【matplotlib 实战】--堆叠柱状图
堆叠柱状图,是一种用来分解整体、比较各部分的图。
与柱状图类似,堆叠柱状图常被用于比较不同类别的数值。而且,它的每一类数值内部,又被划分为多个子类别,这些子类别一般用不同的颜色来指代。
柱状图帮助我们观察“总量”,堆叠柱状图则可以同时反映“总量”与“结构”。
也就是说,堆叠柱状图不仅可以反映总量是多少?还能反映出它是由哪些部分构成的?
进而,我们还可以探究哪一部分比例最大,以及每一部分的变动情况,等等。
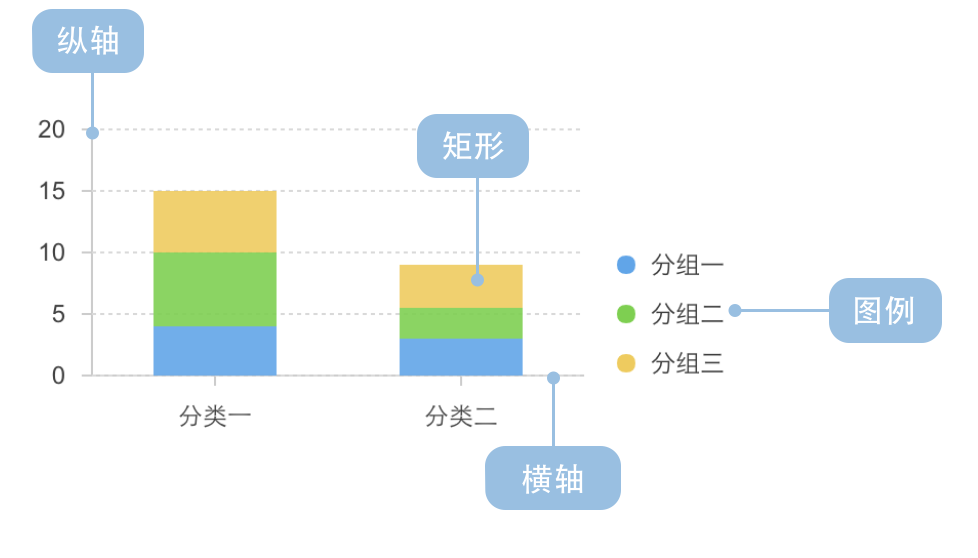
1. 主要元素
堆叠柱状图是常用于比较多个类别或组之间的数据。
它通过将多个柱状图堆叠在一起,展示每个类别或组的总量以及各个部分的相对比例。
它的主要构成元素包括:
- 横轴:表示数据的主分类。
- 纵轴:每个子分类的比例关系。
- 堆叠的矩形:每个柱状图由多个堆叠部分组成,每个堆叠部分表示该类别或组中的一个部分或子类别。
- 图例:每个堆叠部分代表的意义。
2. 适用的场景
堆叠柱状图适用于以下的分析场景:
- 比较多个类别或组的总量以及各个部分的相对比例,例如不同产品的销售总额以及各个渠道的销售额占比。
- 可视化多个类别或组的趋势变化,例如不同地区的人口数量随时间的变化趋势。
- 对比多个类别或组之间的差异,例如不同年份的营业额对比。
3. 不适用的场景
堆叠柱状图不适用以下的分析场景:
- 数据具有负值或包含缺失值的情况。堆叠柱状图只适用于展示正值数据,不适合包含负值或缺失值的数据。
- 需要比较多个类别的绝对数值大小。堆叠柱状图主要关注各个部分的相对比例,而不是绝对数值大小的比较。
4. 分析实战
本次用堆叠柱状图统计最近几年全国居民消耗的主要几类粮食的情况。
4.1. 数据来源
数据来自国家统计局公开的人民生活数据,可从下面的网址下载:
https://databook.top/nation/A0A
使用的是其中 A0A0A.csv文件(全国居民主要食品消费量)
fp = "d:/share/A0A0A.csv"
df = pd.read_csv(fp)
df
4.2. 数据清理
本次绘制堆叠柱状图,时间上选择最近几年的数据,由于2022年的数据缺失,选择** 2013年~2021年的数据。
内容上每个年度选择5类**常见的食物:
- 居民人均蔬菜及食用菌消费量(千克)
- 居民人均肉类消费量(千克)
- 居民人均禽类消费量(千克)
- 居民人均水产品消费量(千克)
- 居民人均蛋类消费量(千克)
#> A0A0A03 居民人均蔬菜及食用菌消费量(千克)
#> A0A0A04 居民人均肉类消费量(千克)
#> A0A0A05 居民人均禽类消费量(千克)
#> A0A0A06 居民人均水产品消费量(千克)
#> A0A0A07 居民人均蛋类消费量(千克)
data = df[(df["sj"] >= 2013) &
(df["sj"] <= 2021) &
(df["zb"].isin(["A0A0A03",
"A0A0A04",
"A0A0A05",
"A0A0A06",
