Kafka实战系列--Kafka API使用体验
前言:
kafka是linkedin开源的消息队列, 淘宝的metaq就是基于kafka而研发. 而消息队列作为一个分布式组件, 在服务解耦/异步化, 扮演非常重要的角色. 本系列主要研究kafka的思想和使用, 本文主要讲解kafka的一些基本概念和api的使用.
*) 准备工作
1) 配置maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.1.1</version>
</dependency>
2).配置hosts
vim /etc/hosts
把kafka集群相关的ip及其hostname, 配置到kafka客户端的本地机器
*) Kafka的基础知识
1). Broker, Zookeeper, Producer, Consumer
Broker具体承担消息存储转发工作, Zookeeper则用与元信息的存储(topic的定义/消费进度), Producer则是消息的生产者, Consumer则是消息的消费者.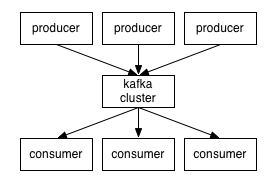
2). Topic, Partition, Replication, Consumer Group
Topic对应一个具体的队列, 在Kafka的概念中, 一个应用一个队列. 应用数据往往呈现部分有序的特点, 因此对kafka的队列, 引入partition的概念, 即可topic划分为多个partition. 单个Partition内保证有序, Partition间不保证. 这样作的好处, 是充分利用了集群的能力, 均匀负载和提高性能.
Replication主要为了高可用性, 保证部分节点失效的恶劣情况下, 队列数据能不丢.
Consumer Group的概念的引入, 很有创新性, 把以往传统队列(topic模式, queue模式)的属性从队列本身挪到了消费端. 若要使用queue模式, 则所有的消费端都采用统一个consumer group, 若采用topic模式, 则所有的客户端都设置为不同的consumer group. 其partition的消费进度在zookeeper有所保存.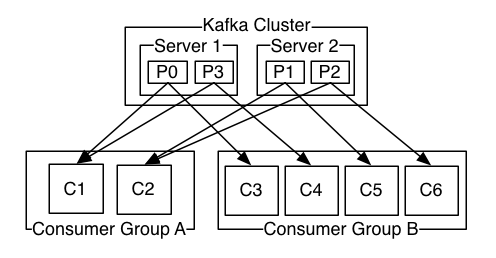
*) Kafka API的简单样列代码
1). 生产者代码
分区类代码片段
public class SimplePartitioner implements Partitioner {
public SimplePartitioner (VerifiableProperties props) {
}
public int partition(Object key, int numPartitions) {
return (key.hashCode() & 0x0FFFFFFF) % numPartitions;
}
}
评注: SimplePartitioner用于对消息进行分发到具体的partition中, 有消息的key来决定, 这个有点像map/reduce中的partition机制.
生产者代码片段
Properties props = new Properties();
// 配置metadata.broker.list, 为了高可用, 最好配两个broker实例
props.put("metadata.broker.list", "127.0.0.1:9092");
// serializer.class为消息的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 设置Partition类, 对队列进行合理的划分
props.put("partitioner.class", "mmxf.kafka.practise.SimplePartitioner");
// ACK机制, 消息发送需要kafka服务端确认
props.put("request.required.acks", "1"); ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config); // KeyedMessage<K, V>
// K对应Partition Key的类型
// V对应消息本身的类型
// topic: "test", key: "key", message: "message"
KeyedMessage<String, String> message = new KeyedMessage<String, String>("test", "key", "message");
producer.send(message); // 关闭producer实例
producer.close();
2). 消费者代码
使用High Level Consumer的API 线程模型和Partition数最好能保持一致, 即One Thread For Partition
参考sample样例: https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example
代码片段如下:
public static void main(String[] args) {
// *) 创建ConsumerConfig
Properties props = new Properties();
// 设置zookeeper的链接地址
props.put("zookeeper.connect", "127.0.0.1:2181");
// 设置group id
props.put("group.id", "group_id");
// kafka的group 消费记录是保存在zookeeper上的, 但这个信息在zookeeper上不是实时更新的, 需要有个间隔时间更新
props.put("auto.commit.interval.ms", "1000");
ConsumerConfig consumerConfig = new ConsumerConfig(props);
ConsumerConnector consumer = (ConsumerConnector) Consumer.createJavaConsumerConnector(consumerConfig);
String topic = "test";
int threadNum = 1;
// *) 设置Topic=>Thread Num映射关系, 构建具体的流
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic,threadNum);
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);
// *) 启动线程池去消费对应的消息
ExecutorService executor = Executors.newCachedThreadPool();
for ( final KafkaStream<byte[], byte[]> stream : streams ) {
executor.submit(new Runnable() {
public void run() {
ConsumerIterator<byte[], byte[]> iter = stream.iterator();
while ( iter.hasNext() ) {
MessageAndMetadata<byte[] , byte[]> mam = iter.next();
System.out.println(
String.format("thread_id: %d, key: %s, value: %s",
Thread.currentThread().getId(),
new String(mam.key()),
new String(mam.message())
)
);
}
}
});
}
try {
Thread.sleep(1000 * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
// *) 优雅地退出
consumer.shutdown();
executor.shutdown();
while ( !executor.isTerminated() ) {
try {
executor.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
}
}
}
结果输出:
thread_id: 18, key: key, value: message
Kafka实战系列--Kafka API使用体验的更多相关文章
- Kafka实战系列--Kafka的安装/配置
*) 安装和测试 cd /path/to/server#) 下载kafka二进制包wget http://apache.fayea.com/apache-mirror/kafka/0.8.1.1/ka ...
