scrapy shell
一、scrapy shell
1、安装pip install Jupyter

2、在pycharm中的启动命令: scrapy shell
注:启动后关键字高亮显示
3、查看response
执行scrapy shell http://www.521609.com,查看response
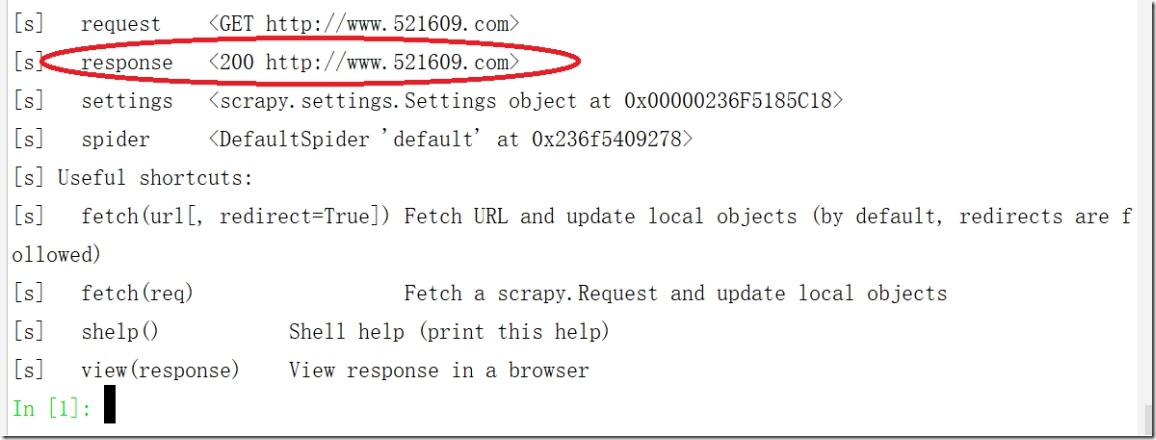
二、Scrapyshell 使用细节
注:调用:scrapy shell https://www.xxx.com/
1、Scrapyshell 终端是一个交互终端
我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据;
2、Jupyter
如果安装了 Jupyter ,Scrapy终端将使用 Jupyter (替代标准Python终端)。 Jupyter 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。推荐安装Jupyter;
3、response
当shell载入后,将得到一个包含response数据的本地 response 变量,输入 response.body将输出response的包体,输出 response.headers 可以看到response的响应头;
4、response.selector
输入 response.selector 时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用 response.selector.xpath()或response.selector.css() 来对 response 进行查询;
5、执行命令
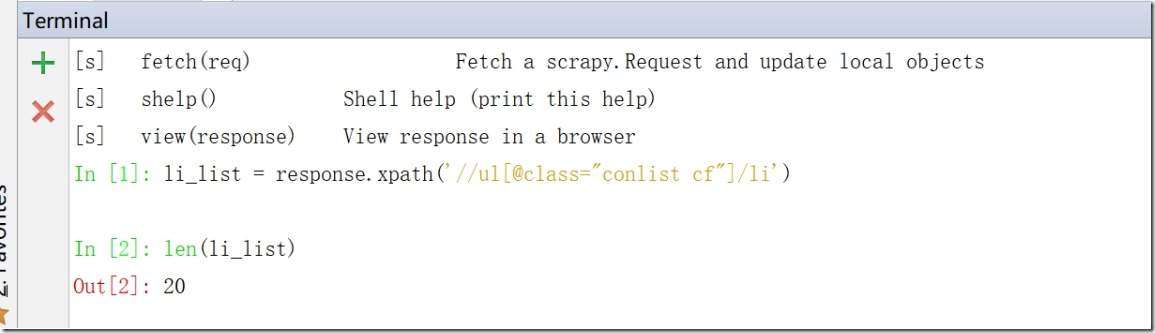
1)scrapy shell http://www.ichong123.com/pics/
2)执行:li_list = response.xpath('//ul[@class="conlist cf"]/li')
3)执行:len(li_list) 证明有数据
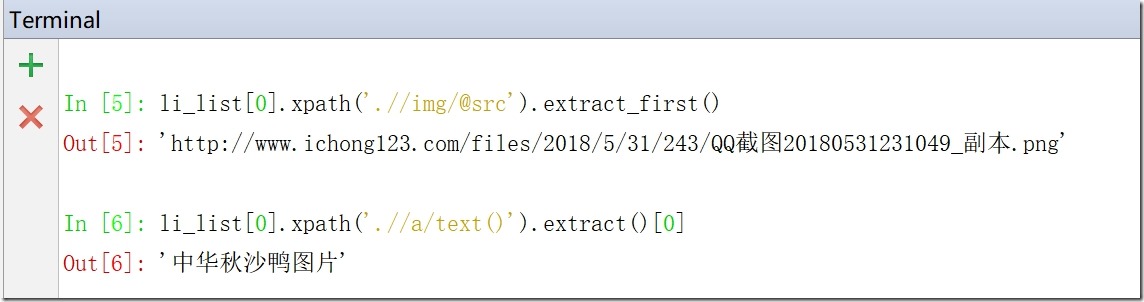
4)执行:li_list[0].xpath('.//img/@src').extract_first()得到图片
5)执行:li_list[0].xpath('.//a/text()').extract()[0]得到图片名字
以上是Scrapyshell 的基本使用,谢谢关注!!!
