一致性hash算法原理及实践
大家好,我是蓝胖子,想起之前学算法的时候,常常只知表面,不得精髓,这个算法到底有哪些应用场景,如何应用在工作中,后来随着工作的深入,一些不懂的问题才慢慢被抽丝剥茧分解出来。
今天我们就来看看工作和面试中经常被点名的算法,一致性hash算法,并且我会介绍它在实际的应用场景并用代码实现出来。
本节的源码已经上传到github
https://github.com/HobbyBear/codelearning/tree/master/consistenthash
原理介绍
首先我们来看看一致性hash的定义和算法思想,一致性hash算法有别于传统hash算法,例如我们有3个节点,现在要考虑某个key值落到哪个节点上,传统hash算法是将key通过hash函数后通过节点数量进行取模运算得到需要落到的节点序号。
nodeIdx := hashFunc(key)%len(nodes)
传统hash算法在节点数量变化时基本上会导致大量旧数据经过hash得到的节点序号失效, 而一致性hash算法则能够保证只有少部分旧数据需要重新改变需要落到的节点,其余数据依然能够保证节点扩容后,hash计算得到的节点序号和之前一致。
一致性hash算法假设了一个很大的数字空间,比如2的32次方, 节点信息会被映射到这个数字空间的某个数字上,当我们需要看某个key落到哪个节点上时,也需要将key进行hash计算得到某个数字,接着就是找到在这个超大数字空间内,第一个大于该数字的节点。如果没有大于该数字的节点,则将第一个节点作为key需要落到的节点。
这样就等效于整个数字空间构成了一个环形结构,寻找key需要落到的节点上时,则是从key开始顺时针寻找第一个节点。
用下面的示意图来表示这个过程会更好理解
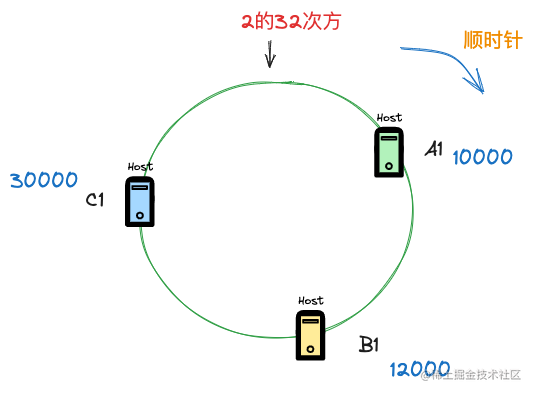
我们假设有3个节点A1,B1,C1, 这三个节点的信息(比如主机名,ip等信息)经过hash运算后得到了3个数字,A1对应10000,B1对应12000,C1 对应30000,现在需要看某个key需要落到哪个节点上,就应该这样来看。
注意这里的节点我是拿服务器来举例,实际上,节点也可以是表,某个key可以看出是表中的某一行,而一致性性hash算法的目的则是看某一行数据应该落到哪个表中,总之你可以发挥你的想象将算法中的事物进行代替抽象,算法的思想终究是不变的。
当某个key经过hash计算后,得到数字9000,那么在顺时针寻找到第一个大于它的节点则是节点A1,如果key经过hash计算后,得到数字11000,那么寻找到的第一个大于它的节点则是节点B1。 注意一种特殊情况,如果key经过hash计算得到的数字是40000,那么此时没有任何一个节点是大于这个数字的,这种情况,正如上图所示,一致性hash算法的数组空间是环形结构,这样key会落到第一个节点A1上。
这个只是最初版本的一致性hash,它会在节点数量较少时,出现分配数据不均匀的情况,比如可能会出现下面的场景
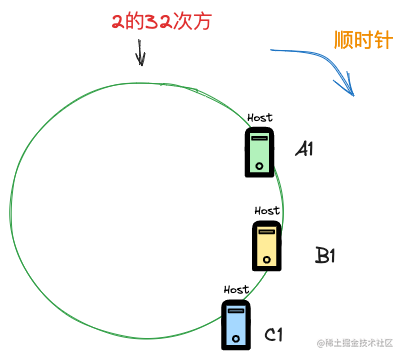
所有的节点都偏向了一侧,这样将会有大量数据落到A1 节点,造成数据分配不均匀。
所以一致性hash算法的改进版本提出虚拟节点的概念,通过引入节点的副本来让整个hash环上的节点数量多起来。
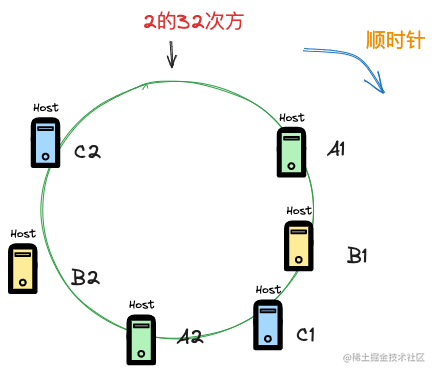
这里假设引入的副本是一个,那么参与分配的key的节点在hash环上则是6个,6个节点会让对hash环的分配更加均匀,注意虚拟节点在实际环境中并不存在,比如这里虚拟节点A2和实际的节点A1指向的其实都是同一个实际环境中的节点。
应用场景
在了解了一致性hash算法的原理后,我们再来看看它的一些适用场景,这样能够明白算法的目的,不至于纸上谈兵。
负载均衡
首先来看下第一种应用场景,在负载均衡中的应用,拿memcache举例,memcache的分布式架构其实是依赖客户端来实现的,客户端将缓存key通过一致性hash算法计算需要缓存到哪台后端服务器上。
而采用一致性hash的好处则是在扩缩容时,不会导致大面积的缓存失效。
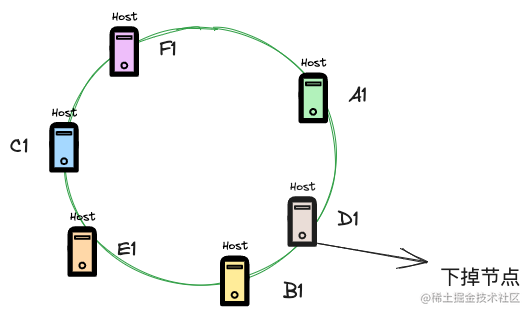
如上图所示,现在要将D1节点下掉,由于一致性hash算法路由节点是顺时针的,那么只会影响到D1和A1之间的数据,这部分数据后续需要在B1节点上进行读取,而其他节点上的数据则不会影响。
