python自动化学习笔记10-数据驱动DDT与yml的应用
在测试工作中,针对某一API接口,或者某一个用户界面的输入框,需要设计大量相关的用例,每一个用例包含实际输入的各种可能的数据。通常的做法是,将测试数据存放到一个数据文件里,然后从数据文件读取,在脚本中循环输入测试数据,并对结果进行验证。
我们用Python的unittest+DDT结合的方式;
DDT包含类的装饰器ddt和两个方法装饰器data(直接输入测试数据),file_data(可以从json或者yaml中获取测试数据)
unittest框架:
import unittest def add(a,b):
res=a+b
return res class MyTest(unittest.TestCase):
#初始化
def setUp(self):
print('setup')
#结束
def tearDown(self):
print('tearDown') def test_add(self):
res=add(1,2)
self.assertEqual(res,3) if __name__ == '__main__':
unittest.main()
Unittest框架包含一个test Fixture,test Fixture由三部分组成,setup,testcase和teardown。Setup过程,是测试用例执行前的初始化过程,teardown过程,是在测试用例执行后,对资源进行释放与回收的过程;而testcase是具体的测试用例。
使用ddt模块需要先安装,并进行导入;
首先在头部导入ddt;
其次在测试类前声明使用ddt(@ddt.ddt);
第三步,在测试方法前,使用@ddt.data和@unpack进行修饰。
第四步、在data中填加测试数据
如下:
import unittest
import ddt def add(a,b):
res=a+b
return res #声明要使用ddt
@ddt.ddt
class MyTest(unittest.TestCase):
#初始化
def setUp(self):
print('setup') #ddt.data中添加测试数据
@ddt.data([1,2,3],[0,0,0],[999,1,1000])
@ddt.unpack
def test_add(self,a,b,e):
res=add(a,b)
self.assertEqual(res,e)
#结束
def tearDown(self):
print('tearDown') if __name__ == '__main__':
unittest.main()
执行查看结果:

可以看到我们程序中并没有写循环操作,测试框架自动的将测试数据分成多条测试用例来执行;
当测试数据较多的时候,直接写在ddt.data中又会使代码看起来比较混乱,所以我们可以使用ddt.file_data()直接读取yml文件来读取测试数据,如下:
yaml文件中我们定义了一个二维数组:

Python文件代码:
import unittest
import ddt
def add(a,b):
res=a+b
return res
#声明要使用ddt
@ddt.ddt
class MyTest(unittest.TestCase):
#初始化
def setUp(self):
print('setup')
#ddt.data中添加测试数据
# @ddt.data([1,2,3],[2,3,5])
@ddt.file_data('data.yml')
@ddt.unpack
def test_add(self,value):
print(value)
a=value[0]
b=value[1]
e=value[2]
res=add(a,b)
self.assertEqual(res,e)
#结束
def tearDown(self):
print('tearDown')
if __name__ == '__main__':
unittest.main()
上述代码我们加了print(value),为的是看一下value的取值,执行查看结果:

我们可以看到value的取值是一个list,读取yaml文件是一个二维数组[[1,2,3],[2,3,5]],循环取值后,取出一维数组[1,2,3],通过角标获取出对应的值,执行了需要测试的函数;
当yaml文件中存在字典格式时我们就需要传入一个**kwargs参数来保存相应的值;
示例如下:
以公司的一个登录接口为例,将测试用例写在yml文件中,Python中调用yml文件获取测试数据:
import unittest
import ddt
import requests
def add(a,b):
res=a+b
return res #声明要使用ddt
@ddt.ddt
class MyTest(unittest.TestCase):
#初始化
def setUp(self):
print('setup') #ddt.data中添加测试数据
# @ddt.data([1,2,3],[2,3,5])
# @ddt.file_data('data.yml')
# @ddt.unpack
# def test_add(self,value):
# print(value)
# a=value[0]
# b=value[1]
# e=value[2]
# res=add(a,b)
# self.assertEqual(res,e)
@ddt.file_data('jzjz_data.yml')
@ddt.unpack
def test_login(self,**kwargs):
#由于获取yml文件数据后是一个字典表,所以存入**kwargs中,从kwargs中获取各参数的值
#一般接口调用都会用到的参数信息,data,header,cookie,is_json 设置了默认值,如果测试数据中没有传,则传入默认值
url=kwargs.get('url')
method=kwargs.get('method')
data=kwargs.get('data',{})
check=kwargs.get('check')
header=kwargs.get('header',{})
is_json=kwargs.get('is_json',0)
cookie=kwargs.get('cookie',{})
#如果是get方法则走该分支
if method.upper=='GET':
res=requests.get(url=url,params=data,cookies=cookie,headers=header)
self.assertIn(check,res)
#如果是post请求走这个分支
else:
#如果传入的参数是json类型的,则类型写为json
if is_json==1:
res=requests.post(url=url,json=data,cookies=cookie,headers=header)
#如果传入的不是json,data正常传递给data参数
else:
#因为返回类型是页面的形式,我们返回值转化成为text,如果是json类型的,可以转化成json类型
res=requests.post(url=url,data=data,cookies=cookie,headers=header).text
self.assertIn(check,res) #结束
def tearDown(self):
print('tearDown') if __name__ == '__main__':
unittest.main()
yml文件的内容:
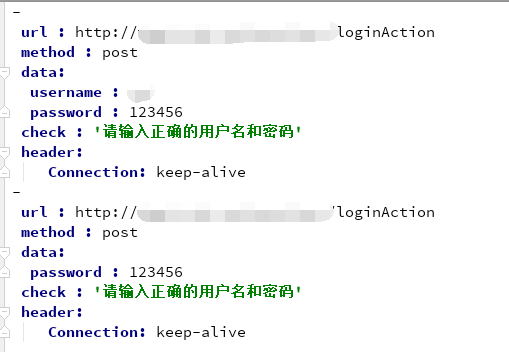
执行Python文件,查看结果:
setup
.tearDown
setup
.tearDown
setup
.tearDown
setup
.
