CDC实战:MySQL实时同步数据到Elasticsearch之数组集合(array)如何处理【CDC实战系列十二】
需求背景:
mysql存储的一个字段,需要同步到elasticsearch,并存储为数组,以便于查询。
如下例子,就是查询预期。
PUT /t_test_1/_doc/1
{
"name":"苹果",
"code":[1,2,3]
} PUT /t_test_1/_doc/2
{
"name":"香蕉",
"code":[1,2]
} PUT /t_test_1/_doc/3
{
"name":"橙子",
"code":[1,3,5]
} # 查询code包含1或者3中任意一个或者所有coe都包含的数据
POST /t_test_1/_search
{
"query": {
"bool": {
"filter": [
{
"terms": {
"code": [
"1",
"3"
]
}
}
]
}
}
}
数据同步背景介绍:
1、当前数据同步使用的是kafka + confluent
2、各种数据产品中间件版本:
MySQL5.7.x
es7.15.1
kafka3.2.0
Debezium MySQL connector plug-in 1.9.4.Final
confluentinc-kafka-connect-elasticsearch:13.1.0
详细内容可参考之前的博文
经过调研,找到两种方法实现:
1、第一种使用elasticsearch自带的ingest pipeline处理。话不多少,直接上code。
(1)首先mysql字段num_array设计成varchar,存储格式为'a,b,c,d,e,f';
(2)同步到es变成数组,es对应的字段num_array设计成keyword,便于精确查询,提高性能。
# 创建一个pipeline
PUT _ingest/pipeline/string_to_array_pipeline
{
"description": "Transfer the string which is concat with a separtor to array.",
"processors": [
{
"split": {
"field": "num_array",
"separator": ","
}
},
{
"set": {
"field": "update_user",
"value": "system"
}
},
{
"set": {
"field": "name",
"value": "华山"
}
}
]
}
##t_mountain 设置字段num_array的mapping为keyword,设置default_pipeline =string_to_array_pipeline
PUT /t_mountain
{
"settings": {
"default_pipeline": "string_to_array_pipeline"
},
"mappings" : {
"date_detection" : false,
"properties" : {
"altitude" : {
"type" : "float"
},
"create_time" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss || strict_date_optional_time || epoch_millis"
},
"create_user" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "long"
},
"latitude" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"location" : {
"type" : "geo_point"
},
"logtitude" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"num_array" : {
"type" : "keyword"
},
"ticket" : {
"type" : "float"
},
"update_time" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss || strict_date_optional_time || epoch_millis"
},
"update_user" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
#查询
POST t_mountain/_search
{
"query": {
"bool": {
"filter": [
{
"terms": {
"num_array": [
"a",
"b"
]
}
}
]
}
}
}
2、使用debezium自定义转换实现json字符串转数组
详细内容参考gitee:debezium-custom-converter
或参考github:debezium-custom-converter
简单来说就是mysql存储成varchar格式:比如 'a,b,c,d,e' 或者 '["a","b","c","d"]' 经过自定义converter处理转成list,同步到es就是数组格式,es的所有设置和方法1相同。
------------------------数据同步过程中出现了一个很让人费解的现象---------------------
1、数据同步过程中出现了一个很让人费解的现象:mysql的insert语句可以正常同步的es,且pipeline能正常应用,字段被处理成了数组格式。但是,在mysql中update刚才插入的数据,则数据正常同步到了es,但是也只的default_pipeline没有生效。
2、排查发现是因为同步sink脚本中设置了"write.method":"upsert"导致mysql执行update语句时,目标索引设置的pipeline失效了。
现象令人费解!!!
