Python自动化之常用模块
1 time和datetime模块
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time
# print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
# print(time.altzone) #返回与utc时间的时间差,以秒计算\
# print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
# print(time.localtime()) #返回本地时间 的struct time对象格式
# print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式
# print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
#print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
# 日期字符串 转成 时间戳
# string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
# print(string_2_struct)
# #
# struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
# print(struct_2_stamp)
#将时间戳转为字符串格式
# print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
# print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
#时间加减
import datetime
# print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
#print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
# print(datetime.datetime.now() )
# print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
# print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
# print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
# print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
#
# c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #时间替换
时间转换图
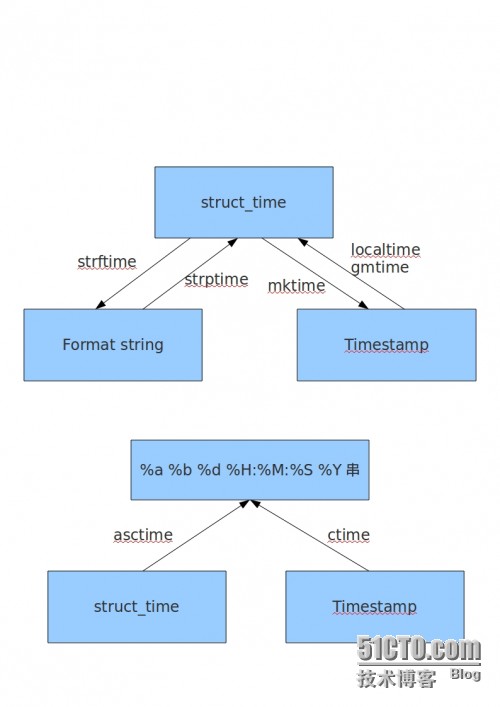
2 OS模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
3 random模块
示例
#!/usr/bin/env python
# encoding: utf-8
import random
import string
#随机整数:
print( random.randint(0,99)) #70
#随机选取0到100间的偶数:
print(random.randrange(0, 101, 2)) #4
#随机浮点数:
print( random.random()) #0.2746445568079129
print(random.uniform(1, 10)) #9.887001463194844
#随机字符:
print(random.choice('abcdefg&#%^*f')) #f
#多个字符中选取特定数量的字符:
print(random.sample('abcdefghij',3)) #['f', 'h', 'd']
#随机选取字符串:
print( random.choice ( ['apple', 'pear', 'peach', 'orange', 'lemon'] )) #apple
#洗牌#
items = [1,2,3,4,5,6,7]
print(items) #[1, 2, 3, 4, 5, 6, 7]
random.shuffle(items)
print(items) #[1, 4, 7, 2, 5, 3, 6]
生成随机验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print (checkcode)
4 sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
5 shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
d = shelve.open('shelve_test') #打开一个文件
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ["alex","rain","test"]
d["test"] = name #持久化列表
d["t1"] = t #持久化类
d["t2"] = t2
d.close()
6 logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
7 re模块
常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
'(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
8 hashlib模块
import hashlib
m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...")
print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass
def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass
'''
import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest())
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac
h = hmac.new('wueiqi')
h.update('hellowo')
print h.hexdigest()Python自动化之常用模块的更多相关文章
- Python自动化开发 - 常用模块(二)
本节内容 1.shutil模块 2.shelve模块 3.xml处理模块 4.configparser模块 5.hashlib模块 6.subprocess模块 7.re模块 一.shutil模块 高 ...
- Python自动化之常用模块学习
自动化常用模块 urllib和request模块学习笔记 '获取页面,UI自动化校验页面展示作用': #-*- coding : utf-8 -*-import urllib.requestimpor ...
- Python自动化开发 - 常用模块(一)
本节内容 1.模块介绍 2.time&datetime模块 3.random模块 4.os模块 5.sys模块 6.json&pickle模块 7.logging模块 一.模块介绍 模 ...
- python笔记之常用模块用法分析
python笔记之常用模块用法分析 内置模块(不用import就可以直接使用) 常用内置函数 help(obj) 在线帮助, obj可是任何类型 callable(obj) 查看一个obj是不是可以像 ...
- 十八. Python基础(18)常用模块
十八. Python基础(18)常用模块 1 ● 常用模块及其用途 collections模块: 一些扩展的数据类型→Counter, deque, defaultdict, namedtuple, ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- Python学习笔记-常用模块
1.python模块 如果你退出 Python 解释器并重新进入,你做的任何定义(变量和方法)都会丢失.因此,如果你想要编写一些更大的程序,为准备解释器输入使用一个文本编辑器会更好,并以那个文件替代作 ...
- Day5 - Python基础5 常用模块学习
Python 之路 Day5 - 常用模块学习 本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shel ...
- Python 五个常用模块资料 os sys time re built-in
1.os模块 os模块包装了不同操作系统的通用接口,使用户在不同操作系统下,可以使用相同的函数接口,返回相同结构的结果. os.name:返回当前操作系统名称('posix', 'nt', ' ...
随机推荐
- Zookeeper集群的安装和使用
Apache Zookeeper 由 Apache Hadoop 的 Zookeeper 子项目发展而来,现已经成为 Apache 的顶级项目,它是一个开放源码的分布式应用程序协调服务,是Google ...
- typedef和#define的用法与区别
typedef和#define的用法与区别 typedef和#define的用法与区别 一.typedef的用法 在C/C++语言中,typedef常用来定义一个标识符及关键字的别名,它是语言编译过程 ...
- Multiple sequence alignment Benchmark Data set
Multiple sequence alignment Benchmark Data set 1. 汇总: 序列比对标准数据集: http://www.drive5.com/bench/ This i ...
- How to get http response.
public class HttpWebResponseUtility { public static string CreateGetHttpResponse(string url) { var r ...
- aop测试jdk代理机制
//测试jdk代理机制 @Test public void testProxy(){ final UsbDisk usbDisk = new UsbDisk(); //类加载器,接口,匿名内部类 // ...
- Redis3.0.7 cluster/集群 安装配置教程
1.前言 环境:CentOS-6.7-i386-LiveDVD 安装的CentOs系统 节点: 6个节点,3个主节点.3个从节点(由于redis默认需要3个主节点,如果想每个主节点有一个从节点,这是最 ...
- Javabean+servlet+JSP(html)实例应用
大家都知道Javabean+servlet+JSP是最简单的MVC模式.的确,在一个小型的项目中,这个模式完全够用. 它优雅并且简洁.加上jQueryui的完美展示效果,让这个模式看起来非常合适.当然 ...
- PostgreSQL中的时间操作总结
取当前日期的函数: (1) 取当前时间:select now() (2) 取当前时间的日期: select current_date (3) 取当前具体时间(不含日 ...
- VTK初学一,a_Vertex图形点的绘制
系统:Win8.1 QT版本:2.4.2,Mingw VTK版本:6.3 2. main.cpp #ifndef INITIAL_OPENGL #define INITIAL_OPENGL #incl ...
- 新年新技术:HTTP/2
新的一年,项目也要带着发展的眼光往前走,得跟上潮流,当然前提是自己真的用的上. 用的上用不上都得先简单了解下. 2月下旬Google发布了首个基于HTTP/2的RPC框架GRPC,它是基于HTTP/2 ...