"A0A0A07"]))].copy()
data.head(10)
一共45条数据,5个分类,每个分类有9个年度的数据。
4.3. 分析结果可视化
data = data.sort_values("sj")
data[data["zb"] == "A0A0A03"]["value"].tolist()
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
years = data["sjCN"].drop_duplicates(keep="first").tolist()
bar_data = {
"蔬菜及菌类(千克)": data[data["zb"] == "A0A0A03"]["value"].tolist(),
"肉类(千克)": data[data["zb"] == "A0A0A04"]["value"].tolist(),
"禽类(千克)": data[data["zb"] == "A0A0A05"]["value"].tolist(),
"水产品(千克)": data[data["zb"] == "A0A0A06"]["value"].tolist(),
"蛋类(千克)": data[data["zb"] == "A0A0A07"]["value"].tolist(),
}
bottom = np.zeros(len(years))
for key, vals in bar_data.items():
ax.bar(years, vals, label=key, bottom=bottom)
bottom += vals
ax.set_title("全国居民主要粮食消耗情况")
ax.legend(loc="upper left", ncol=3)
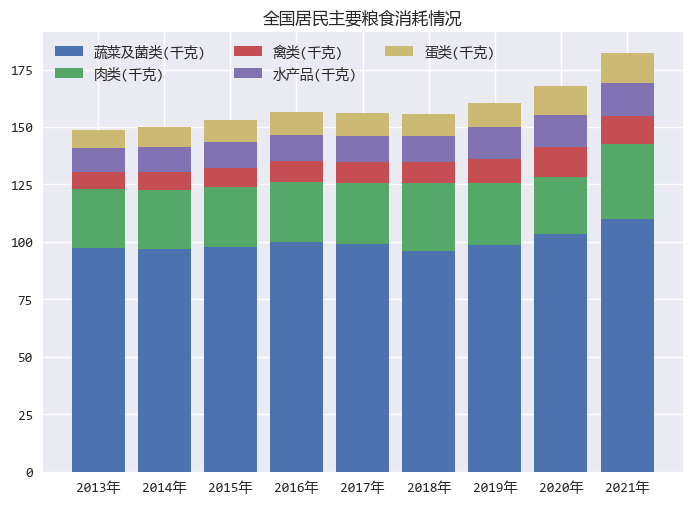
看图中的分析结果,和事先预想的差不多,蔬菜和肉类是我们平时主要的粮食来源。
图中还可以看出,在3年疫情期间,粮食消耗逐步增多,可能是大家认为吃的好才能增强抵抗力 :)
【matplotlib 实战】--堆叠柱状图的更多相关文章
- [Python Study Notes]堆叠柱状图绘制
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ...
- matplotlib实现三维柱状图
matplotlib实现三维柱状图 import cv2 img = cv2.imread("1.png", 0) #特征点在图片中的坐标位置 m = 448 n = 392 im ...
- echarts 堆叠柱状图 + 渐变柱状图
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- echarts堆叠柱状图在最上面的柱子显示总和
需求 柱子需设置barMinHeight 在堆叠柱状图的最上面显示当前堆叠的总和 直接上代码吧 需要注意:设置barMinHeight时为了让0不显示,只能将0设置为null; 设置为null的柱子l ...