- Kafka实战-Kafka到Storm
1.概述 在<Kafka实战-Flume到Kafka>一文中给大家分享了Kafka的数据源生产,今天为大家介绍如何去实时消费Kafka中的数据.这里使用实时计算的模型——Storm.下面是 ...
- Kafka实战-Kafka Cluster
1.概述 在<Kafka实战-入门>一篇中,为大家介绍了Kafka的相关背景.原理架构以及一些关键知识点,本篇博客为大家来赘述一下Kafka Cluster的相关内容,下面是今天为大家分享 ...
- Kafka科普系列 | Kafka中的事务是什么样子的?
事务,对于大家来说可能并不陌生,比如数据库事务.分布式事务,那么Kafka中的事务是什么样子的呢? 在说Kafka的事务之前,先要说一下Kafka中幂等的实现.幂等和事务是Kafka 0.11.0.0 ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Kafka实战-数据持久化
1.概述 经过前面Kafka实战系列的学习,我们通过学习<Kafka实战-入门>了解Kafka的应用场景和基本原理,<Kafka实战-Kafka Cluster>一文给大家分享 ...
- Kafka实战-实时日志统计流程
1.概述 在<Kafka实战-简单示例>一文中给大家介绍来Kafka的简单示例,演示了如何编写Kafka的代码去生产数据和消费数据,今天给大家介绍如何去整合一个完整的项目,本篇博客我打算为 ...
- Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka 1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来 ...
随机推荐
- 微信小程序注册app
App() App() 函数用来注册一个小程序.接受一个 object 参数,其指定小程序的生命周期函数等. object参数说明 onLaunch Function 生命周期函数--监听小程序初 ...
- Core Data
• Core Data 是 iOS SDK 里的一个很强大的框架,允许程序员 以面向对象 的方式储存和管理数据 .使用 Core Data 框架,程序员可以很轻松有效 地通过面向对象的接口 ...
- aws ftp
amazon ec2 运行后,可以用key pair ssh到终端, 不得不承认key pair是很安全的一种方式, 但是安全意味着麻烦,要登陆ssh必须随身带着key pair, 不过个人见意还是不 ...
- Head First 设计模式 --4 工厂模式 抽象工厂模式
(用到了依赖倒置原则) 我们写的代码中,有的时候可能会出现根据外面给定的不同的参数在方法中根据参数实例化不同的实例,就是会根据不同的参数会new出不同的实例.如果这么写了,这段代码会非常的脆弱,一旦出 ...
- Windows 10:解决开机显示C:\WINDOWS\system32\config\systemprofile\Desktop不可用的方法
开机显示C:\WINDOWS\system32\config\systemprofile\Desktop不可用应该是不少网友都遇到过. 近日在使用Windows 10 Build 9926中,也出 ...
- sentinel搭建redis集群经验总结
一.protected-mode默认情况下,redis node和sentinel的protected-mode都是yes,在搭建集群时,若想从远程连接redis集群,需要将redis node和se ...
- 工作中使用的html5和css3 新特性
1.placeholder <input type="text" placeholder="请输入手机号码" class="phone" ...
- 日期转换时Safari中返回Invalid Date
问题: 进行日期转换时,Safari中会返回Invalid Date, 而IE 9, Firefox, Chrome and Opera显示正常,代码如下所示: var d = new Date(&q ...
- /etc/passwd和/etc/shadow
这两个路径分别是用于存储密码和隐形密码 让我们先来观察它,在了解它 [root@oc3408554812 ~]# cat /etc/passwd |grep carltoncarlton : ...
- Android - 广播接收者 - BroadcastReceiver
BroadcastReceiver 介绍: 广播是一种广泛运用的在应用程序之间传输信息的机制 .而 BroadcastReceiver 是对发送出来的广播 进行过滤接收并响应的一类组件 接受一种或者多 ...