Sqoop Export HDFS
Sqoop Export应用场景——直接导出
直接导出
我们先复制一个表,然后将上一篇博文(Sqoop Import HDFS)导入的数据再导出到我们所复制的表里。
sqoop export \
--connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' \
--username root \
--password-file /user/hadoop/.password \
--table user_info_copy \
--export-dir /user/hadoop/user_info \
--input-fields-terminated-by "," //此处分隔符根据建表时所用分隔符确定,可查看博客sqoop导出hive数据到mysql错误: Caused by: java.lang.RuntimeException: Can't parse input data
运行过程如下:
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1529567189245_0010 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=3
Data-local map tasks=3 //map数为3,在下面可以指定map数来执行导出操作
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ExportJobBase: Transferred bytes in 38.2702 seconds (18.1865 bytes/sec)
// :: INFO mapreduce.ExportJobBase: Exported records.
导入成功后我们再手动查看一下数据库。
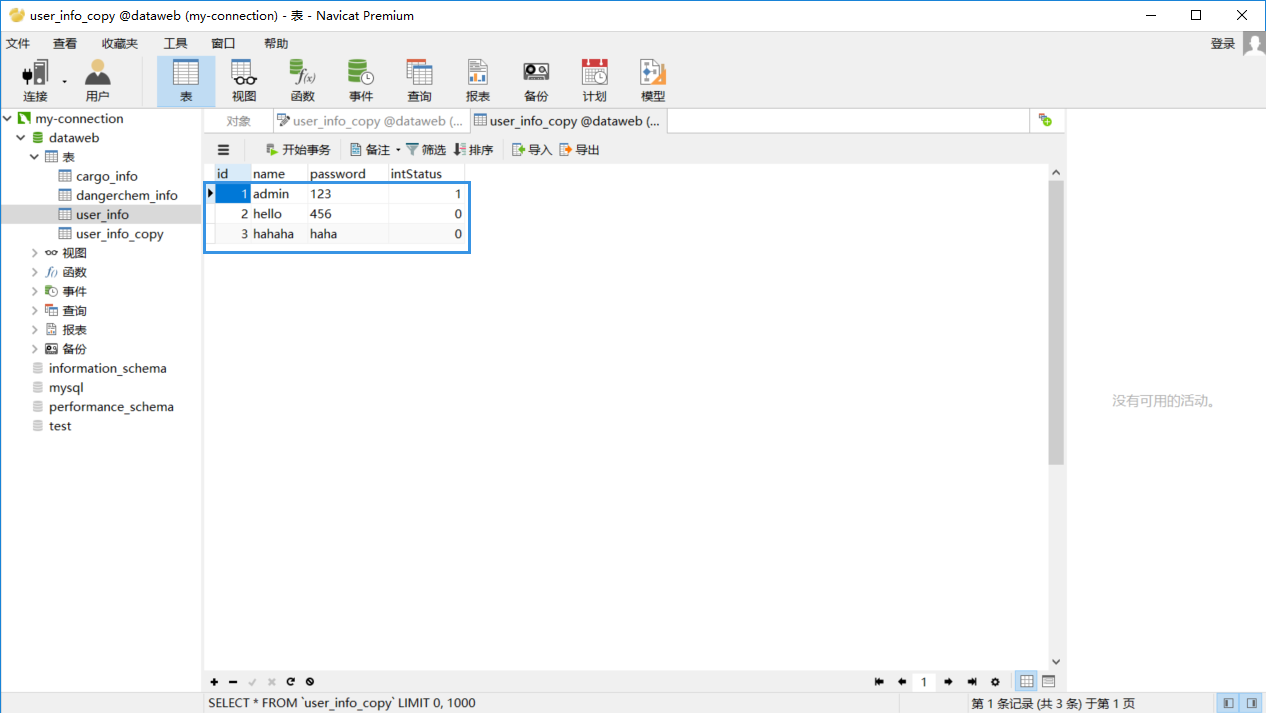
上图表示我们的导入是成功的。
指定Map个数
sqoop export \
--connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' \
--username root \
--password-file /user/hadoop/.password \
--table user_info_copy \
--export-dir /user/hadoop/user_info \
--input-fields-terminated-by "," \
-m 1 //map数设定为1
先清除本地数据库数据之后再测试。

// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1529567189245_0011 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=1
Data-local map tasks=1 //map数变为了1个
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ExportJobBase: Transferred bytes in 25.1976 seconds (12.9774 bytes/sec) //执行时间也较上面减少了
// :: INFO mapreduce.ExportJobBase: Exported records.