- python之 matplotlib模块之绘制堆叠柱状图
我们先来看一个结果图 看到这个图,我个人的思路是 1 设置标题 import numpy as np import matplotlib.pyplot as plt plt.title('Scores ...
- 机器学习-Matplotlib绘图(柱状图,曲线图,点图)
matplotlib 作为机器学习三大剑客之一 ,比热按时无比强大的 matplotlib是绘图库,所以呢我就分享一下简单的绘图方式 #柱状图 #导报 柱状图 import matplotlib. ...
- 使用matplotlib 制图(柱状图、箱型图)
柱状图: import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv('D:\\myfiles\\study\\pyt ...
- Python之Matplot——01.堆叠柱状图的绘制
1.Matplotlib是python的一个绘图库,可以方便的绘制各种图标,是数据可视化的利器. 2.本文我就给大家介绍一下条形图或者说柱状图的绘制 3.代码如下: <1>首先导入模块 1 ...
- matplotlib画堆叠条形图
import matplotlib.pyplot as plt%matplotlib inlineplt.style.use('ggplot') plt.style.use("ggplot& ...
- ECharts动态加载堆叠柱状图的实例
一.引入echarts.js文件(下载页:http://echarts.baidu.com/download.html) 二.HTML代码: <div style="width: 10 ...
随机推荐
- React后台管理系统07 首页布局
注释掉App.tsx中的几个路由组件: 将Home.tsx中的代码使用ant Design网站中的布局进行替换 复制的代码如下: import { DesktopOutlined, FileOutli ...
- 讯飞离线语音合成新版(Aikit)-android sdk合成 demo(Java版本)
前言:科大讯飞的新版离线语音合成,由于官网demo是kt语言开发的,咱也看不懂kt,搜遍了全网也没看到一个java版的新版离线语音demo,现记录下,留给有缘人参考!!!!!毕竟咱在这上面遇到了不少的 ...
- Idea报错:无法创建java虚拟机
报错如下: 我怀疑是在配置algo4环境时,将系统变量改变了 于是我又重新配置了一下环境变量 然后运行 cmd 执行 java -version 还是报错 <JAVA_HOME>/lib/ ...
- 4.10 x64dbg 反汇编功能的封装
LyScript 插件提供的反汇编系列函数虽然能够实现基本的反汇编功能,但在实际使用中,可能会遇到一些更为复杂的需求,此时就需要根据自身需要进行二次开发,以实现更加高级的功能.本章将继续深入探索反汇编 ...
- “easyExcel”导入的代码实现
使用easyExcel在导入数据事有很好的使用性,方便操作. 添加依赖: <dependency> <groupId>com.alibaba</groupId> & ...
- 《逆向工程核心原理》之DLL注入
DLL注入 DLL注入指的是向运行中的其他进程强制插入特定的DLL文件.从技术细节来说,DLL注入命令其他进程自行调用LoadLibrary() API,加载(Loading)用户指定的DLL文件.D ...
- GaussDB技术解读丨高级压缩
本文作者|华为云数据库GaussDB首席架构师 冯柯 [背景介绍] 数据压缩与关系数据库的结合,早已不是一个新鲜的话题,当前我们已经看到了各种各样数据库压缩的产品和解决方案.对于GaussDB来说,在 ...
- 树莓派使用Golang+MQ135检测室内空气质量
MQ135是一个比较便宜的空气质量传感器,可以用在家庭以及工业场所中.树莓派是一个小巧但很强大的卡片电脑,基于Linux,同时提供了很多硬件接口,方便开发出各种电子产品.Golang是一款简单高效 ...
- Swithch反汇编(四种)
------------恢复内容开始------------ Switch语法格式 Switch(表达式) { case 常量表达式1: 语句; break; case 常量表达式2: 语句; bre ...
- eclipse module-info.java文件
module 本模块的名称{ exports 对外暴露的包路径; requires 需要依赖的其他模块名称; } module-info.java不是类,不是接口,是一些模块描述信息.module也不 ...