Scapy——Scrapy shell的使用
在开发爬虫的使用,scrapy shell可以帮助我们定位需要爬取的资源
启动Scrapy Shell
在终端中输入以下内容即可启动scrapy shell,其中url是要爬取的页面,可以不设置
scrapy shell <url>
scrapy shell还支持本地文件,如果想用爬取本地的web页面副本,可以用以下方式。使用文件相对路径时,确保使用 “./” 或者 “../” 或者 “file://” ,直接scarpy shell index.html的方式会报错
# UNIX-style
scrapy shell ./path/to/file.html
scrapy shell ../other/path/to/file.html
scrapy shell /absolute/path/to/file.html # File URI
scrapy shell file:///absolute/path/to/file.html
Shell使用方法
可用的方法
shelp(): 打印可用的对象和方法fetch(url[, redirect=True]): 爬取新的 URL 并更新所有相关对象fetch(request): 通过给定request 爬取,并更新所有相关对象view(response): 使用本地浏览器打开给定的响应。这会在计算机中创建一个临时文件,这个文件并不会自动删除
可用的Scrapy对象
Scrapy shell自动从下载的页面创建一些对象,如 Response 对象和 Selector 对象。这些对象分别是
crawler: 当前Crawler 对象spider: 爬取使用的 Spider,如果没有则为Spider对象request: 最后一个获取页面的Request对象,可以使用 replace() 修改请求或者用 fetch() 提取新请求response: 最后一个获取页面的Response对象settings: 当前的Scrapy设置
简单示例
fetch('https://scrapy.org')
response.xpath('//title/text()').get()
# 输出
# 'Scrapy | A Fast and Powerful Scraping and Web Crawling Framework'
from pprint import pprint
pprint(response.headers)

在Spider内部调用Scrapy shell来检查响应
有时你想检查Spider某个特定点正在处理的响应,只是为了检查你期望的响应是否到达那里。
可以通过使用该scrapy.shell.inspect_response功能来实现。
import scrapy class MySpider(scrapy.Spider):
name = "myspider"
start_urls = [
"http://example.com",
"http://example.org",
"http://example.net",
] def parse(self, response):
# We want to inspect one specific response.
if ".org" in response.url:
from scrapy.shell import inspect_response
inspect_response(response, self) # Rest of parsing code.
启动爬虫后我们就开始检查工作,注意这里不能使用fectch(),因为Scrapy引擎被shell阻塞了
response.xpath('//h1[@class="fn"]')
最后,按Ctrl-D(或Windows中的Ctrl-Z)退出shell并继续爬行。
实例
爬取Scrapy官方文档
fetch("https://docs.scrapy.org/en/latest/index.html")
根据页面标签,可以知道,根据标题等级,标题在h1、h2标签中
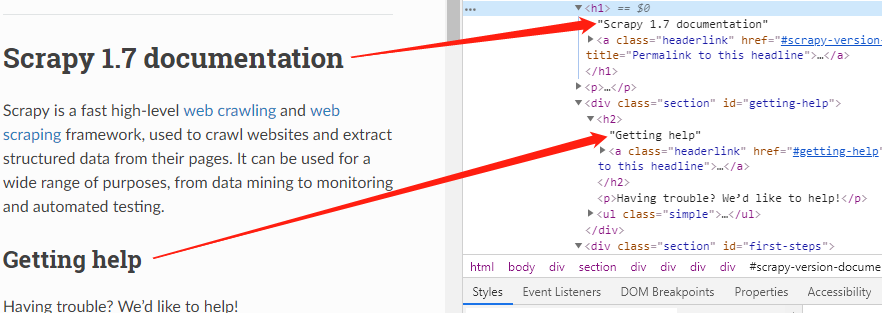
以爬取标题二为例,我们可以用xpath定位这些元素
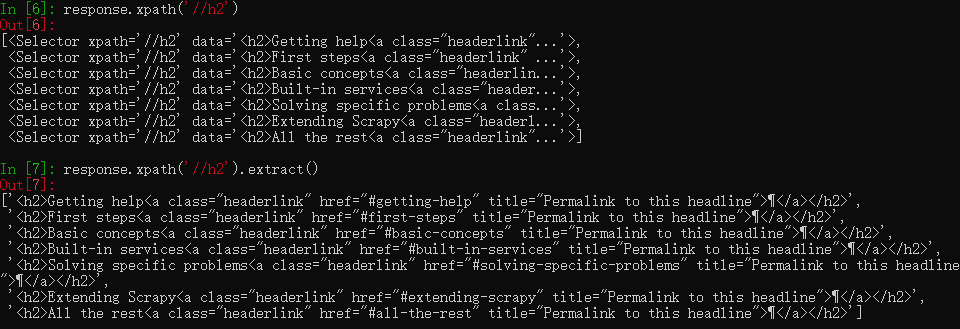
response.xpath('//h2')
此时仍然是一个xpath对象,需要用extract()提取出来
response.xpath('//h2').extract()
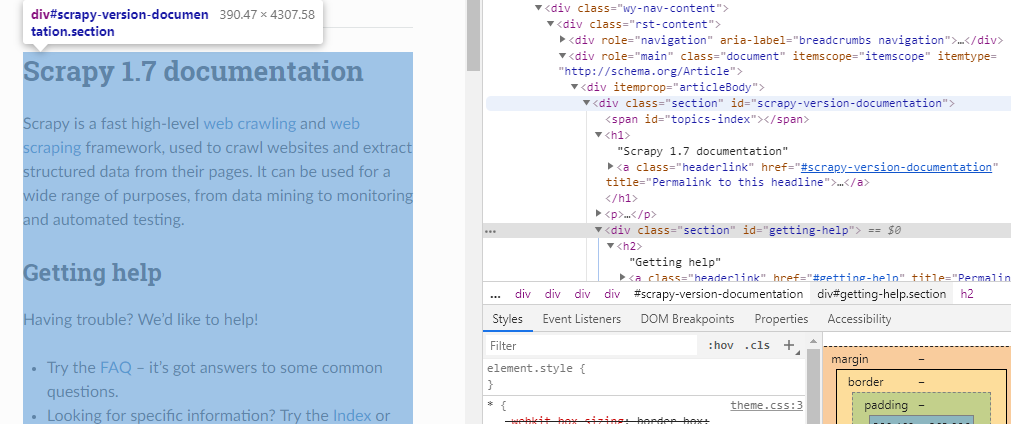
文档主体都在div标签中,class名称为“section”,如果想爬取文档内容,可以这样
response.xpath("//div[@class='section']").extract()
然后再用正则表达式提取我们需要的内容
import re
data = response.xpath("//div[@class='section']").extract() # 一个列表
pattern = re.compile("(?<=<h2>).*(?=<a)") # 响应中可以看到结果为:<h2>二级标题<a class=……,用正则匹配出中间的标题
title = re.findall(pattern, data[])
print(title)

