莫烦tensorflow学习记录 (4)Classification 分类学习
MNIST 数据
首先准备数据(MNIST库)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
一个谷歌提供的手写数据库,数据中包含55000张训练图片,每张图片的分辨率是28×28,所以我们的训练网络输入应该是28×28=784个像素数据。
搭建网络
from __future__ import print_function
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) def add_layer(inputs,in_size,out_size,activation_function=None): #定义添加神经层的函数def add_layer(),它有四个参数:输入值、输入的大小、输出的大小和激励函数,我们设定默认的激励函数是None。
Weights = tf.Variable(tf.random_normal([in_size,out_size]))
biases = tf.Variable(tf.zeros([1,out_size])+ 0.1) #机器学习中推荐biases不为0,所以加个0.1
#定义Wx_plus_b, 即神经网络未激活的值。其中,tf.matmul()是矩阵的乘法。
Wx_plus_b = tf.matmul(inputs, Weights) + biases
#当activation_function——激励函数为None时,输出就是当前的预测值——Wx_plus_b,不为None时,就把Wx_plus_b传到activation_function()函数中得到输出。
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs # 计算精度函数,利用测试集来测试
def compute_accuracy(v_xs,v_ys):
global prediction # 将输出定义为全局变量
y_pre = sess.run(prediction, feed_dict={xs: v_xs}) # v_xs 进入到preduction里面计算y的预测值
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1)) # 预测值与测试集的y值对比
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 统计对比结果
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
return result # 为网络输入定义占位符
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28,图片有784个像素点
ys = tf.placeholder(tf.float32, [None, 10]) # 每张图片都表示一个数字,所以我们的输出是数字0到9,共10类。 # 神经网络
l1 = add_layer(xs,784,150,activation_function=tf.nn.tanh)
prediction = add_layer(l1,150,10,activation_function=tf.nn.softmax) # 损失函数,预测与实际数据之间的误差
# loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,
# 如果完全相同,它们的交叉熵等于零。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1])) #loss # 训练步骤
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) # # 初始化变量
init = tf.global_variables_initializer() # 上面所有的都还没有运行
sess = tf.Session()
sess.run(init) # 这里运行了init for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100) #现在开始train,每次只取100张图片,免得数据太多训练太慢。
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys})
if i%50==0:
print(compute_accuracy(
mnist.test.images,mnist.test.labels
))
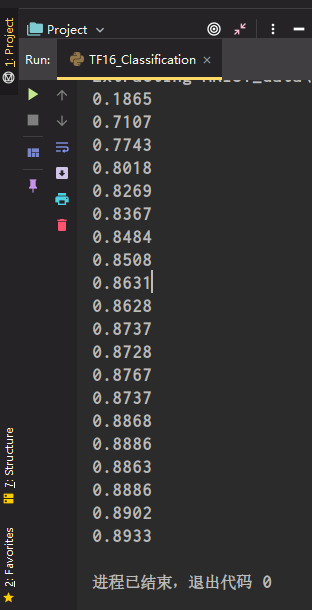
运行结果
莫烦tensorflow学习记录 (4)Classification 分类学习的更多相关文章
- TensorFlow基础笔记(3) cifar10 分类学习
TensorFlow基础笔记(3) cifar10 分类学习 CIFAR-10 is a common benchmark in machine learning for image recognit ...
- TensorFlow基础笔记(2) minist分类学习
(1) 最简单的神经网络分类器 # encoding: UTF-8 import tensorflow as tf from tensorflow.examples.tutorials.mnist i ...
- 莫烦tensorflow(9)-Save&Restore
import tensorflow as tfimport numpy as np ##save to file#rember to define the same dtype and shape w ...
- 莫烦tensorflow(8)-CNN
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data#number 1 to 10 dat ...
- 莫烦tensorflow(7)-mnist
import tensorflow as tffrom tensorflow.examples.tutorials.mnist import input_data#number 1 to 10 dat ...
- 莫烦tensorflow(6)-tensorboard
import tensorflow as tfimport numpy as np def add_layer(inputs,in_size,out_size,n_layer,activation_f ...
- 莫烦tensorflow(5)-训练二次函数模型并用matplotlib可视化
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as plt def add_layer(inputs,in_siz ...
- 莫烦tensorflow(4)-placeholder
import tensorflow as tf input1 = tf.placeholder(tf.float32)input2 = tf.placeholder(tf.float32) outpu ...
- 莫烦tensorflow(3)-Variable
import tensorflow as tf state = tf.Variable(0,name='counter') one = tf.constant(1) new_value = tf.ad ...
- 莫烦tensorflow(2)-Session
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' import tensorflow as tfmatrix1 = tf.constant([[3,3] ...
随机推荐
- 构建RAG应用-day01: 词向量和向量数据库 文档预处理
词向量和向量数据库 词向量(Embeddings)是一种将非结构化数据,如单词.句子或者整个文档,转化为实数向量的技术. 词向量搜索和关键词搜索的比较 优势1:词向量可以语义搜索 比如百度搜索,使用的 ...
- Crazy Excel:Excel中的泥石流
Crazy Excel又名:疯狂Excel.是一款PC端的Excel软件工具,该软件支持windows, mac os等主流操作系统. 正如其名,作者在设计之初就加入了一些疯狂的设计,目的是创作出更加 ...
- linux系统关闭指定端口
linux系统关闭指定端口 关闭指定端口 firewall-cmd --zone=public --remove-port=80/tcp --permanent systemctl restart f ...
- 【笔记】Oracle union all&for update锁
[笔记]Oracle union all&for update union all 在Oracle中有三种类型的集合操作 UNION:求并,重复记录只显示一次 UNION ALL:求并集,显示 ...
- 力扣1662(java&python)-检查两个字符串数组是否相等(简单)
题目: 给你两个字符串数组 word1 和 word2 .如果两个数组表示的字符串相同,返回 true :否则,返回 false . 数组表示的字符串 是由数组中的所有元素 按顺序 连接形成的字符串. ...
- 力扣551(java)-学生出勤记录Ⅰ(简单)
题目: 给你一个字符串 s 表示一个学生的出勤记录,其中的每个字符用来标记当天的出勤情况(缺勤.迟到.到场).记录中只含下面三种字符: 'A':Absent,缺勤'L':Late,迟到'P':Pres ...
- 手把手教你PolarDB-X中的表设计——用户表
简介: 本系列旨在描述一个具体的业务场景,给出建表的例子,帮助大家更好的使用PolarDB-X.本期的主题是:用户表. 本系列旨在描述一个具体的业务场景,给出建表的例子,帮助大家更好的使用PolarD ...
- OPLG:新一代云原生可观测最佳实践
简介:OPLG 体系拥有成熟且富有活力的开源社区生态,同时也经过了大量企业生产环境的实践检验,是当下建设新一代云原生统一可观测平台的热门选择.但是,OPLG 只是提供了一个技术体系,如何灵活运用,解 ...
- 【详谈 Delta Lake 】系列技术专题 之 特性(Features)
简介: 本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 的系列技术文章.众所周知,Databricks 主导着开源大数据社区 Apache Spark.Delta L ...
- Flink 1.13,面向流批一体的运行时与 DataStream API 优化
简介: 在 1.13 中,针对流批一体的目标,Flink 优化了大规模作业调度以及批执行模式下网络 Shuffle 的性能,以及在 DataStream API 方面完善有限流作业的退出语义. 本文由 ...