Sqoop Export应用场景——插入和更新
先将已经插入的信息作一点修改,然后重新导入,导入之后会将我们修改的信息又给复原回去。

执行命令
sqoop export \
--connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' \
--username root \
--password-file /user/hadoop/.password \
--table user_info_copy \
--export-dir /user/hadoop/user_info \
--input-fields-terminated-by "," \
-m \
--update-key id \
--update-mode allowinsert //默认为updateonly(只更新),也可以设置为allowinsert(允许插入)
执行完毕后,信息又重新修改了回来。

Sqoop Export应用场景
事务处理
在将HDFS上的数据导入到数据库中之前先导入到一个临时表tmp中,如果导入成功的话,再转移到目标表中去。
sqoop export \
--connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' \
--username root \
--password-file /user/hadoop/.password \
--table user_info_copy \
--staging-table user_info_tmp \ //临时表需要提前创建,可直接复制再重命名
--clear-staging-table \
--export-dir /user/hadoop/user_info \
--input-fields-terminated-by ","
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1529567189245_0014 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ExportJobBase: Transferred bytes in 36.8371 seconds (18.894 bytes/sec)
// :: INFO mapreduce.ExportJobBase: Exported records.
// :: INFO mapreduce.ExportJobBase: Starting to migrate data from staging table to destination.
// :: INFO manager.SqlManager: Migrated 3 records from `user_info_tmp` to `user_info_copy`
字段不对应问题
先将数据库中的表内容导入到hdfs上(但不是所有的内容都导入,而是只导入部分字段,在这里就没有导入id字段),然后再从hdfs导出到本地数据库中。
[hadoop@centpy hadoop-2.6.]$ sqoop import --connect jdbc:mysql://202.193.60.117/dataweb
> --username root
> --password-file /user/hadoop/.password
> --table user_info
> --columns name,password,intStatus //确定导入哪些字段
> --target-dir /user/hadoop/user_info
> --delete-target-dir
> --fields-terminated-by ","
> -m 1 [hadoop@centpy hadoop-2.6.]$ hdfs dfs -cat /user/hadoop/user_info/part-m-* admin,, hello,, hahaha,haha,
可以看到我们此处导入的数据和数据库相比少了“id”这个字段,接下来,我们如果不使用上面的columns字段,仍然按照原来的方式导入,肯定会报错,因为这和我们的数据库格式和字段不匹配。如下所示:
[hadoop@centpy hadoop-2.6.]$ sqoop export \
> --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' \
> --username root \
> --password-file /user/hadoop/.password \
> --table user_info_copy \
> --export-dir /user/hadoop/user_info \
> --input-fields-terminated-by "," \
> -m 1
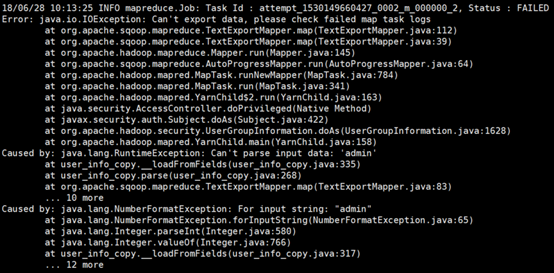
要实现字段不匹配导入必须使用columns字段导出。
[hadoop@centpy hadoop-2.6.]$ sqoop export \
> --connect 'jdbc:mysql://202.193.60.117/dataweb?useUnicode=true&characterEncoding=utf-8' \
> --username root \
> --password-file /user/hadoop/.password \
> --table user_info_copy \
> --columns name,password,intStatus \
> --export-dir /user/hadoop/user_info \
> --input-fields-terminated-by "," \
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Sqoop Export HDFS的更多相关文章
- (MySQL里的数据)通过Sqoop Import HDFS 里 和 通过Sqoop Export HDFS 里的数据到(MySQL)(五)
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出 一.MySQL里的数据通过Sqoop import HDFS 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. ...
