图解Storm
问题导读:
1.你认为什么图形可以显示hadoop与storm的区别?(电梯)
2.本文是如何形象讲解hadoop与storm的?(离线批量处理、实时流式处理)
3.hadoop map/reduce对应storm那两个概念?(spout/bolt)
4.storm流由谁来组成?(Tuples)
5.tuple具体是什么形式?
什么是Storm?
Storm是:
- 快速且可扩展伸缩
- 容错
- 确保消息能够被处理
- 易于设置和操作
- 开源的分布式实时计算系统
- 最初由Nathan Marz开发
- 使用Java 和 Clojure 编写
区别:
我们知道hadoop是批处理,storm是流式处理,那么是什么是批处理,什么流式处理?
Storm和Hadoop主要区别是实时和批处理的区别:
Storm概念组成:Spout和Bolt组成Topology。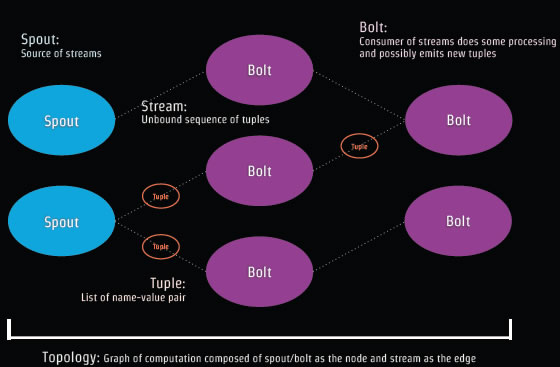
Tuple是Storm的数据模型,如['jdon',12346]
多个Tuple组成事件流: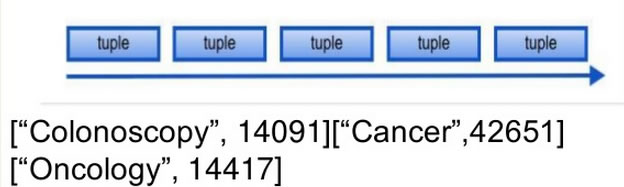
Spout是读取需要分析处理的数据源,然后转为Tuples,这些数据源可以是Web日志、 API调用、数据库等等。Spout相当于事件流的生产者。
Bolt 处理Tuples然后再创建新的Tuples流,Bolt相当于事件流的消费者。
Bolt 作为真正业务处理者,主要实现大数据处理的核心功能,比如转换数据,应用相应过滤器,计算和聚合数据(比如统计总和等等) 。
以Twitter的某个Tweet为案例,看看Storm如何处理: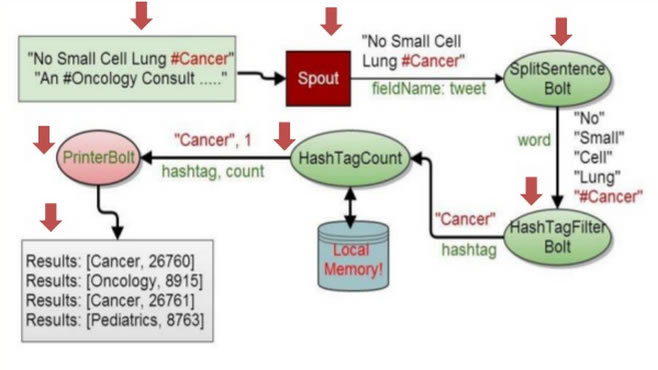
这些tweett贴内容是:“No Small Cell Lung #Cancer(没有小细胞肺癌#癌症)” "An #OnCology Consult...."