Scapy——Scrapy shell的使用的更多相关文章
- Scrapy shell调试网页的信息
通过scrapy shell "http://www.thinkive.cn:10000/zentaopms/www/index.php?m=user&f=login"
- scrapy shell 中文网站输出报错.记录.
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 381-382: illegal multibyte sequence 上 ...
- 安装ipython,使用scrapy shell来验证xpath选择的结果 | How to install iPython and how does it work with Scrapy Shell
1. scrapy shell 是scrapy包的一个很好的交互性工具,目前我使用它主要用于验证xpath选择的结果.安装好了scrapy之后,就能够直接在cmd上操作scrapy shell了. 具 ...
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- Scrapy Shell的使用
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- 14.Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- scrapy shell的作用
1.可以方便我们做一些数据提取的测试代码: 2.如果想要执行scrapy命令,那么毫无疑问,肯定是要先进入到scrapy所在的环境中: 3.如果想要读取某个项目的配置信息,那么应该先进入到这个项目中. ...
- Scrapy shell调试返回403错误
一.问题描述 有时候用scrapy shell来调试很方便,但是有些网站有防爬虫机制,所以使用scrapy shell会返回403,比如下面 C:\Users\fendo>scrapy shel ...
- scrapy shell
一.scrapy shell 1.安装pip install Jupyter 2.在pycharm中的启动命令: scrapy shell 注:启动后关键字高亮显示 3.查看response 执行sc ...
随机推荐
- shuoj 1 + 2 = 3? (二分+数位dp)
题目传送门 1 + 2 = 3? 发布时间: 2018年4月15日 22:46 最后更新: 2018年4月15日 23:25 时间限制: 1000ms 内存限制: 128M 描述 埃森哲是 ...
- P3515 [POI2011]Lightning Conductor(决策单调性分治)
P3515 [POI2011]Lightning Conductor 式子可转化为:$p>=a_j-a_i+sqrt(i-j) (j<i)$ $j>i$的情况,把上式翻转即可得到 下 ...
- idea 创建 SSM + maven Java Web 项目流程
idea 创建 SSM + maven Java Web 项目流程 一.idea 中选择File,New Project 新建项目 二.选择Maven,勾选上面的Create from archety ...
- ssh-add - 向认证代理添加 RSA 或 DSA 身份数据
总览 (SYNOPSIS) ssh-add [-lLdDx ] [-t life ] [file ... ] ssh-add -s reader ssh-add -e reader 描述 (DESCR ...
- 让centos使用ubuntu的make命令补全功能
一直习惯使用debian.ubuntu做开发机,最近it要求各种安全加固,且只提供centos自动化脚本,而ubuntu版本比较乱,14.16.17都要自己整一遍太麻烦,索性换装centos7. 换了 ...
- Dev控件
在DevExpress程序中使用PopupContainerEdit和PopupContainer实现数据展示 使用PopupContainerEdit和PopupContainerControl制作 ...
- 2、pycharm中设置pytest为默认运行
1.打开File-setting 2.打开Tools-Python Integrated Tools 3.找到Default test runner选项,在下拉框中选择py.test 4.点Apply ...
- 2.Javascript 函数(主要)
定义函数 在JavaScript中,定义函数的方式如下: function abs(x) { if (x >= 0) { return x; } else { return -x; } } 上述 ...
- gensim Load embeddings
gensim package from gensim.models.keyedvectors import KeyedVectors twitter_embedding_path = 'twitter ...
- boost range
1.Algorithms Boost.Range is library that, on the first sight, provides algorithms similar to those p ...