Ajax爬取豆瓣电影目录(Python)
下面的分析相当于一个框架,搞懂之后,对于类似的文字爬取,我们也可以实现。就算不能使用Ajax方法,我们也能够使用相同思想去爬取我们想要的数据。
豆瓣电影排行榜分析
首先我们打开网页的审查元素,选中Network==》XHR==》电影相关信息网页文件
筛选并比较以下数据(三个文件数据)
请求地址
Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=40
查询参数
type:movie
tag:热门
sort:recommend
page_limit:
page_start: type:movie
tag:热门
sort:recommend
page_limit:
page_start: type:movie
tag:热门
sort:recommend
page_limit:
page_start:
请求报头
Host:movie.douban.com
Referer:https://movie.douban.com/explore
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
X-Requested-With:XMLHttpRequest
通过比较请求地址和查询参数,得出
请求地址 = baseurl+type+tag+sort+page_limit+page_start baseurl:https://movie.douban.com/j/search_subjects?
type:固定为movie
tag:关键字,需要将utf-8转换为urlencode
sort:固定为recommend
page_limit:表示一页显示的电影数量,固定20
page_start:表示电影页数,从0开始,20为公差的递增函数
由此我们获取到了我们需要的数据,可以将爬虫分为三步
- 获取网页json格式代码
- 从代码中获取电影名和电影海报图片链接
- 将获得的图片命名为电影名
流程
准备工作
在函数外部定义伪装的请求报头
headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/explore',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
获取json格式代码
def get_page(page):
#请求参数
params={
'type': 'movie',
'tag': '奥特曼',
'sort': 'recommend',
'page_limit': '',
'page_start': page,
}
#基本网页链接
base_url = 'https://movie.douban.com/j/search_subjects?'
#将基本网页链接与请求参数结合在一起
url = base_url + urlencode(params)
try:
#获取网页代码
resp = requests.get(url, headers=headers)
print(url)
#返回json数据格式代码
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None
筛选数据
通过观察电影列表代码文件的preview,进行数据筛选
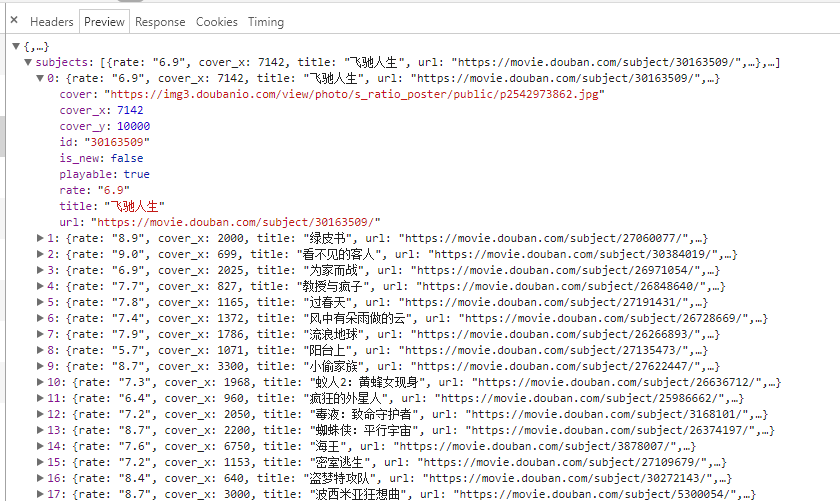
def get_image(json):
if(json.get('subjects')):
data=json.get('subjects')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
#返回"信息"字典
yield {
'title':title,
'images':imageurl,
}
存储图片文件
def save_page(item):
#文件夹名称
file_name = '奥特曼电影大全'
if not os.path.exists(file_name):
os.makedirs(file_name) #获取图片链接
response=requests.get(item.get('images'))
#储存图片文件
if response.status_code==200:
file_path = file_name + os.path.sep + item.get('title') + '.jpg'
with open(file_path, 'wb') as f:
f.write(response.content)
多线程处理
def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()

总代码
import requests
from urllib.parse import urlencode
import os
from multiprocessing.pool import Pool headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/explore',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
} def get_page(page):
#请求参数
params={
'type': 'movie',
'tag': '奥特曼',
'sort': 'recommend',
'page_limit': '',
'page_start': page,
}
#基本网页链接
base_url = 'https://movie.douban.com/j/search_subjects?'
