【机器学习速成宝典】模型篇06决策树【ID3、C4.5、CART】(Python版)
目录
什么是决策树(Decision Tree)
特征选择
使用ID3算法生成决策树
使用C4.5算法生成决策树
使用CART算法生成决策树
预剪枝和后剪枝
应用:遇到连续与缺失值怎么办?
多变量决策树
Python代码(sklearn库)
|
什么是决策树(Decision Tree) |
引例
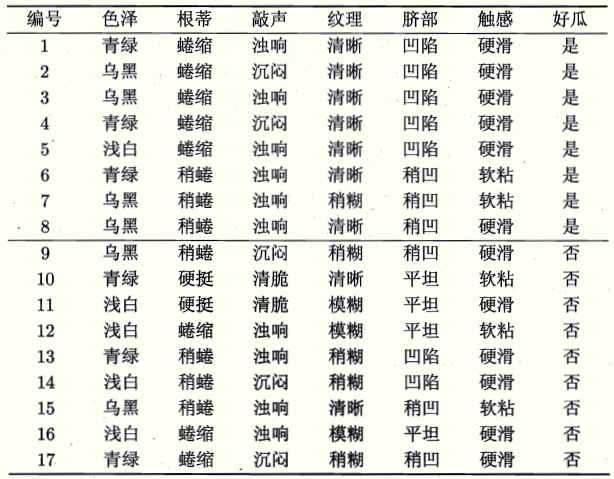
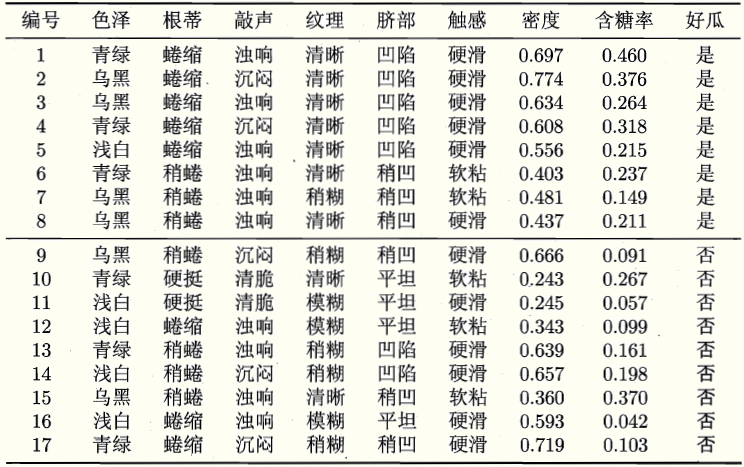
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
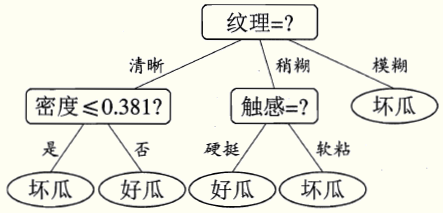
先不谈建立决策树模型的算法,我们先看一下基于“信息增益”(后面讲)生成的决策树的样子

一棵决策树包含一个根节点、若干个内部节点、若干个叶节点。叶节点对应于决策结果,其他节点对应于一个属性测试。每个节点包含的样本集合根据属性测试的结果被划分到子节点中。根节点(纹理)包含样本全集,根节点下的节点(根蒂)包含所有纹理=清晰的样本。从根节点到每个叶节点的路径对应一个判定测试序列。决策树的学习就是要产生一棵对新样本预测正确率高的决策树。
李航《统计学习方法》中的介绍
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。这些决策树学习的思想主要来源于由Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法,以及由Breiman等人在1984年提出的CART算法。
|
特征选择 |
决策树学习的关键在于:在每个节点上如何选择最优划分属性。
在引例中,在根节点上,优先选择了“纹理”作为划分属性,这种选择是有依据的。
一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的“纯度”越来越高。因此我们要找一个指标,去衡量划分数据集后“纯度提升的幅度”,然后选择能让“纯度提升的幅度”最大的特征去划分数据集。
常用的衡量“纯度提升的幅度”的指标有:信息增益、信息增益率、基尼指数。
基于信息增益生成决策树的算法,称为ID3算法。
基于信息增益率生成决策树的算法,称为C4.5算法。
基于基尼指数生成决策树的算法,称为CART算法。
二娃:为什么要在每个节点上都要费老大劲去选择最优划分属性呢?先看看我们有哪些特征(色泽、根蒂...触感),按顺序选呗?