这些贴被Spout读取以后,产生Tuple,字段名是tweet,内容是"No Small Cell Lung #Cancer",格式类似:['No Small Cell Lung #Cancer',133221]。
然后进入被流 消费者Bolt进行处理,第一个Bolt是SplitSentence,将tuple内容进行分离,结果成为:一个个单词:"No" "Small" "Cell" "Lung" "#Cancer" ;然后经过第二个Bolt进行过滤HashTagFilter处理,Hash标签是单词中用#标注的,也就是Cancer;再经过HasTagCount计数,可以本地内存缓存这个计数结果,最后通过PrinterBolt打印出标签单词统计结果 。
我们使用Stom所要做的就是编制Spout和Bolt代码:
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector collector;
Random random;
//读入外部数据
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
random = new Random();
}
//产生Tuple
public void nextTuple() {
String[] sentences = new String[] {
"No Small Cell Lung #Cancer",
"An #OnCology Consultant apple a day keeps the doctor away",
"four score and seven years ago",
"snow white and the seven dwarfs",
"i am at two with nature"
};
String tweet = sentences[random.nextInt(sentences.length)];
//定义字段名"tweet" 的值
collector.emit(new Values(tweet));
}
// 定义字段名"tweet"
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
}
下面是Bolt的代码编写:
public class SplitSentenceBolt extends BaseRichBolt {
OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override 消费者激活主要方法:分离成单个单词
public void execute(Tuple input) {
for (String s : input.getString(0).split("\\s")) {
collector.emit(new Values(s));
}
}
@Override 定义新的字段名
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
最后是装配运行Spout和Bolt的客户端调用代码:
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("tweet", new RandomSentenceSpout(), 2);
builder.setBolt("split", new SplitSentenceBolt(), 4)
.shuffleGrouping("tweet")
.setNumTasks(8);
builder.setBolt("count", new WordCountBolt(), 6)
.fieldsGrouping("split", new Fields("word"));
..设置多个Bolt
Config config = new Config();
config.setNumWorkers(4);
StormSubmitter.submitTopology("wordcount", config, builder.createTopology());
//Local testing
//LocalCluster cluster = new LocalCluster();
//cluster.submitTopology("wordcount", config, builder.createTopology());
//Thread.sleep(10000);
//cluster.shutdown();
}
}
在这个代码中定义了一些参数比如Works的数目是4,其含义在后面详细分析。
下面我们要将上面这段代码发布部署到Storm中,首先了解Storm物理架构图: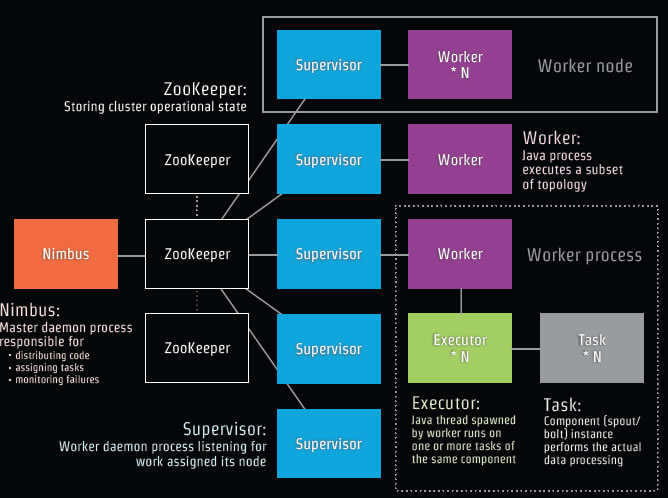
Nimbus是一个主后台处理器,主要负责:
1.发布分发代码
2.分配任务
3.监控失败。
Supervisor是负责当前这个节点的后台工作处理器的监听。
Work类似Java的线程,采取JDK的Executor 。
下面开始将我们的代码部署到这个网络拓扑中: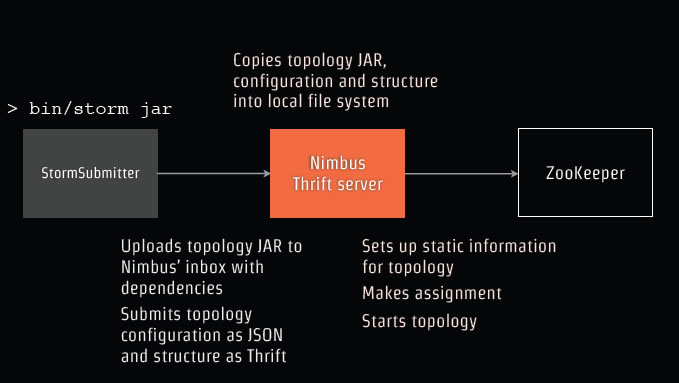 将代码Jar包上传到Nimbus的inbox,包括所有的依赖包,然后提交。