#将基本网页链接与请求参数结合在一起
url = base_url + urlencode(params)
try:
#获取网页代码
resp = requests.get(url, headers=headers)
print(url)
#返回json数据格式代码
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None def get_image(json):
if(json.get('subjects')):
data=json.get('subjects')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
#返回"信息"字典
yield {
'title':title,
'images':imageurl,
} def save_page(item):
#文件夹名称
file_name = '奥特曼电影大全'
if not os.path.exists(file_name):
os.makedirs(file_name) #获取图片链接
response=requests.get(item.get('images'))
#储存图片文件
if response.status_code==200:
file_path = file_name + os.path.sep + item.get('title') + '.jpg'
with open(file_path, 'wb') as f:
f.write(response.content) def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()
本来是准备使用https://movie.douban.com/tag/#/ 不过在后面,刷新网页时,总是出现服务器问题。不过下面的代码还是可以用。
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
from multiprocessing.pool import Pool headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/tag/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
} def get_page(page):
params={
'sort':'U',
'range':'0,10',
'tags':'奥特曼',
'start': page,
}
base_url = 'https://movie.douban.com/j/new_search_subjects?'
url = base_url + urlencode(params)
try:
resp = requests.get(url, headers=headers)
print(url)
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None def get_image(json):
if(json.get('data')):
data=json.get('data')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
yield {
'title':title,
'images':imageurl,
} def save_page(item):
file_name='奥特曼大全'+os.path.sep+item.get('title')
if not os.path.exists(file_name):
os.makedirs(file_name)
try:
response=requests.get(item.get('images'))
if response.status_code==200:
file_path = '{0}/{1}.{2}'.format(file_name, md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image') def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()
Ajax爬取豆瓣电影目录(Python)的更多相关文章
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
随机推荐
- css图像拼合技术(精灵图)
CSS图像拼合技术 1.图像拼合 图像拼合技术就是单个图像的集合. 有很多图片的网页可能会需要很多时间来加载和生成多个服务器的请求. 使用图像拼合会降低服务器的请求数量,并节省带宽. 图像拼合实例 有 ...
- 怎么在tensorflow中打印graph中的tensor信息
from tensorflow.python import pywrap_tensorflow import os checkpoint_path=os.path.join('./model.ckpt ...
- 饿了么CTO张雪峰:允许90后的技术人员“浮躁“一点
编者按:今年4月,饿了么正式加入了阿里新零售战队,进一步加速其在本地生活市场的扩张速度.在创业9年的时间中,饿了么在外卖领域经历了真正的“从0到1”,尤其是在外卖平台的技术升级方面,越过了一个又一个的 ...
- Nginx的启动、停止与重启---linux
一.选定安装文件目录 可以选择任何目录 cd /usr/local/src 二.安装PCRE库 ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcr ...
- h5分线程Worker
<!DOCTYPE html><html><head> <meta charset="UTF-8"> <title>Ti ...
- day29—JavaScript中DOM的基础知识应用
转行学开发,代码100天——2018-04-14 JavaScript中DOM操作基础知识即对DOM元素进行增删改操作.主要表现与HTML元素的操作,以及对CSS样式的操作.其主要应用知识如下图: 通 ...
- html基础与表格的理解·
1.静态网页与动态网页的区别:是否访问数据库 2.超文本:超文本是指超出文本的范围,可以插入声音视频,表格图片等 3.标记语言与网页结构:标记语言就是标签,网页结构包含<html>< ...
- XML scriptlet 连接数据库
<%@ page language="java" contentType="text/html" pageEncoding="GBK" ...
- Vue动态添加响应式属性
不能给Vue实例.Vue实例的根数据对象添加属性. 文件 <template> <div id="app"> <h2>{{hello}}:{{a ...
- postman测试wsdl类型接口
1 IP地址来源搜索 WEB 服务 接口信息 http://www.webxml.com.cn/WebServices/WeatherWebService.asmx?wsdl 2 设置接口调用地址 ...