假设有一个训练集,有4个特征A、B、C、D;标记={0,1}。我们发现:无论ABC取什么,标记都和D的取值一样,也就是说,D是最主要的因素。如果用D作为划分特征的话,我们的决策树将会十分精致(模型即简单又准确);如果没选D,那么遗憾了,模型可能会变得复杂(有过拟合的风险),还会额外增加计算量。
|
使用ID3算法生成决策树 |
ID3算法是基于信息增益生成决策树的算法。
首先定义“信息熵”,它是度量样本集合纯度的一种指标。假定当前样本集合D中第k类(k=1,2,...,|Y|)样本所占的比例为pk,则D的信息熵定义为
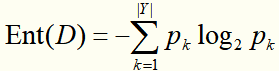
假设离散属性a有V个可能的取值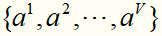 ,若用a来对样本集D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为av的样本,记为Dv。计算出Dv的信息熵,再考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重
,若用a来对样本集D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为av的样本,记为Dv。计算出Dv的信息熵,再考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重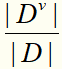 ,即样本数越多的分支节点影响越大,于是可计算出用属性a对样本集D进行划分所获得的“信息增益”:
,即样本数越多的分支节点影响越大,于是可计算出用属性a对样本集D进行划分所获得的“信息增益”:
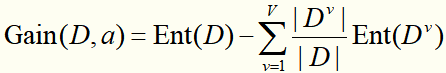
信息增益越大,则意味着用属性a来进行划分所获得的“纯度提升的幅度”越大。以根节点为例,对属性集A中的所有属性(色泽、根蒂...触感),分别计算信息增益,取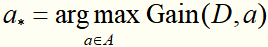 来划分根节点数据集。
来划分根节点数据集。
下面,演示引例中决策树形成的过程:
第一步:
显然,|Y|=2。在决策树开始学习是,根节点包含D中所有样例,其中正例占p1=8/17,反例占p2=9/17。于是根节点的信息熵为:
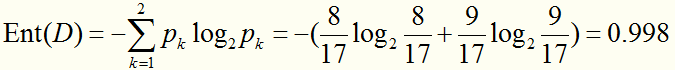
第二步:
计算使用属性集合{色泽,根蒂,敲声......}中的哪个属性进行数据集划分可以带来最高的信息增益。
先计算“色泽”:
根据色泽可以将数据集D分为3个子集:
D1包含{1,4,6,10,13,17}(正例p1=3/6,反例占p2=3/6)、D2包含{2,3,7,8,9,15}(正例p1=4/6,反例占p2=2/6)、D3包含{5,11,12,14,16}(正例p1=1/5,反例占p2=4/5).
