本执行sqoop将hive表中数据导出到mysql http://www.cnblogs.com/xuyou551/p/7999773.html 用sqoop将mysql ...
- 将数据导入hive,将数据从hive导出
一:将数据导入hive(六种方式) 1.从本地导入 load data local inpath 'file_path' into table tbname; 用于一般的场景. 2.从hdfs上导入数 ...
- 042 将数据导入hive,将数据从hive导出
一:将数据导入hive(六种方式) 1.从本地导入 load data local inpath 'file_path' into table tbname; 用于一般的场景. 2.从hdfs上导入数 ...
- python脚本 用sqoop把mysql数据导入hive
转:https://blog.csdn.net/wulantian/article/details/53064123 用python把mysql数据库的数据导入到hive中,该过程主要是通过pytho ...
- sqoop mysql导入hive 数值类型变成null的问题分析
问题描述:mysql通过sqoop导入到hive表中,发现有个别数据类型为int或tinyint的列导入后数据为null.设置各种行分隔符,列分隔符都没有效果. 问题分析:hive中单独将有问题的那几 ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
安装hive 1.下载hive-2.1.1(搭配hadoop版本为2.7.3) 2.解压到文件夹下 /wdcloud/app/hive-2.1.1 3.配置环境变量 4.在mysql上创建元数据库hi ...
- sqoop数据导入命令 (sql---hdfs)
mysql------->hdfs sqoop导入数据工作流程: sqoop提交任务到hadoop------>hadoop启动mapreduce------->mapreduce通 ...
- Sqoop 数据导入导出实践
Sqoop是一个用来将hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:mysql,oracle,等)中的数据导入到hadoop的HDFS中,也可以将HDFS的数据导入到 ...
随机推荐
- grep正则表达式(二)
任意字符(The Any Character) dot or period character: "." grep -h '.zip' dirlist*.txt ".&q ...
- 【leetcode】1007. Minimum Domino Rotations For Equal Row
题目如下: In a row of dominoes, A[i] and B[i] represent the top and bottom halves of the i-th domino. ( ...
- Voting与OCR
VotingVoting Disk里面记录着节点成员的信息.如RAC数据库中有哪些节点成员,节点增加或者删除时也同样会将信息记录进来.Voting Disk必须存放在共享存储上.crsctl quer ...
- 解决如何通过循环来使用数据库的值设置jsp的select标签的option值
Select 处的代码: <select name="position"> <span style="white-space:pre"> ...
- Junit单元测试之MockMvc
在测试restful风格的接口时,springmvc为我们提供了MockMVC架构,使用起来也很方便. 下面写个笔记,便于以后使用时参考备用. 一 场景 1 . 提供一个restful风格的接口 im ...
- ldd3 编写scull尝试
快速参考: #include <linux/types.h> dev_t dev_t is the type used to represent device numbers within ...
- codeforces798C - Mike and gcd problem (数论+思维)
原题链接:http://codeforces.com/contest/798/problem/C 题意:有一个数列A,gcd(a1,a2,a3...,an)>1 时称这个数列是“漂亮”的.存在这 ...
- HDU 6040 Hints of sd0061 —— 2017 Multi-University Training 1
Hints of sd0061 Time Limit: 5000/2500 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- java 节点流(字符流,字节流)和包装流(缓冲流,转换流)
结点流:直接对File类进行操作的文件流 package stream; import java.io.File; import java.io.FileNotFoundException; impo ...
- 用 Flask 来写个轻博客 (33) — 使用 Flask-RESTful 来构建 RESTful API 之二
Blog 项目源码:https://github.com/JmilkFan/JmilkFan-s-Blog 目录 目录 前文列表 扩展阅读 构建 RESTful Flask API 定义资源路由 格式 ...