3、查看官方文档,没有看出来这个解释,怎么就影响到索引设置的pipeline了
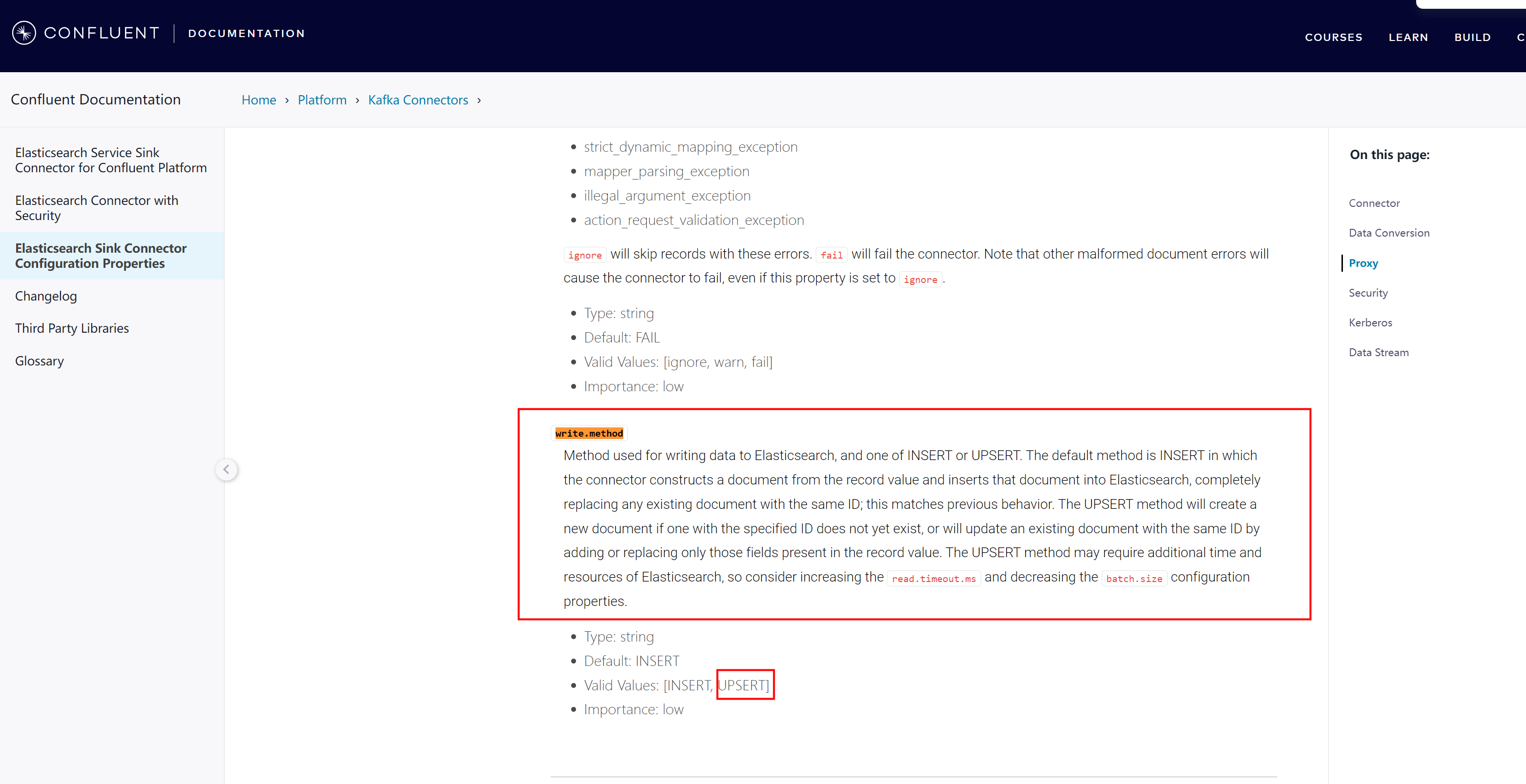
Method used for writing data to Elasticsearch, and one of INSERT or UPSERT. The default method is INSERT in which the connector constructs a document from the record value and inserts that document into Elasticsearch, completely replacing any existing document with the same ID; this matches previous behavior. The UPSERT method will create a new document if one with the specified ID does not yet exist, or will update an existing document with the same ID by adding or replacing only those fields present in the record value. The UPSERT method may require additional time and resources of Elasticsearch, so consider increasing the read.timeout.ms and decreasing the batch.size configuration properties. 用于向 Elasticsearch 中写入数据的方法,以及 INSERT 或 UPSERT 中的一种。默认方法是 INSERT,连接器会根据记录值构建一个文档,并将该文档插入 Elasticsearch,同时完全替换具有相同 ID 的现有文档;这与以前的行为一致。如果指定 ID 的文档还不存在,UPSERT 方法将创建一个新文档,或更新具有相同 ID 的现有文档,只添加或替换记录值中存在的字段。UPSERT 方法可能需要额外的时间和 Elasticsearch 资源,因此请考虑增加 read.timeout.ms 和减少 batch.size 配置属性。
4、遂在本地模拟同步数据,复现了上述现象。然后打开es详细日志追踪:
bin/elasticsearch -E logger.org.elasticsearch.action=trace
先贴出来同步脚本:
source脚本
{
"name": "goods-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "127.0.0.1",
"database.port": "3306",
"database.user": "debezium_user",
"database.password": "@debezium2022",
"database.server.id": "12358",
"snapshot.mode": "when_needed",
"database.server.name": "goods",
"database.include.list": "goods",
"table.include.list": "goods.t_mountain,goods.t_sku,goods.t_spu",
"database.history.kafka.bootstrap.servers": "127.0.0.1:9092",
