大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一、并行机制
Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力。
1.组件关系:
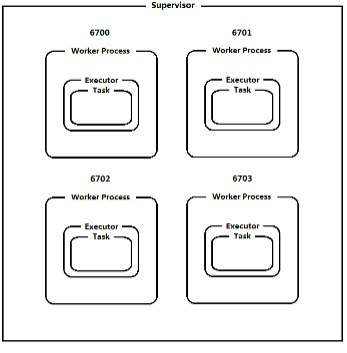
Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor.slots.ports数量;
worker:工作进程,即jvm.为特定拓扑的一个或者多个组件Spout/Bolt产生一个或者多个Executor。默认情况下一个Worker运行一个Executor
Executor:线程Thread,为特定拓扑的一个或者多个组件Spout/Bolt实例运行一个或者多个Task。默认情况下一个Executor运行一个Task。
Task:任务
2.代码配置并行度
//工作进程Worker数量
Config config = new Config();
config.setNumWorkers(3); //注意此参数不能大于supervisor.slots.ports数量。 //执行器Executor数量 线程数量
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(id, spout, parallelism_hint); //设置Spout的Executor数量参数parallelism_hint
builder.setBolt(id, bolt, parallelism_hint); //设置Bolt的Executor数量参数parallelism_hint //任务Task数量 指定任务数 会平均分配到执行器里
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(id, spout, parallelism_hint).setNumTasks(val); //设置Spout的Executor数量参数parallelism_hint,Task数量参数val
builder.setBolt(id, bolt, parallelism_hint).setNumTasks(val); //设置Bolt的Executor数量参数parallelism_hint,Task数量参数val
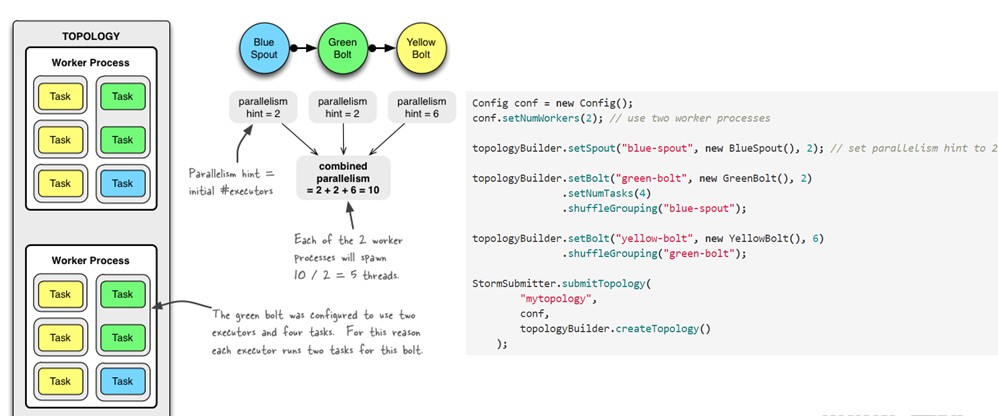
图解并行度:
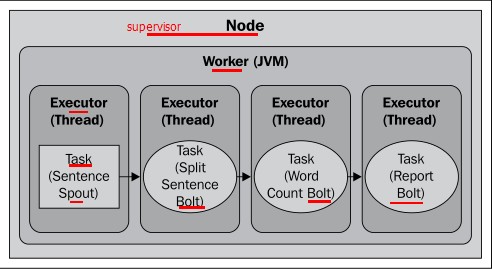
2.1 默认1个worker,1个Executor,1个task
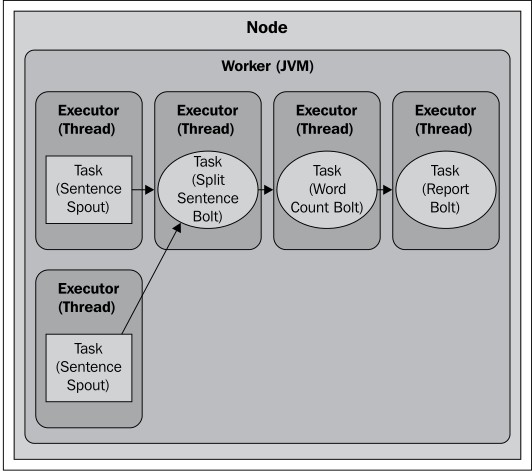
2.2 spout 设置并行度2
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
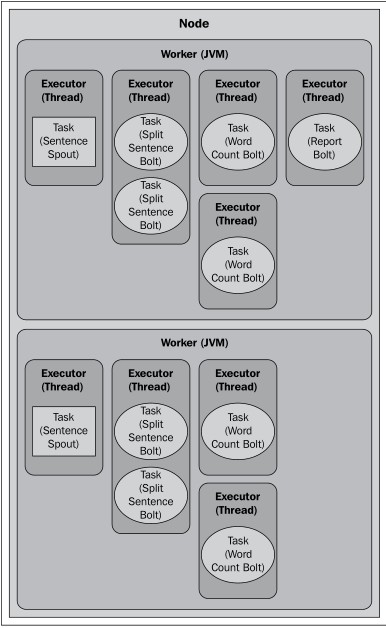
2.3 设置多worker 多并行度,多任务
#设置两个worker
Config config = new Config();
config.setNumWorkers(2);
#splitBolt并行度2,任务数4
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
#splitBolt并行度4
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, newFields("word"));
3.并行度再平衡
使用storm命令或者storm UI 操作
# 重新配置拓扑
# -w 设置10秒超时时间
# -n “myTopology” 拓扑使用5个Worker进程
# -e “blue-spout” Spout使用3个Executor
# -e “yellow-blot” Bolt使用10个Executor
storm rebalance myTopology -w 10 -n -e blue-spout= -e yellow-blot=
附示例:
二、通信机制:
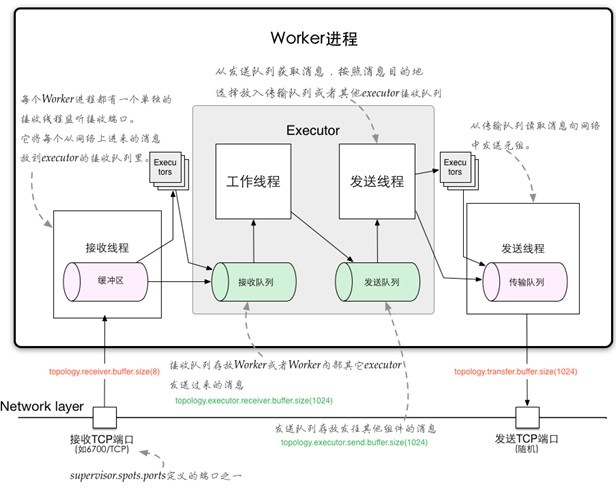
1、Worker进程间的数据通信
ZMQ
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty
Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
2、Worker内部的数据通信
Disruptor
实现了“队列”的功能。