求每个节点的信息熵:
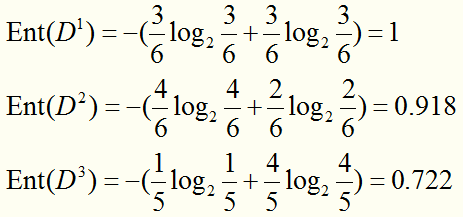
计算使用“色泽”划分数据集后的信息增益:
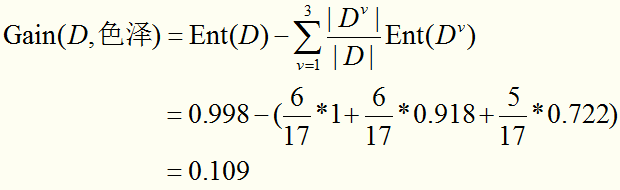
类似的,计算出使用其他属性划分数据集后的信息增益:

显然,选择“纹理”划分后信息增益最大,于是,通过“纹理”划分数据集,各分支节点包含样例子集的情况是:
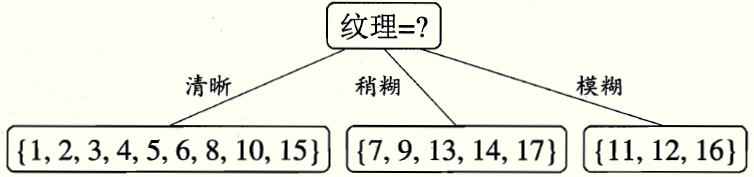
第三步:
在每个子节点上递归执行相同的算法,便可得到决策树,如下:
|
使用C4.5算法生成决策树 |
实际上,信息增益准则对可取值数目较多的属性有所偏好(这种偏好是不好的,他会妨碍我们在节点上找到最优的划分特征,最终导致建立的决策树模型复杂、额外增加计算量。说到底就是这是基于“信息增益”选择特征的缺陷),为减少这种偏好的影响,C4.5算法不直接采用信息增益,而是使用“信息增益率”来选择最优划分特征。信息增益率定义为:
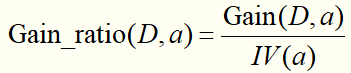
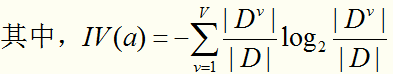
需要注意的是:信息增益率对可取值数目较少的属性有所偏好。
因此,C4.5算法使用了一个启发式:先选出信息增益高于平均水平的属性,再从中选择信息增益率最高的。
|
使用CART算法生成决策树 |
CART算法是基于“基尼指数”选择最优划分属性的,数据集D的纯度可以用基尼值表示:
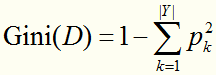
直观来说,Gini(D)反映了从数据集D中随机抽取两个样本,其标记不一致的概率(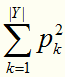 表示随机抽2个样本,标记相同的概率)。因此,Gini(D)越小,则数据集的纯度越高。选择属性a的基尼指数(基尼值减少程度)定义为
表示随机抽2个样本,标记相同的概率)。因此,Gini(D)越小,则数据集的纯度越高。选择属性a的基尼指数(基尼值减少程度)定义为
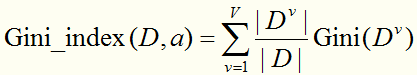
于是,我们要选择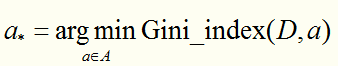 (基尼指数最小的特征)作为最优划分属性。
(基尼指数最小的特征)作为最优划分属性。
|
预剪枝和后剪枝 |