"database.history.kafka.topic": "dbhistory.goods",
"include.schema.changes": "true"
}
}
sink脚本:
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "goods.goods.t_sku,goods.goods.t_spu,goods.goods.t_mountain,goods001.goods.t_format_date",
"key.ignore": "false",
"connection.url": "http://127.0.0.1:9200",
"name": "elasticsearch-sink",
"type.name": "_doc",
"decimal.handling.mode": "string",
"transforms": "unwrap,key",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "true",
"transforms.unwrap.delete.handling.mode": "drop",
"transforms.key.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.key.field": "id"
}
}
可以发现,此时的sink脚本未设置 "write.method":"upsert",那么该设置的默认值为insert
日志如下:
mysql insert语句,同步到es日志,操作是 index (下面日志中我也做了标记),这是已经经过索引设置的pipeline处理后的数据。
[2024-03-25T01:22:16,232][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] send action [indices:data/write/bulk[s][p]] to local primary [[goods.goods.t_mountain][0]] for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][154], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]] with cluster state version [2312] to [NYz8ptioSBGMQoSB94VGew]
[2024-03-25T01:22:16,233][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] [[goods.goods.t_mountain][0]] op [indices:data/write/bulk[s]] completed on primary for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][154], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
[2024-03-25T01:22:16,235][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] operation succeeded. action [indices:data/write/bulk[s]],request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][154], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