将代码Jar包上传到Nimbus的inbox,包括所有的依赖包,然后提交。
Nimbus将保存在本地文件系统,然后开始配置网络拓扑,分配开始拓扑。
见下图: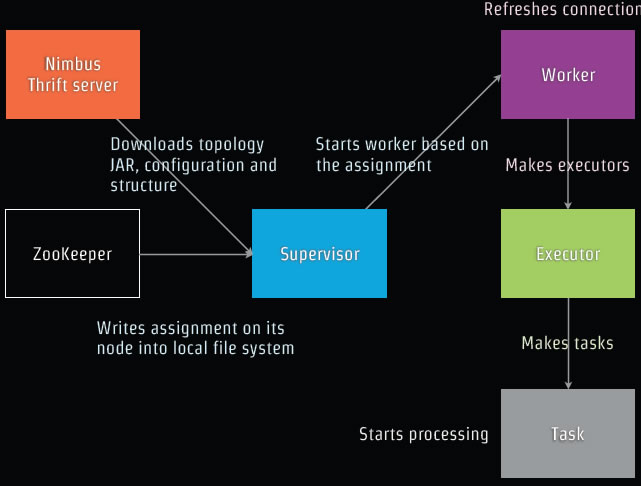 Nimbus服务器将拓扑Jar 配置和结构下载到 Supervisor,负载平衡ZooKeeper分配某个特定的Supervisor服务器,而Supervisor开始基于配置分配Work,Work调用JDK的Executor启动线程,开始任务处理。
Nimbus服务器将拓扑Jar 配置和结构下载到 Supervisor,负载平衡ZooKeeper分配某个特定的Supervisor服务器,而Supervisor开始基于配置分配Work,Work调用JDK的Executor启动线程,开始任务处理。
下面是我们代码对拓扑分配的参数示意图:
Executor启动的线程数目是12个,组件的实例是16个,那么如何在实际服务器中分配呢?如下图: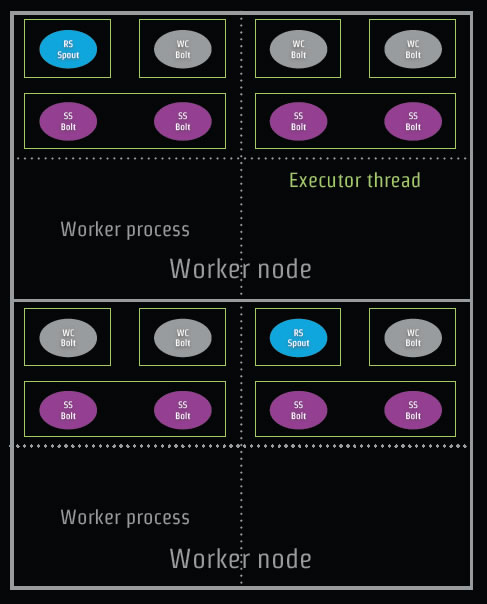 图中RsSpout代表我们的代码中RandomSentenceSpout;SplitSentenceBolt简写为SSbolt。
图中RsSpout代表我们的代码中RandomSentenceSpout;SplitSentenceBolt简写为SSbolt。
图解Storm的更多相关文章
- storm集群的安装
storm图解 storm的基本概念 Topologies:拓扑,也俗称一个任务 Spoults:拓扑的消息源 Bolts:拓扑的处理逻辑单元 tuple:消息元组,在Spoults和Bolts传递数 ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- 图解CSS3制作圆环形进度条的实例教程
圆环形进度条制作的基本思想还是画出基本的弧线图形,然后CSS3中我们可以控制其旋转来串联基本图形,制造出部分消失的效果,下面就来带大家学习图解CSS3制作圆环形进度条的实例教程 首先,当有人说你能不能 ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
- 理解Storm并发
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 注:本文主要内容翻译自understanding-the-parall ...
随机推荐
- Swift - 2.3的代码到3.0的转变
分享一下学习新语法的技巧:用Xcode8打开自己的Swift2.3的项目,选择Edit->Convert->To Current Swift Syntax- 让Xcode帮我们把Swift ...
- htnl中的遮罩层以及定位方式
在页面显示遮罩层,例如:一个div的css样式: $msk.css({ "top":"0", "left":"0", & ...
- 有关Oracle数据库
创建数据库(DCA):http://jingyan.baidu.com/article/cbcede07cf42ef02f40b4dc2.html 创建表(连接数据库,sql创建数据表):http:/ ...
- CLR via C#(11)-无参属性、有参数属性(索引器)
一. 无参属性 1. 定义属性 无参属性就是我们最常见的属性方式,在赋值时可以加入一定的逻辑判断.属性的定义其实不复杂,先看个直观的例子: 说明: 属性要定义名称和类型,且类型不能是void. 属性是 ...
- sdut 487-3279【哈希查找,sscanf ,map】
487-3279 Time Limit: 2000ms Memory limit: 65536K 有疑问?点这里^_^ 题目描述 题目链接: sdut: http://acm.sdut.ed ...
- Oracle数据库 控制文件
一.概念控制文件的主要任务是管理数据库的状态以及描述数据库的物理结构 二.所含有的信息1.数据库名2.数据库标识符(DBID)3.数据库创建时间戳4.数据库字符集5.数据文件信息6.临时文件信息7.在 ...
- PHP+MYSQL+AJAX实现每日签到功能
一.web前端及ajax部分 文件index.html <html> <head> <meta http-equiv=Content-Type content=" ...
- 第十八篇:在SOUI中实现PreTranslateMessage
在MFC中,通常可以通过重载CWnd::PreTranslateMessage这样一个虚函数来实现对一些窗口消息的预处理.多用于tooltip的显示控制. 在SOUI中也实现了类似的机制. 要在SOU ...
- 遍历CallBack对象 和 HHIVE对象
内核中有个PLIST_ENTRY CmpHiveListHead;CmpHiveListHead = &CMHIVE.HiveList; CMHIVE结构如下:kd> dt _CMHIV ...
- Strust2 初体验
Struts2的第一个案例 首先我们需要引入架包 entity: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package ...