剪枝是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有:“预剪枝”和“后剪枝”。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树准确率提升,则停止划分并将当前结点标记为叶结点;后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树准确率提升,则将该子树替换为叶节点。
如何判断决策树准确率是否提升呢?可以使用性能评估的方法,如:留出法,即预留一部分数据用作“验证集”以进行性能评估。
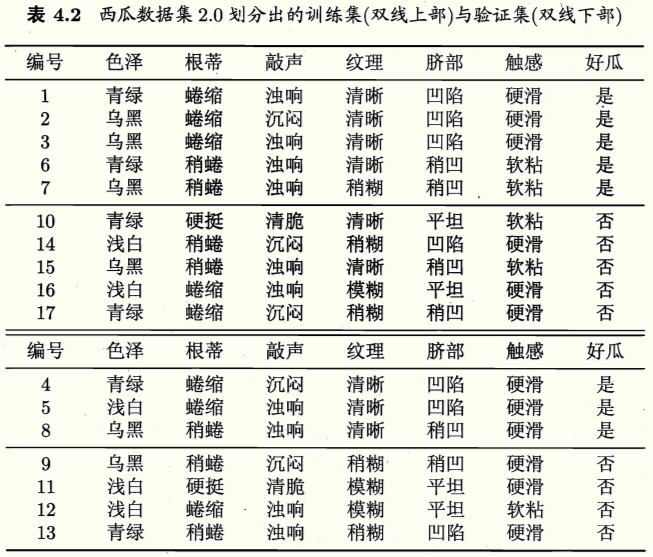
假定这里使用信息增益准则生成如下决策树:
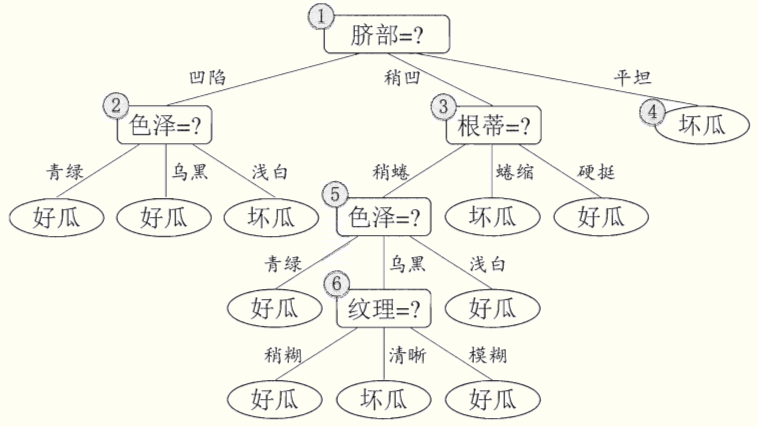 (准确率为42.9%)
(准确率为42.9%)
先讨论“预剪枝”:
预剪枝是在建造决策树的过程中执行的,如果发现某个节点划分后准确率没有提高,就禁止划分。
优点:预剪枝使得决策树的分支都没有“展开”,降低了过拟合的风险,减小了训练时间。
缺点:有欠拟合的风险。因为有些分支的当前划分虽不能提升准确率、甚至会暂时导致准确率下降,但是在其基础上的后续划分却有可能显著提升准确率。
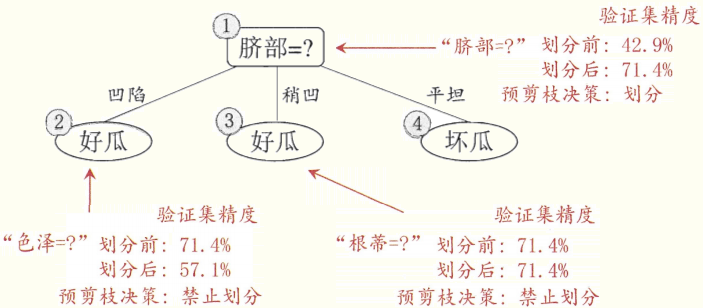 (准确率为71.4%)
(准确率为71.4%)
再讨论“后剪枝”:
后剪枝先从训练集生成一棵完成决策树,然后慢慢砍树,砍的位置:当前决策树叶节点的父节点,砍的条件是:如果能提高准确率就砍。
优点:欠拟合风险很小,准确率一般优于“预剪枝”决策树。
缺点:训练时间长。
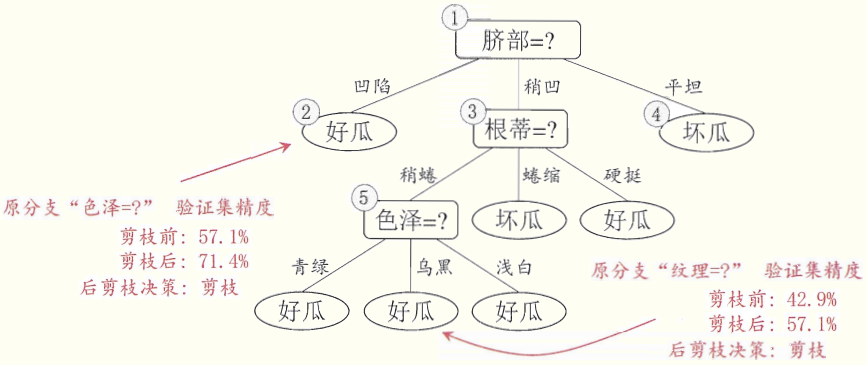 (准确率为71.4%)
(准确率为71.4%)
以上剪枝的过程引自周志华《机器学习》直观易于理解;李航《统计学习方法》中的剪枝是通过定义一个损失函数,然后也是像“后剪枝”一样,递归地从树的叶节点向上回缩。
两人算法的不同点在于:李航的算法不是单单看准确率,而是同时权衡准确率和树的复杂度两个因素,并通过改变参数控制两者的影响力。
两人算法的相同点在于:最终目的都是提升决策树的泛化性能。
|
应用:遇到连续与缺失值怎么办? |
先讨论“连续”:
之前讨论的都是基于离散属性来生成决策树。当遇到连续属性时,最简单的策略是采用“二分法”对连续属性进行处理。