其实,从这里应该能够看出,一致性hash算法在负载均衡中一个极大的好处就是,对于有状态的服务,能够做到扩缩容节点时,影响面最小。
分库分表
再来看看在分库分表中的应用,如果分表时采用传统hash算法,当还想扩容表时,不得不面对对所有分表数据进行重新hash,重新写入,这无论是对于磁盘io还是cpu都有极大的压力,我们应该在新增分表时尽量迁移少量的数据,减少影响面,这不正是一致性hash算法的功能吗。
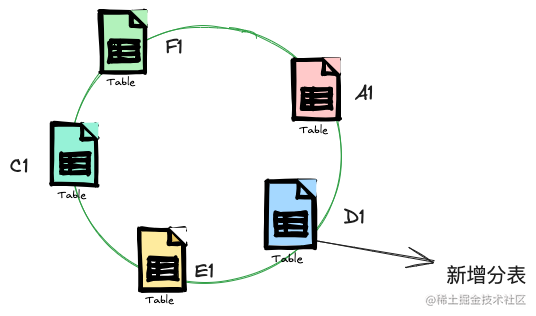
如上图所示,现在新增了分表D1,那么会影响到之前D1到A1的之前的数据,这部分数据之前是存到E1这张表上的,现在要迁移到D1表,所以你可以看到新增一个分表只会设计两张表部分数据的迁移,相比传统hash的全量迁移,优势不言而喻。
代码实现
现在我们来看下如何实现下这个算法。
我们需要将节点信息以及用户key信息映射成一个数字,这里要用到hash函数,hash函数有很多,我们直接用一个,crc32的hash方式,这样返回的数字刚好在2的32次方以内。
func ChecksumIEEE(data []byte) uint32
同时我们需要一个映射结构存储节点在环上的hash key与节点信息,还需要一个有序列表存储hash key,以便于查询用户key对应的节点hash key是哪一个。
这里的代码比较简单,短短20多行即可。
package main
import (
"fmt"
"hash/crc32"
"sort")
func main() {
ch := NewConsistentHash(3)
ch.AddNodes("node1")
ch.AddNodes("node2")
ch.AddNodes("node3")
fmt.Println(ch.GetNode("lanpangzi"))
}
type ConsistentHash struct {
nodes map[uint32]string
keys []uint32
replicates int
}
func NewConsistentHash(replicate int) *ConsistentHash {
return &ConsistentHash{
nodes: make(map[uint32]string),
keys: make([]uint32, 0),
replicates: replicate,
}
}
func (c *ConsistentHash) AddNodes(node string) {
for i := 0; i <= c.replicates; i++ {
nodename := fmt.Sprintf("%s#%d", node, i)
hashKey := crc32.ChecksumIEEE([]byte(node))
c.nodes[hashKey] = nodename
c.keys = append(c.keys, hashKey)
}
sort.Slice(c.keys, func(i, j int) bool {
return c.keys[i] < c.keys[j]
})
}
func (c *ConsistentHash) GetNode(key string) string {
hashKey := crc32.ChecksumIEEE([]byte(key))
nodekeyIndex := sort.Search(len(c.keys), func(i int) bool {
return c.keys[i] >= hashKey
})
if nodekeyIndex == len(c.keys) {
nodekeyIndex = 0
}
return c.nodes[c.keys[nodekeyIndex]]
}
我们搞定了一致性hash算法,代码实现并不难,关键是要搞懂算法的原理以及作用,这样才能灵活运用。
一致性hash算法原理及实践的更多相关文章
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 一致性Hash算法原理及C#代码实现
一.一致性Hash算法原理 基本概念 一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下: 整个空间按顺 ...