查看elasticsearch源码,从IndexRequest.java的toString方法可以看出,日志输出的是哪些内容。
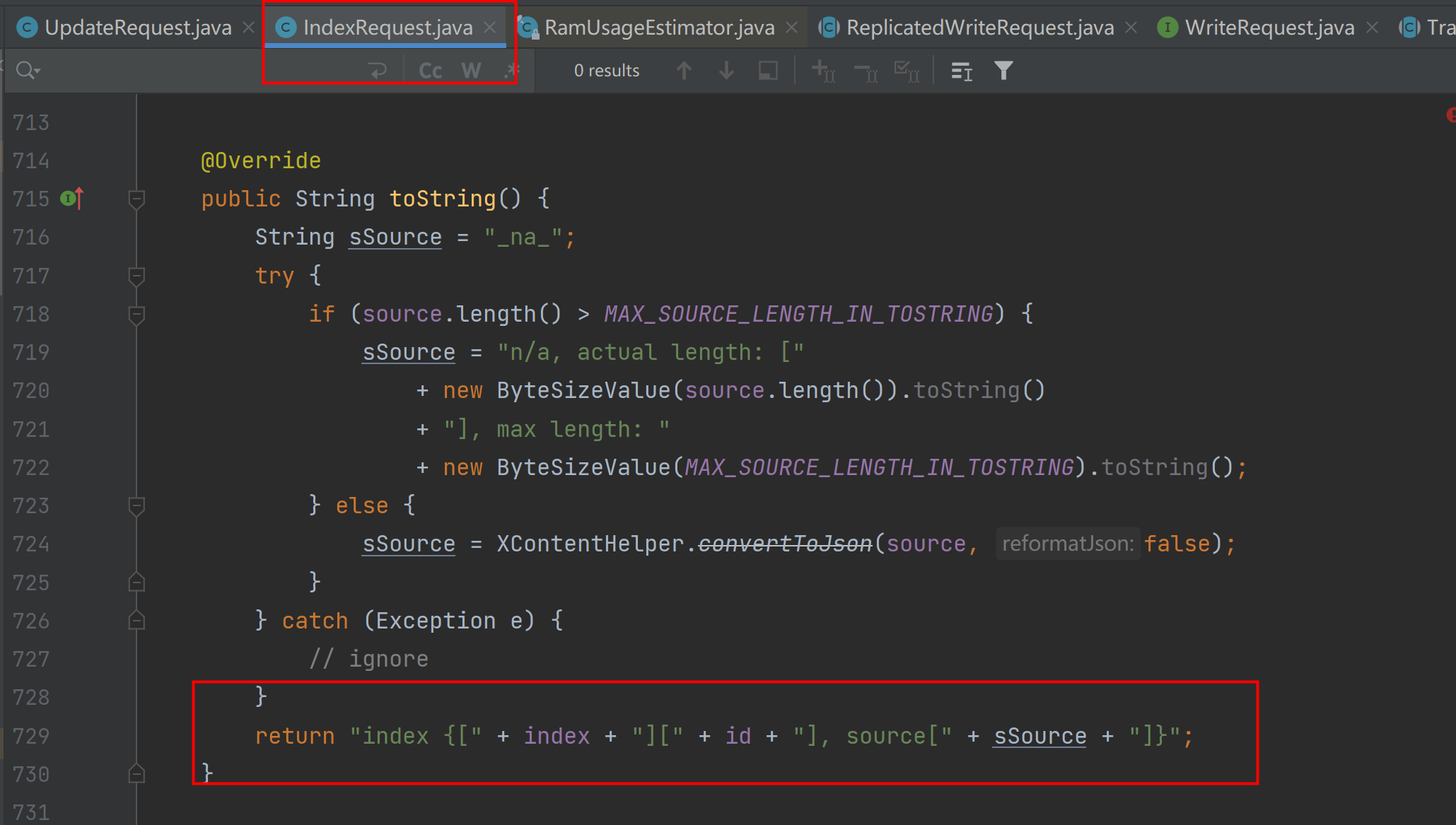
从以上日志可以模拟出es的插入DSL,这是已经经过索引设置的pipeline处理后的数据。
POST _bulk
{"index":{"_id":"154","_index":"t_mountain"}}
{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}
mysql update语句,同步到es日志,操作是 index (下面日志中我也做了标记),这是已经经过索引设置的pipeline处理后的数据。
[2024-03-25T01:23:18,419][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] send action [indices:data/write/bulk[s][p]] to local primary [[goods.goods.t_mountain][0]] for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][154], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711329798000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]] with cluster state version [2312] to [NYz8ptioSBGMQoSB94VGew]
[2024-03-25T01:23:18,421][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] [[goods.goods.t_mountain][0]] op [indices:data/write/bulk[s]] completed on primary for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][154], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711329798000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
[2024-03-25T01:23:18,422][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] operation succeeded. action [indices:data/write/bulk[s]],request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][154], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711329798000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
从以上日志可以模拟出es的插入DSL,和上面的类似。都是插入数据。
POST _bulk
{"index":{"_id":"154","_index":"t_mountain"}}
{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":154,"create_user":"111111","desc":"少华山在陕西渭南华州区"}