具体步骤是:先将连续属性排序,假设有划分点t,基于t便可将D划分为两部分。那么,连续属性划分的关键就在于如何选划分点t,假设我们有排好序的序列:a1,a2,...,an,划分点可以从相邻两个元素的中位点组成的集合中选: ,选择的依据就是哪个划分点带来的信息增益大,就选哪个划分点。
,选择的依据就是哪个划分点带来的信息增益大,就选哪个划分点。
假设数据集:
在决策树学习的开始,根节点包含17个训练样本,“含糖率”的候选划分点集合包含16个候选值:{0.049, 0.074, ... ,0.418},可以计算出使用划分点0.126时,信息增益最大,为:0.349。但是还是没有竞争过 ,所以根节点的宝座还是要由“纹理”来坐。此后结点划分过程递归进行,最终基于信息增益准则生成的决策树是:
,所以根节点的宝座还是要由“纹理”来坐。此后结点划分过程递归进行,最终基于信息增益准则生成的决策树是:
注意:与离散属性不同,若当前结点划分属性为连续属性,该连续属性还能作为其后代结点的划分属性。例如在父节点使用了“密度≤0.381”,不会禁止在子节点上使用“密度≤0.294”
再讨论“缺失”:
现实任务中常会遇到不完整样本,即样本的某些属性值缺失。如果抛弃不完整的样本,显然是一种对数据信息的浪费。因此,要想办法利用有缺失属性值的训练样本。假设有以下数据集:

我们需解决两个问题:
(1)如何在属性缺失的情况下进行划分属性的选择?
(2)给定划分属性,若该样本在该属性上的值缺失,如何对样本进行划分?
给定数据集D和属性a,令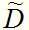 表示D中在属性a上不缺失的样本子集。
表示D中在属性a上不缺失的样本子集。
对问题(1),假定属性a有V个可取值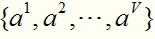 ,令
,令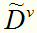 表示
表示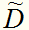 中在属性a上取值为
中在属性a上取值为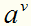 的样本子集,
的样本子集,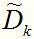 表示中属于第k类的样本子集。假定为每个样本x赋予一个权重
