hadoop-2.0.0-cdh4.1.2升级到hadoop-2.7.2
升级前准备:
如果是 centos6.x的系统得升级glibc和pam包
在/etc/ld.so.conf 文件里添加 /usr/src/jdk1.6.0_23/jre/lib/amd64/server,然后运行ldconfig命令
配置好新的hadoop-2.7.2到各个集群服务器上
配置好新的环境变量备用
开始升级:
1.停止hive、hbase、zookeeper等相关服务
2.检查文件(如果文件太多太费时间可以不做)
hadoop dfsadmin -safemode enter
检查元数据块(过滤所有以小圆点开始的行):
hadoop fsck / -files -blocks -locations |grep -v -E '^\.' > old-fsck.log
hadoop dfsadmin -safemode leave
3.停止hadoop集群
$HADOOP_HOME/bin/stop-all.sh
4.修改环境变量
source /etc/profile 各个集群都执行
echo $HADOOP_HOME 看是否是新的hadoop目录了
5.开始升级
hadoop-daemon.sh start namenode -upgrade 启动namenode升级
hadoop-daemons.sh start datanode 启动各个数据节点
打开日志文件观察有误错误,如果报内存溢出,修改hadoop-env.sh 文件的export HADOOP_HEAPSIZE,HADOOP_CLIENT_OPTS参数值和yarn-env.sh文件JAVA_HEAP_MAX参数值
打开50070端口web页面观察升级过程
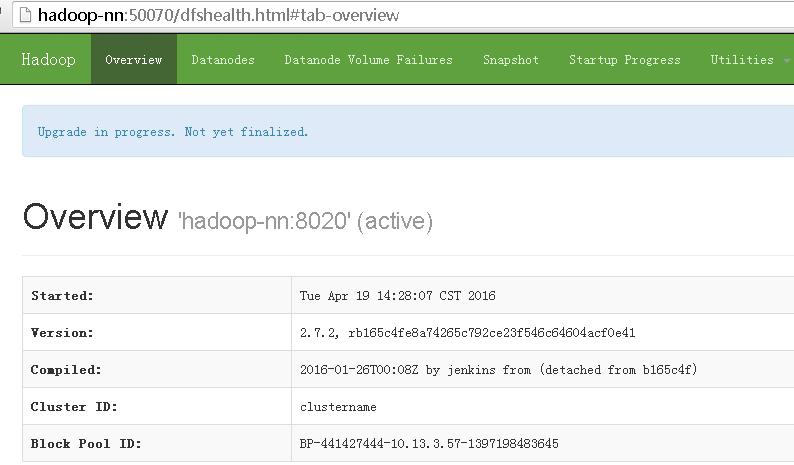

等所有数据节点全部升级完成后,检查数据完整性(此过程根据集群数量得等一段时间)
hadoop fsck /
有问题回滚命令:
hadoop-daemon.sh start namenode -rollback
hadoop-daemons.sh start datanode –rollback
6.提交升级
运行一段时间后,观察没有问题,可以提交升级
hdfs dfsadmin -finalizeUpgrade
hadoop-2.0.0-cdh4.1.2升级到hadoop-2.7.2的更多相关文章
- Ubuntu14.04用apt在线/离线安装CDH5.1.2[Apache Hadoop 2.3.0]
目录 [TOC] 1.CDH介绍 1.1.什么是CDH和CM? CDH一个对Apache Hadoop的集成环境的封装,可以使用Cloudera Manager进行自动化安装. Cloudera-Ma ...
- Hadoop2.0.0+CDH4.5.0集群配置
Hadoop 2.0.0-cdh4.5.0安装:http://blog.csdn.net/u010967382/article/details/18402217 CDH版本下载:http://arch ...
- Hadoop 2.4.0新特性介绍
在2014年4月7日,Apache公布了Hadoop 2.4.0 .相比于hadoop 2.3.0,这个版本号有了一定的改进,突出的变化能够总结为下列几点(官方文档说明): 1 支持HDFS訪问控制列 ...
- Spark 1.0.0 横空出世 Spark on Yarn 部署(Hadoop 2.4)
就在昨天,北京时间5月30日20点多.Spark 1.0.0最终公布了:Spark 1.0.0 released 依据官网描写叙述,Spark 1.0.0支持SQL编写:Spark SQL Progr ...