tearDown
----------------------------------------------------------------------
Ran 4 tests in 36.532s
OK
测试用例直行通过,实际结果与预期结果一致;
在实际测试中,我们可能会用到发送邮件和生成测试报告,之前的学习中也已经说过了,这里简单写一下生成测试报告的过程:
if __name__ == '__main__':
# unittest.main()
#创建一个测试套件
suite=unittest.TestSuite()
#套件中加入所有的测试用例
suite.addTests(unittest.makeSuite(MyTest))
#创建测试报告
result=BeautifulReport(suite)
#生成报告
result.report(description='登录接口',filename='login_report.html',log_path=r'C:/besttest/newpython/besttest_code/练习/day11笔记')
执行查看结果,生成了测试报告:
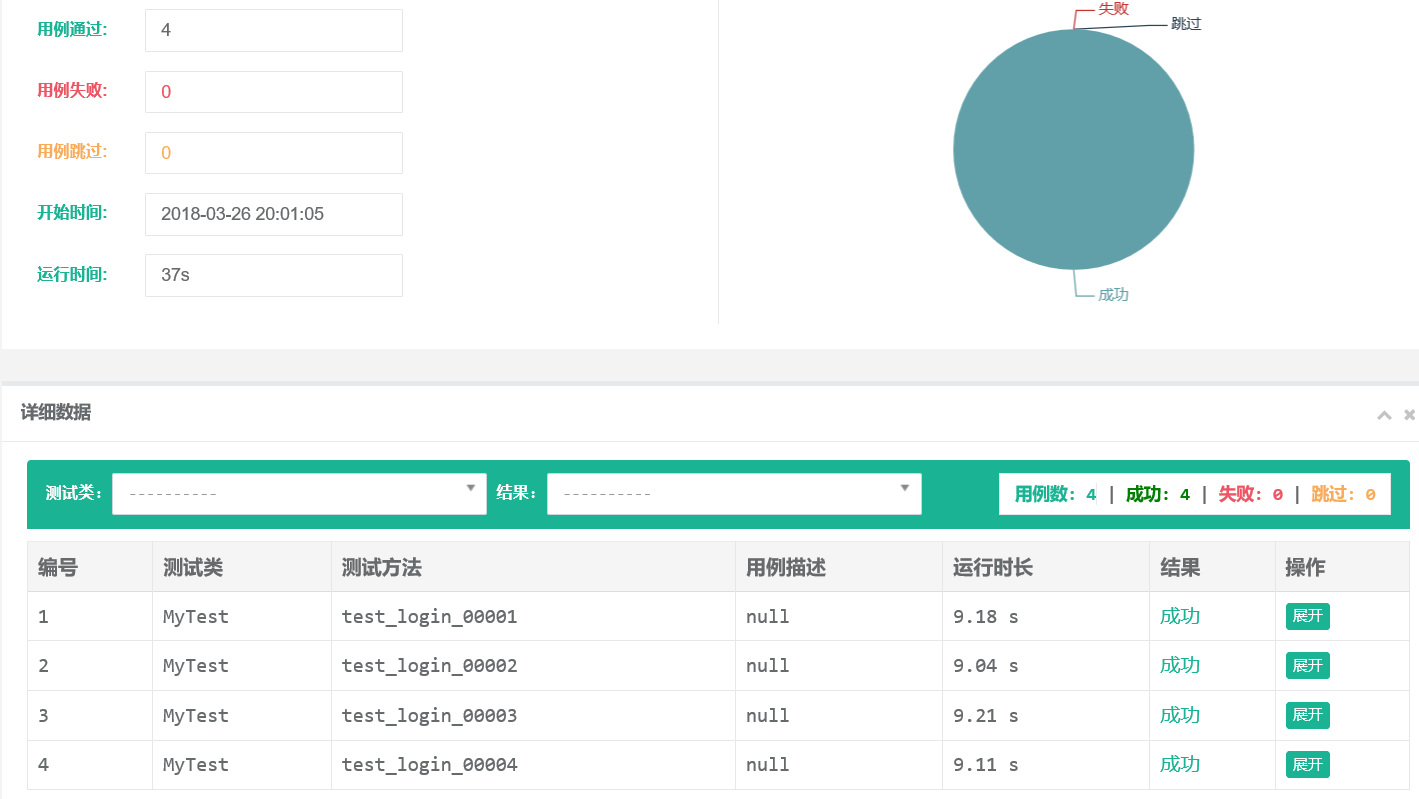
至此一个简单的接口自动化就完成了,上面说到的都是数据驱动,有些数据驱动不能满足的情况下,我们就需要代码来驱动,比如测试过程中后面的测试用例用到了前面调用接口成功后的返回值,这个时候就需要代码来实现了,后面也会把框架规范会,可以适用于以后的测试项目中。
python自动化学习笔记10-数据驱动DDT与yml的应用的更多相关文章
- Selenium2+Python自动化学习笔记(第1天)
参考[http://blog.csdn.net/henni_719/article/details/51096531]大神写的笔记,多谢大神共享. 哈哈,今天又找到一位大神写的Selenium2+Py ...