表示中属于第k类的样本子集。假定为每个样本x赋予一个权重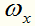 ,并定义
,并定义
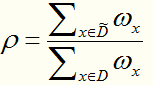 ,完整性的比重
,完整性的比重
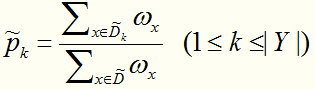 ,第k类样本占得比重
,第k类样本占得比重
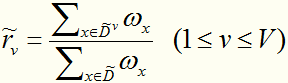 ,在某属性上取值为v的样本占得比重
,在某属性上取值为v的样本占得比重
因此,可以将信息增益的计算式推广为:
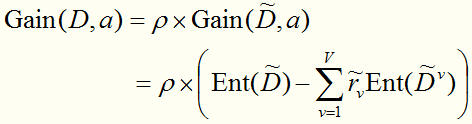
对问题(2),若样本a 在划分属性a 上的取值已知,则将a 划入与其取值对应的子结点,且样本权值在子结点中保持为。若样本a 在划分属性a上的取值未知,则将a 同时划入所有子结点,且样本权值在与属性值 对应的子结点中调整为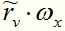 ; 直观地看,这就是让同一个样本以不同的概率划入到不同的子结点中去。
; 直观地看,这就是让同一个样本以不同的概率划入到不同的子结点中去。
|
多变量决策树 |
通过一个例子来解释,假设有训练集:
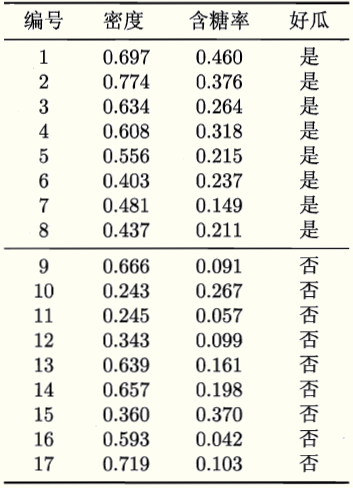
若使用单变量决策树可以产生如下决策树,决策边界:
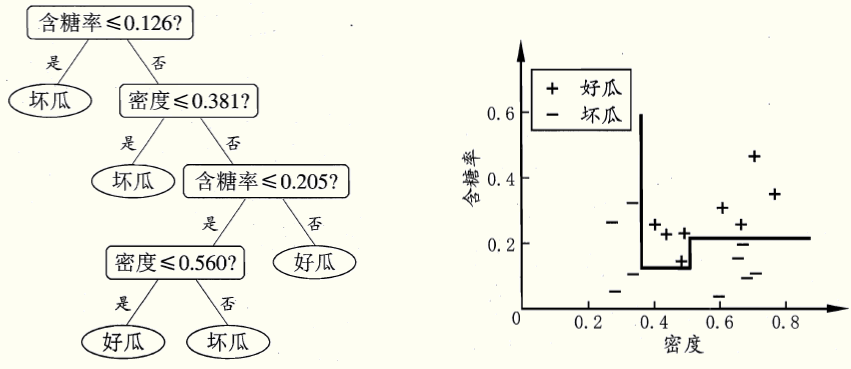
单变量决策树的决策边界是与坐标轴垂直或水平的。因此会造成决策树深度过高,模型较复杂。
若使用多变量决策树可以产生如下决策树,决策边界:
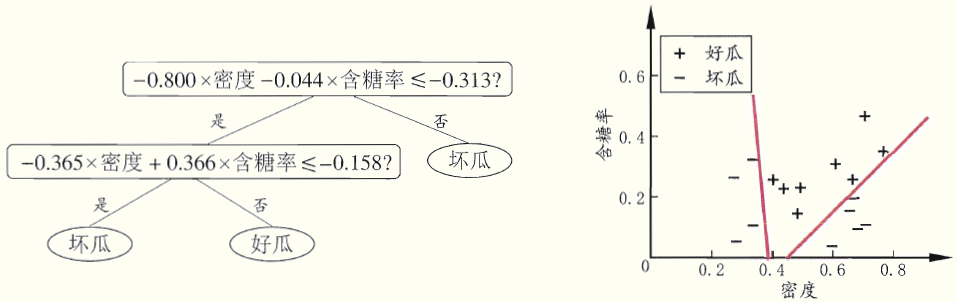
多变量决策树的决策边界可以是斜的(利用了多个属性的线性组合)。因此会造成决策树深度变低,模型变简单。
|
Python代码(sklearn库) |
待续...
【机器学习速成宝典】模型篇06决策树【ID3、C4.5、CART】(Python版)的更多相关文章
- 【机器学习速成宝典】模型篇02线性回归【LR】(Python版)
目录 什么是线性回归 最小二乘法 一元线性回归 多元线性回归 什么是规范化 Python代码(sklearn库) 什么是线性回归(Linear regression) 引例 假设某地区租房价格只与房屋 ...
