mapreduce压缩
这是mr的一种优化策略,通过压缩编码对mapper或者reducer的输出进行压缩,以减少磁盘io,提高mr运行速度(但也相应增加了cpu运算负担)
特性:
1.mr支持将map输出的结果或者reduce输出的结果进行压缩,以减少网络IO或最终输出数据的体积。
2.压缩特性使用得当能提高性能,但运用不当也可降低性能。
3.基本原则:
运算密集型的job,少用压缩
io密集型的job,多用压缩
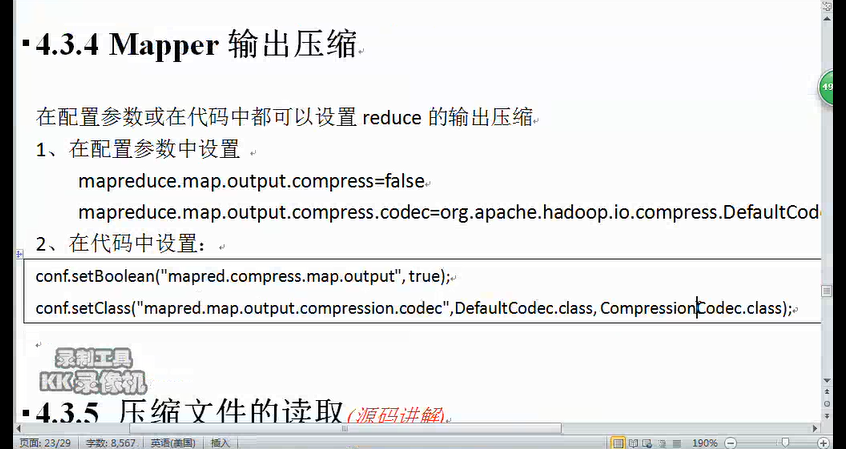
也可以设置map端的输出压缩。


mapreduce压缩的更多相关文章
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
- 第2节 mapreduce深入学习:14、mapreduce数据压缩-使用snappy进行压缩
第2节 mapreduce深入学习:14.mapreduce数据压缩-使用snappy进行压缩 文件压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输. 方式一:在代码中进行设置压缩 代码: ...
- Hadoop权威指南:压缩
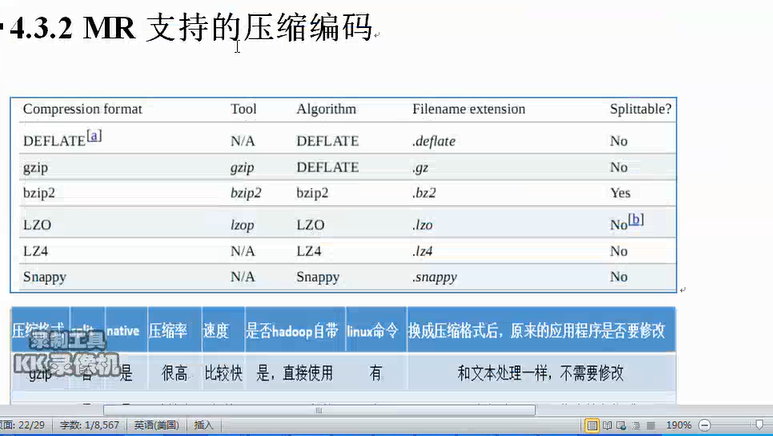
Hadoop权威指南:压缩 [TOC] 文件压缩的两个好处: 减少储存文件所需要的磁盘空间 加速数据在网络和磁盘上的传输 压缩格式总结: 压缩格式 工具 算法 文件扩展名 是否可切分 DEFLATE ...
- Hive中的HiveServer2、Beeline及数据的压缩和存储
1.使用HiveServer2及Beeline HiveServer2的作用:将hive变成一种server服务对外开放,多个客户端可以连接. 启动namenode.datanode.resource ...
- 【Hadoop离线基础总结】MapReduce增强(下)
MapReduce增强(下) MapTask运行机制详解以及MapTask的并行度 MapTask运行流程 第一步:读取数据组件InputFormat(默认TextInputFormat)会通过get ...
- 一文彻底搞懂Hive的数据存储与压缩
目录 行存储与列存储 行存储的特点 列存储的特点 常见的数据格式 TextFile SequenceFile RCfile ORCfile 格式 数据访问 Parquet 测试 准备测试数据 存储空间 ...