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。


scrapy shell的更多相关文章
- Scrapy shell调试网页的信息
通过scrapy shell "http://www.thinkive.cn:10000/zentaopms/www/index.php?m=user&f=login"
- scrapy shell 中文网站输出报错.记录.
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 381-382: illegal multibyte sequence 上 ...
- 安装ipython,使用scrapy shell来验证xpath选择的结果 | How to install iPython and how does it work with Scrapy Shell
1. scrapy shell 是scrapy包的一个很好的交互性工具,目前我使用它主要用于验证xpath选择的结果.安装好了scrapy之后,就能够直接在cmd上操作scrapy shell了. 具 ...
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- Scrapy Shell的使用
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- 14.Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- scrapy shell的作用
1.可以方便我们做一些数据提取的测试代码: 2.如果想要执行scrapy命令,那么毫无疑问,肯定是要先进入到scrapy所在的环境中: 3.如果想要读取某个项目的配置信息,那么应该先进入到这个项目中. ...
- Scrapy shell调试返回403错误
一.问题描述 有时候用scrapy shell来调试很方便,但是有些网站有防爬虫机制,所以使用scrapy shell会返回403,比如下面 C:\Users\fendo>scrapy shel ...
- 在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0, 时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步. 本文展示使用在 Scrapy项目内.项目外scrap ...
随机推荐
- drupal7创建自定义的panels布局
很简单,在主题的 *.info文件中添加一句代码: 这一句很简单,但也很重要,没有这一句,就没在panels的配置界面去显示自定义的布局 plugins[panels][layouts] = layo ...
- Java内部类的介绍
在Java的面向对象编程中,由于Java并没有类似C++的多重继承,所以采用了内部类这样的方式,现在介绍几种内部类的常见情况. 公开内部类 即由public关键词修饰的内部类,内部类作为外部类的一个成 ...
- Html5+离线打包创建本地消息
自己离线打包Html5+ Runtime,通常是导入SDK的Hello实例,然后修改.在做消息通知功能时,使用push.createMessage不起作用. 首先参考Android平台离线打包推送插件 ...
- LeetCode题解之Pascal's Triangle II
1.题目描述 2.题目分析 题目要求返回杨辉三角的某一行,需要将杨辉三角的某行的全部计算出来. 3.代码实现 vector<int> getRow(int rowIndex) { ) ,) ...
- 在Eclipse中运行Jboss时出现java.lang.OutOfMemoryError:PermGen space及其解决方法
在Eclipse中运行Jboss时出现java.lang.OutOfMemoryError:PermGen space及其解决方法 在Eclipse中运行Jboss时,时间太长可能有时候会出现java ...
- 从外部导入django模块
import os import sys sys.path.append("D:\\pyweb\\sf"); # 项目位置(不是app) os.environ.setdefault ...
- python基础学习16----模块
模块(Module)的引入 import 模块名 调用模块中的函数的方式为 模块名.函数名 这种方式引入会相当于将模块中代码执行一遍,所以如果引入的模块中有输出语句,那么只写import 模块名,运行 ...
- zabbix待完整
fad 下载zabbix3.4的配置文件 wget -O zabbix-3.4.2.tar.gz http://sourceforge.net/projects/zabbix/files/ZABBIX ...
- [转]Redis学习---Redis高可用技术解决方案总结
[原文]https://www.toutiao.com/i6591646189714670093/ 本文主要针对Redis常见的几种使用方式及其优缺点展开分析. 一.常见使用方式 Redis的几种常见 ...
- Mysql 5.7源码编译启动 报error问题:The server quit without updating PID file (/data/data_mysql/mysql.pid).
一般是报error问题就是我们的mysql没有权限,这里主要是指三点:一个是mysql的安装主目录要设为mysql用户和用户组.一个是logs目录设置为mysql用户以及用户组.还有一个是data目录 ...