- 决策树(ID3,C4.5,CART)原理以及实现
决策树 决策树是一种基本的分类和回归方法.决策树顾名思义,模型可以表示为树型结构,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布. [图片上传失败...(image ...
- 【Spark机器学习速成宝典】模型篇03线性回归【LR】(Python版)
目录 线性回归原理 线性回归代码(Spark Python) 线性回归原理 详见博文:http://www.cnblogs.com/itmorn/p/7873083.html 返回目录 线性回归代码( ...
- 【Spark机器学习速成宝典】模型篇08支持向量机【SVM】(Python版)
目录 什么是支持向量机(SVM) 线性可分数据集的分类 线性可分数据集的分类(对偶形式) 线性近似可分数据集的分类 线性近似可分数据集的分类(对偶形式) 非线性数据集的分类 SMO算法 合页损失函数 ...
- 【Spark机器学习速成宝典】模型篇01支持向量机【SVM】(Python版)
目录 支持向量机原理 支持向量机代码(Spark Python) 支持向量机原理 详见博文:http://www.cnblogs.com/itmorn/p/8011587.html 返回目录 支持向量 ...
- 决策树 ID3 C4.5 CART(未完)
1.决策树 :监督学习 决策树是一种依托决策而建立起来的一种树. 在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某 ...
- 21.决策树(ID3/C4.5/CART)
总览 算法 功能 树结构 特征选择 连续值处理 缺失值处理 剪枝 ID3 分类 多叉树 信息增益 不支持 不支持 不支持 C4.5 分类 多叉树 信息增益比 支持 ...
- ID3\C4.5\CART
目录 树模型原理 ID3 C4.5 CART 分类树 回归树 树创建 ID3.C4.5 多叉树 CART分类树(二叉) CART回归树 ID3 C4.5 CART 特征选择 信息增益 信息增益比 基尼 ...
- 【Spark机器学习速成宝典】基础篇04数据类型(Python版)
目录 Vector LabeledPoint Matrix 使用C4.5算法生成决策树 使用CART算法生成决策树 预剪枝和后剪枝 应用:遇到连续与缺失值怎么办? 多变量决策树 Python代码(sk ...
随机推荐
- echarts图标使用(一)
var data = []; // Parametric curve // for (var t = 0; t < 25; t += 0.001) { // var x = (1 + 0.25 ...
- python 元类 MetaClass
type() 动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的. 比方说我们要定义一个Hello的class,就写一个hello.py模块: class Hel ...
- Celery多队列配置
Celery多队列配置 Celery官方文档 项目结构 /proj -__init__ -app.py #实例化celery对象 -celeryconfig.py #celery的配置文件 -task ...
- NSUserDefaults的用法
NSUserDefaults适合存储轻量级的本地数据,比如要保存一个登陆界面的数据,用户名.密码之类的,个人觉得使用NSUserDefaults是首选.下次再登陆的时候就可以直接从NSUserDefa ...
- Maven项目构建利器03——第一个Maven工程
1.Maven工程的结构 我们需要通过Maven进行自动化构建, 以编译为例, Maven要想自动进行编译, 那么它必须知道Java源文件保存在哪里,所以要遵守Maven的约定,也就是约定大于配置,配 ...
- 五、vue中export和export default的使用
一.export的使用 比喻index.js要使用test.js中的数据,首先在test.js文件中进行导出操作 代码如下: export function list() { alert(" ...
- yum 问题
[root@localhost ~]# yum update There are no enabled repos. Run "yum repolist all" to see t ...
- Mysterious Crime CodeForces - 1043D (思维+组合数学)
Acingel is a small town. There was only one doctor here — Miss Ada. She was very friendly and nobody ...
- FPDF_CHAR_INFO
typedef struct { FX_WCHAR m_Unicode; FX_WCHAR m_Charcode; FX_INT32 m_Flag; FX_FLOAT m_FontSize; FX_F ...
- for 循环,range()函数和导入模块
(一)for语句构成: for i in range(5): print('My name is') for i in range(5): print('Jimmy Five Times ('+str ...