- (MySQL里的数据)通过Sqoop Import Hive 里 和 通过Sqoop Export Hive 里的数据到(MySQL)
Sqoop 可以与Hive系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HIVE_HOME的环境变量. 具体,见我的如下博客: hadoop2.6.0(单节点)下Sqoo ...
- (MySQL里的数据)通过Sqoop Import HBase 里 和 通过Sqoop Export HBase 里的数据到(MySQL)
Sqoop 可以与HBase系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME的环境变量. 具体,见我的如下博客: hadoop2.6.0(单节点)下Sq ...
- sqoop导入hdfs上的数据到oracle
/opt/sqoop-/bin/sqoop export --table mytablename --connect jdbc:oracle:thin:@**.**.**.**:***:dbasena ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
- 通过sqoop将hdfs数据导入MySQL
简介:Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracl ...
- Sqoop与HDFS、Hive、Hbase等系统的数据同步操作
Sqoop与HDFS结合 下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出. Sqoop import 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. 我们来 ...
- 一个sqoop export案例中踩到的坑
案例分析: 需要将hdfs上的数据导出到mysql里的一张表里. 虚拟机集群的为:centos1-centos5 问题1: 在centos1上将hdfs上的数据导出到centos1上的mysql里: ...
- sqoop从hdfs 中导出数据到mysql
bin/sqoop export \ --connect "jdbc:mysql://mini1:3306/study?useUnicode=true&characterEncodi ...
随机推荐
- 杂项-Log:NLog
ylbtech-杂项-Log:NLog NLog是一个基于.NET平台编写的类库,我们可以使用NLog在应用程序中添加极为完善的跟踪调试代码. NLog是一个简单灵活的.NET日志记录类库.通过使用N ...
- libvirt, libvirt-python, libvirtd 关系浅析
libvirt 官方解释: http://libvirt.org/ 见分隔线以下. 我的理解:libvirt 作为一个中间层,封装了对下层虚拟化 hypervisor 的操作方法.也就是说,无论你是 ...
- 编译内核是出现:arch/arm/mm/tlb-v4wbi.S:64:error: too many positional arguments
内核:Linux-3.4.2 编译内核出现arch/arm/mm/tlb-v4wbi.S:64:error: too many positional arguments 交叉工具链太老了,换新一点的. ...
- Flask01 初识flask、创建flask应用、flask启动配置
1 什么是flask Flask是一个使用 Python 编写的轻量级 Web 应用框架.其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 . 百度百科:点击前往 中文文档: ...
- Luogu 4868 Preprefix sum
类似于树状数组维护区间的方法. 每一次询问要求$\sum_{i = 1}^{n}\sum_{j = 1}^{i}a_j$. 展开一下: $\sum_{i = 1}^{n}\sum_{j = 1}^{i ...
- Linux 启动顺序
Linux 启动顺序:1. BIOS自检2. 运行系统内核并检测硬件3. 运行系统的第一个进程init4. init读取系统引导配置文件/etc/inittab中的信息进行初始化 ...
- 6.7 安装vim
- push和commit的区别
push和commit的区别 git作为支持分布式版本管理的工具,它管理的库(repository)分为本地库.远程库.git commit操作的是本地库,git push操作的是远程库. git c ...
- 使用IDEA编译netty4
本来计划一天一篇博文的,结果周末加班加的不亦乐乎,对整个项目重构添加国际化的功能,不停的使用native2ascii工具 使用IDEA编译原有的netty4要报错,我修改了下pom.xml,编译成功了 ...
- hdu1078
#include <stdio.h> #include <string.h> #include <algorithm> using namespace std; i ...