- 【python自动化学习笔记】
[python自动化第一篇:python介绍与入门] [python自动化第二篇:python入门] [python自动化第三篇:python入门进阶] [Python自动化第三篇(2):文 ...
- python自动化学习笔记11-自动化测试UTP框架
前面基本的unittest及ddt已经学过了,现在我们系统把这些知识结合起来,写一个简单的UTP自动化测试框架: 我们先来建基础目录,首先新建一个项目,项目下建父目录UTP,conf目录,用来存放配置 ...
- python自动化学习笔记3-集合、函数、模块
文件操作 上次学习到文件的读写,为了高效的读写文件,我们可以用循环的方式,一行一行的进行读写操作,打开文件的方法是open的方法,打开文件执行完后还要进行关闭操作. 一般的文件流操作都包含缓冲机制,w ...
- Python+Selenium学习笔记10 - send_keys上传文件
在火狐浏览器上传文件 上传前,同一个HTML文件在火狐和Edge浏览器显示有些不同 这是Firefox浏览器的显示 这是Edge浏览器 上传后 1 # coding = utf-8 2 3 from ...
- Android自动化学习笔记之MonkeyRunner:官方介绍和简单实例
---------------------------------------------------------------------------------------------------- ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Android自动化学习笔记:编写MonkeyRunner脚本的几种方式
---------------------------------------------------------------------------------------------------- ...
- Python Click 学习笔记(转)
原文链接:Python Click 学习笔记 Click 是 Flask 的团队 pallets 开发的优秀开源项目,它为命令行工具的开发封装了大量方法,使开发者只需要专注于功能实现.恰好我最近在开发 ...
随机推荐
- openjudge6252 带通配符的字符串匹配
描述 通配符是一类键盘字符,当我们不知道真正字符或者不想键入完整名字时,常常使用通配符代替一个或多个真正字符.通配符有问号(?)和星号(*)等,其中,“?”可以代替一个字符,而“*”可以代替零个或多个 ...
- Linux下汇编语言学习笔记54 ---
这是17年暑假学习Linux汇编语言的笔记记录,参考书目为清华大学出版社 Jeff Duntemann著 梁晓辉译<汇编语言基于Linux环境>的书,喜欢看原版书的同学可以看<Ass ...
- Ubuntu12.04之修改密码
Ubuntu 12.04 默认root没有密码 修改密码方式如下: test@localhost:~$ sudo passwd root [sudo] password for test: 输入新的 ...
- NOIP 2010 乌龟棋
P1541 乌龟棋 题目背景 小明过生日的时候,爸爸送给他一副乌龟棋当作礼物. 题目描述 乌龟棋的棋盘是一行 NN 个格子,每个格子上一个分数(非负整数).棋盘第1格是唯一的起点,第 NN 格是终点, ...
- 使用百度网盘实现自动备份VPS
http://ju.outofmemory.cn/entry/51536 经过轰轰烈烈的一轮网盘大战,百度网盘的容量已经接近无限(比如我的是3000多G ),而且百度网盘已经开放API,所以用来备份V ...
- win7开启超级管理员账户(Administrator)
win7开启超级管理员账户(Administrator) 不同于XP系统,Windows7系统据说出于安全的考虑,将超级管理员帐户"Administrator"在登陆界面给隐藏了, ...
- 最简单 NDK 样例
以下在 Ubuntu下 编译一个 c 语言 hello world 并在 android 手机或模拟器上执行 进入程序位置 cd ~/pnp5/jni 有三个文件 main.c Android.mk ...
- restlet 2.3.5 org.restlet包导入eclipse出现的com.sun.net.httpserver类包找不到问题
准备过一遍restlet 2.3.5 JavaEE的源码. 环境 eclipse3.7.2 和 jdk 7.0 将org.restlet 包增加到eclipse中.出现 com.sun.net.htt ...
- 【HNOI模拟By lyp】Day1
1 xlk1.1 题目描述 给定一棵大小为 n 的无根树,求满足以下条件的四元组 (a, b, c, d) 的个数: 1. 1 ≤ a < b ≤ n 2. 1 ≤ c < d ≤ n 3 ...
- HDU 5783Divide the Sequence
Divide the Sequence Time Limit: 5000/2500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Othe ...