可以理解为一种事件监听或者消息处理机制,即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理。
参考:
Storm拓扑的并行度(parallelism)
大数据处理框架之Strom: Storm拓扑的并行机制和通信机制的更多相关文章
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- 大数据处理框架之Strom:redis storm 整合
storm 引入redis ,主要是使用redis缓存库暂存storm的计算结果,然后redis供其他应用调用取出数据. 新建maven工程 pom.xml <project xmlns=&qu ...
- 大数据处理框架之Strom:kafka storm 整合
storm 使用kafka做数据源,还可以使用文件.redis.jdbc.hive.HDFS.hbase.netty做数据源. 新建一个maven 工程: pom.xml <project xm ...
- 大数据处理框架之Strom:DRPC
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 一.DRPC DRPC:Distri ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
- 大数据处理框架之Strom:事务
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
随机推荐
- 洛谷P3567 KUR-Couriers [POI2014] 主席树/莫队
正解:主席树/莫队 解题报告: 传送门! 这题好像就是个主席树板子题的样子,,,? 毕竟,主席树的最基本的功能就是,维护一段区间内某个数字的个数 但是毕竟是刚get到主席树,然后之前做的一直是第k大, ...
- mysql from dual插入实现不插入重复记录
在mysql中插入一或者多条记录的时候,要求某个字段的值唯一,但是该字段没有添加唯一性索引,可用from dual解决. select * from (select '2015080109' a,2 ...
- WordPress禁用插件另类方法不用进后台
刚刚一小美女说她在WordPress后台启用了一个插件后出现了问题,网站前端和后端都不能打开了,ytkah查看了一下是有个插件api和另一个插件冲突了,但要怎么禁用呢?有两个办法可以解决 1.直接删除 ...
- laravel用crud修改产品items-新建resource controller和routing
前面我们创建了laravel简单的items产品api,但是需要在数据库添加,如何在网页上直接添加呢?我们可以用view来操作crud(增加Create.读取查询Retrieve.更新Update和删 ...
- 011-docker-安装-rabbitmq-management:3.7.13
1.搜索镜像 docker search rabbitmq 2.拉取合适镜像 选择合适tag:https://hub.docker.com/,下载3.7.13 带web管理界面版本 docker pu ...
- react 脚手架--create-react-app
1.yarn add -g create-react-app 2.create-react-app demo cd demo yarn start 可以跑起来整个项目了 一般都会用到路由,需要 yar ...
- webstorm2018版安装-破解
安装完成后到下面网址下载破解补丁 网址:http://idea.lanyus.com/ 修改路径 修改同目录下的 WebStorm.exe.vmoptions 和WebStorm64.exe.vmop ...
- 万恶之源 - Python迭代器
函数名的使用以及第一类对象 函数名的运用 函数名是一个变量, 但它是一个特殊的变量, 与括号配合可以执行函数的变量 1.函数名的内存地址 def func(): print("呵呵" ...
- Spark log4j日志配置详解(转载)
一.spark job日志介绍 spark中提供了log4j的方式记录日志.可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 l ...
- 如何创建线程第一种继承Thread类
步骤 1:定义一个类 继承Thread类.2:重写Thread类的run方法.3:直接创建Thread的子类对象创建线程.4:调用start方法开启线程并调用线程的任务run方法执行.-------- ...