- Centos 6.5 X64 环境下编译 hadoop 2.6.0 --已验证
Centos 6.5 x64 hadoop 2.6.0 jdk 1.7 protobuf-2.5.0 maven-3.0.5 set environment export JAVA_HOME=/hom ...
- mac OS X Yosemite 上编译hadoop 2.6.0/2.7.0及TEZ 0.5.2/0.7.0 注意事项
1.jdk 1.7问题 hadoop 2.7.0必须要求jdk 1.7.0,而oracle官网已经声明,jdk 1.7 以后不准备再提供更新了,所以趁现在还能下载,赶紧去down一个mac版吧 htt ...
- eclipse/intellij idea 远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试 ...
- 64位centos 下编译 hadoop 2.6.0 源码
64位os下为啥要编译hadoop就不解释了,百度一下就能知道原因,下面是步骤: 前提:编译源码所在的机器,必须能上网,否则建议不要尝试了 一. 下载必要的组件 a) 下载hadoop源码 (当前最新 ...
- 系统补丁更新导致MVC3.0.0升级到3.0.1的问题解决
在更新了系统补丁之后,会不知觉的将MVC3.0.0升级到MVC3.0.1的问题,解决的思路如下: 1.全部MVC引用使用NuGet进行包的管理. 2.单独把MVC库抽离出来,然后放在单独的项目文件夹, ...
- Hadoop 2.2.0 4结点集群安装 非HA
总体介绍 虚拟机4台,分布在1个物理机上,配置基于hadoop的集群中包括4个节点: 1个 Master, 3个 Salve,i p分布为: 10.10.96.33 hadoop1 (Master) ...
随机推荐
- stm32 PWM输出学习
STM32 的定时器除了 TIM6 和 7,其他的定时器都可以用来产生 PWM 输出.其中高级定时器 TIM1 和 TIM8 可以同时产生多达 7 路的 PWM 输出.通用定时器也能同时产生多达 4路 ...
- QML 读取本地文件内容
QML 对本地文件的读写 QML 里似乎没有提供直接访问本地文件的模块,但是我们能够自己扩展 QML,给它加上访问本地文件的能力. Qt 官方文档对 QML 是这样介绍的: It defines an ...
- java的wait/notify小结
wait()是使线程停止运行,而notify使停止的线程继续运行 wait()锁释放与notify()锁不释放 当线程呈wait状态时,调用线程对象的interrupt()方法会出现异常 带一个参数的 ...
- 现有分布式技术(socket、.net remoting、asp.net webservice、WSE、ES)和wcf的比较及优势
1:socket VS remoting 使用socket无疑是效率最高的.但是,在复杂的接口环境下,socket的开发效率也是最低的.故在兼顾开发效率的情况下,可以使用remoting来代替sock ...
- DataGridView带图标的单元格实现
目的: 扩展 C# WinForm 自带的表格控件,使其可以自动判断数据的上下界限值,并标识溢出. 这里使用的方法是:扩展 表格的列 对象:DataGridViewColumn. 1.创建类:Data ...
- Java基础入门 - 标识符及其命名规范
类名.变量名.方法名都称为标识符 标识符命名规范: 由字母(A-Z或a-z).数字.下划线(_)和美元符($)中的一种或多种组合而成 不可以数字开头 大小写敏感 关键字不能用作标识符 合法标识符如:D ...
- sass命令
tip:sass报错解决 通过ruby编译scss时,发现编译报错,内容如下: Conversion error: Jekyll::Converters::Scss encountered an ...
- BZOJ1044: [HAOI2008]木棍分割(dp 单调队列)
题意 题目链接 Sol 比较套路的一个题. 第一问二分答案check一下 第二问设\(f[i][j]\)表示前\(i\)个数,切了\(j\)段的方案数,单调队列优化一下. 转移的时候只需要保证当前段的 ...
- DOMNodeInserted,DOMNodeRemoved 和监听内容变化插件
元素的增加 删除 及事件监听 <!DOCTYPE html> <html lang="en"> <head> <meta charset= ...
- 基于表单布局:分析过时的table结构与当下的div结构
一些话在前面 最近做了百度前端学院一个小任务,其中涉及到表单布局的问题, 它要处理的布局问题:左边的标签要右对齐,右边的输入框.单选按钮等要实现左对齐. 从开始入门就被告知table布局已经过时了,当 ...