- 一致性Hash算法原理,java实现,及用途
学习记录: 一致性Hash算法原理及java实现:https://blog.csdn.net/suifeng629/article/details/81567777 一致性Hash算法介绍,原理,及使 ...
- 【数据结构与算法】一致性Hash算法及Java实践
追求极致才能突破极限 一.案例背景 1.1 系统简介 首先看一下系统架构,方便解释: 页面给用户展示的功能就是,可以查看任何一台机器的某些属性(以下简称系统信息). 消息流程是,页面发起请求查看指定机 ...
- 一致性Hash算法的原理与实现(分布式映射算法)
一致性Hash算法解决的问题: 解决分布式系统中的负载均衡问题 背景问题:有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均发到每台服务器上,每台服务器负载1/N的服务 硬Hash映射:将 ...
- 一致性Hash算法在数据库分表中的实践
最近有一个项目,其中某个功能单表数据在可预估的未来达到了亿级,初步估算在90亿左右.与同事详细讨论后,决定采用一致性Hash算法来完成数据库的自动扩容和数据迁移.整个程序细节由我同事完成,我只是将其理 ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- [速成]了解一致性hash算法
定义 一致性hash算法,在维基百科的定义是: Consistent hashing is a special kind of hashing such that when a hash table ...
随机推荐
- python程序,实现以管理员方式运行程序,也就是提升程序权限
quest UAC elevation from within a Python script? 我希望我的Python脚本能够在Vista上复制文件. 当我从普通的cmd.exe窗口运行它时,不会生 ...
- 粘包,自定义协议,struct模块,粘包解决终极大招
粘包: 1.粘包问题出现的原因: (udp不会出现粘包问题) 1.1.tcp是流式协议,数据像水流一样黏在一起,没有任何边界区分 1.2.收数据没收干净,有残留,就会下一次结果混淆在一起去(客户端接受 ...
- 基于sanic和爬虫创建的代理ip池
搭建免费的代理ip池 需要解决的问题: 使用什么方式存储ip 文件存储 缺点: 打开文件修改文件操作较麻烦 mysql 缺点: 查询速度较慢 mongodb 缺点: 查询速度较慢. 没有查重功能 re ...
- 【FAQ】关于华为推送服务因营销消息频次管控导致服务通讯类消息下发失败的解决方案
一. 问题描述 使用华为推送服务下发IM消息时,下发消息请求成功且code码为80000000,但是手机总是收不到消息: 在华为推送自助分析(Beta)平台查看发现,消息发送触发了频控. 二. 问题原 ...
- Indent----- IndentationError: unexpected indent
Unexpected indent 错误 注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现.但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4 个空格长度作为一个 ...
- 【Lua】VSCode 搭建 Lua 开发环境
前言 最近在找工作,基本所有的岗位都会问到 Lua(甚至拼 UI 的都要求会 Lua),咱能怎么办呢,咱也只能学啊-- 工欲善其事,必先利其器.第一步,先来把环境配置好吧! 当前适用版本: LuaBi ...
- 如何解决Gridea部分主题不渲染Katex的问题
很多好看的主题因为对象不是信息学,所以忽视了公式,即 \(\LaTeX\) . 导致,如果你想渲染一个 \(n\) ,结果成了 nn 这个简单,导入文件即可. 找到主题文件夹,打开 templates ...
- .NET开源分布式锁DistributedLock
一.线程锁和分布式锁 线程锁通常在单个进程中使用,以防止多个线程同时访问共享资源. 在我们.NET中常见的线程锁有: 自旋锁:当线程尝试获取锁时,它会重复执行一些简单的指令,直到锁可用 互斥锁: Mu ...
- 【解决方法】Windows快捷键Win+G无法使用,提示需要新应用打开链接
环境: 系统版本:Windows 10 家庭中文版 问题描述: 描述:按下Win+G后弹出提示框,需要使用新应用以打开此 ms-gamingoverlay 链接 问题解释: 误将Xbox game b ...
- Prism Sample 1
这个样例版本上已经过时了,但与8.1版本仍然兼容. 在本版本中,指定启动项: App.xaml.cs: protected override void OnStartup(StartupEventAr ...