- parquet和orc选型以及压缩格式
Hive表压缩功能 除了直接配置MapReduce压缩功能外,Hive的ORC表和Parquet表直接支持表的压缩属性. 但支持的压缩格式有限,ORC表支持None.Zlib.Snappy压缩,默认为 ...
- 3.2-3.3 Hive中常见的数据压缩
一.数据压缩 1. 数据压缩 数据量小 *本地磁盘,IO *减少网络IO Hadoop作业通常是IO绑定的; 压缩减少了跨网络传输的数据的大小; 通过简单地启用压缩,可以提高总体作业性能; 要压缩的数 ...
- Hadoop-No.3之序列化存储格式
序列化存储指的是将数据结构转化为字节流的过程,一般用于数据存储或者网络传输.与之相反, 反序列化是将字节流转化为数据结果的过程.序列化是分布处理系统(比如Hadoop)的核心,原因在于他能对数据进行转 ...
- Hadoop知识总结
------------恢复内容开始------------ Hadoop知识点 Hadoop知识点什么是HadoopHadoop和Spark差异Hadoop常见版本,有哪些特点,一般是如何进行选择H ...
随机推荐
- node.js环境在Window和Mac中配置,以及安装cnpm和配置Less环境
Node.js 和cnpm安装 最近准备学习vue.js,但首先需要配置电脑的环境.配置node.js. 1.在node(https://nodejs.org/en/)官网上下载安装node.js,两 ...
- Oracle中ALTER TABLE的五种用法(一)
首发微信公众号:SQL数据库运维 原文链接:https://mp.weixin.qq.com/s?__biz=MzI1NTQyNzg3MQ==&mid=2247485212&idx=1 ...
- ECMAScript 语言规范每年都会进行一次更新,而备受期待的 ECMAScript 2024 将于 2024 年 6 月正式亮相。目前,ECMAScript 2024 的候选版本已经发布,为我们带来了一系列实用的新功能。
Promise.withResolvers 使用 Promise.withResolvers() 关键的区别在于解决和拒绝函数现在与 Promise 本身处于同一作用域,而不是在执行器中被创建和一次性 ...
- 关于URP14绘制全屏Blit后处理的改动
最近用回URP,发现RendererFeature这部分改动很大,启用了之前HDRP的RTHandle,RTHandle的设计类似于优化版本的RenderTexture, 可以统一控制缩放或者并非一对 ...
- C数据结构:哈夫曼树算法实现与应用
学习哈夫曼树(编码) 带权二叉树 认识WPL 最优二叉树 构造哈夫曼树的过程 哈夫曼树的应用 建立哈夫曼树 代码如下: 结构体代码部分 建立操作代码 找到最小结点(※难点) 附上建立哈夫曼树源代码 带 ...
- 物联网平台选型葵花宝典:盘点开源、SaaS及通用型平台的优劣对比
随着工业物联网领域和智慧物联领域的发展,大大小小的物联项目和物联场景需求层出不穷,物联网平台作为技术底座型软件,是不可或缺的项目地基. 市场需求下,物联网平台提供商越来越多,"打地基&quo ...
- 基于FPGA的数字钟设计---第三版
欢迎各位朋友关注"郝旭帅电子设计团队",本篇为各位朋友介绍基于FPGA的数字钟设计---第三版. 功能说明: 1. 在数码管上面显示时分秒(共计六个数码管,前两个显示小时:中间两个 ...
- mysql-8.4.0解压版安装记录
MySQL 8.4.0解压版安装记录 这几天,安装最新版mysql 8.4的时候,遇到了不少问题,网上的教程大多数都是旧版本的,也安装不成功. 参考了大量教程后,经过自己的摸索终于装好了,这里记录一下 ...
- Kubernetes 数据存储:从理论到实践的全面指南
本文深入解析 Kubernetes (K8S) 数据存储机制,探讨其架构.管理策略及最佳实践.文章详细介绍了 K8S 数据存储的基础.架构组成.存储卷管理技巧,并通过具体案例阐述如何高效.安全地管理数 ...
- FFmpeg开发笔记(二十三)使用OBS Studio开启RTMP直播推流
OBS是一个开源的直播录制软件,英文全称叫做Open Broadcaster Software,广泛用于视频录制.实时直播等领域.OBS不但开源,而且跨平台,兼容Windows.Mac OS.Lin ...