5、修改sink脚本,添加一行配置 "write.method":"upsert",重启kafka-connect,继续数据同步
日志如下:
5.1、mysql insert语句,同步到es日志,操作是update(下面日志中我也做了标记),可以看到数据分别存储在doc对象(未经索引设置的pipeline处理的原始数据)和upsert对象(经过索引设置的pipeline处理的原始数据)中:
[2024-03-22T05:44:42,500][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] send action [indices:data/write/bulk[s][p]] to local primary [[goods.goods.t_mountain][0]] for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [update {[goods.goods.t_mountain][_doc][151], doc_as_upsert[false], doc[index {[null][_doc][null], source[{"id":151,"name":"少华山","location":"34.497647,110.073028","latitude":"34.497647","logtitude":"110.073028","altitude":1200.0,"create_user":"111111","create_time":1710419563000,"update_user":null,"update_time":1710420074000,"ticket":0.0,"desc":"少华山在陕西渭南华州区","num_array":"aaaaaa,b,ccccccc"}]}], upsert[index {[null][_doc][null], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}], scripted_upsert[false], detect_noop[true]}]] with cluster state version [1858] to [NYz8ptioSBGMQoSB94VGew]
[2024-03-22T05:44:42,498][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] [[goods.goods.t_mountain][0]] op [indices:data/write/bulk[s]] completed on primary for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][151], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
[2024-03-22T05:44:42,500][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] operation succeeded. action [indices:data/write/bulk[s]],request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][151], source[{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
从elasticsearch源码的UpdateRequest.java类tostring方法中,可以看出日志输出的是哪些内容:
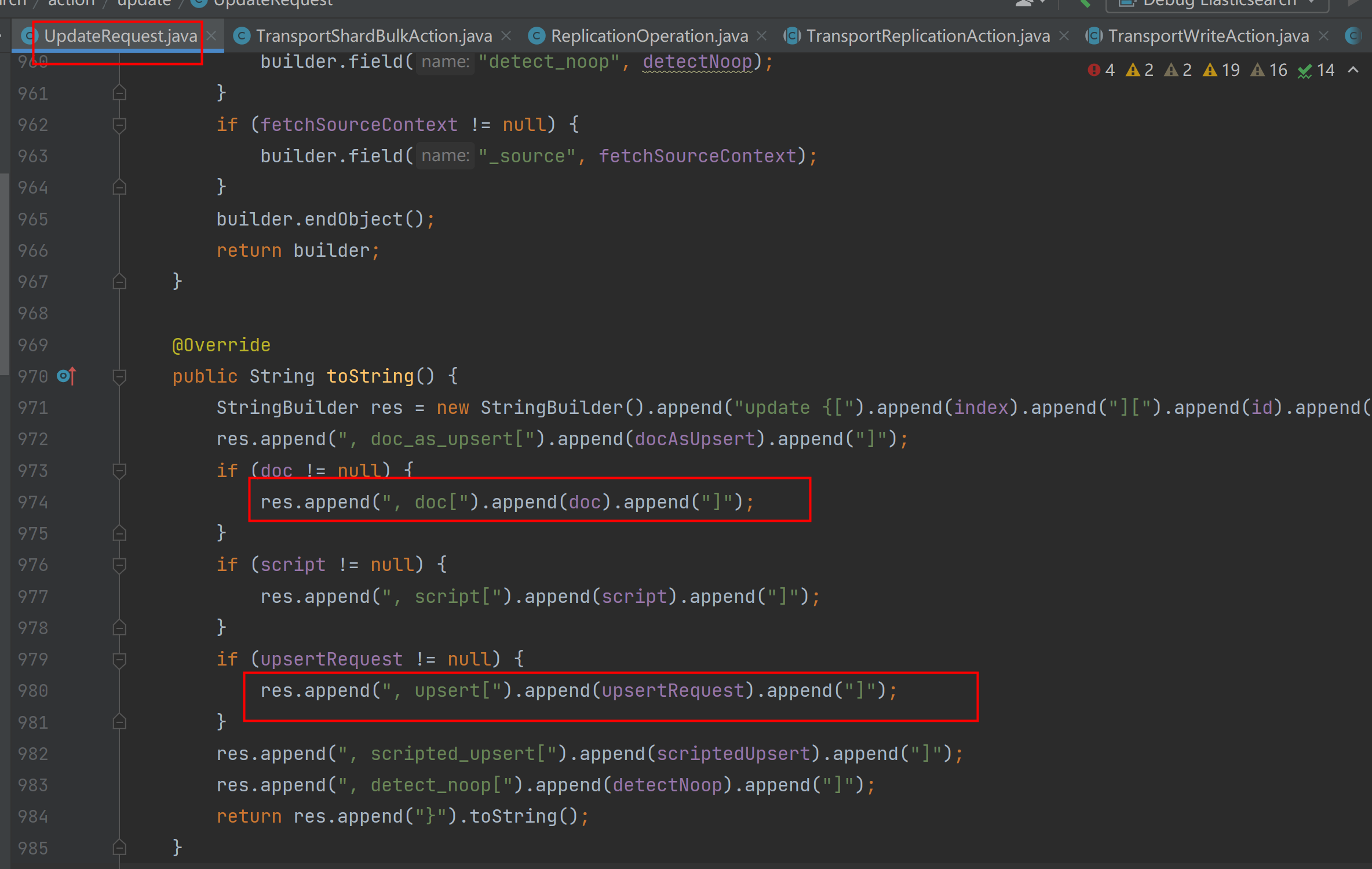
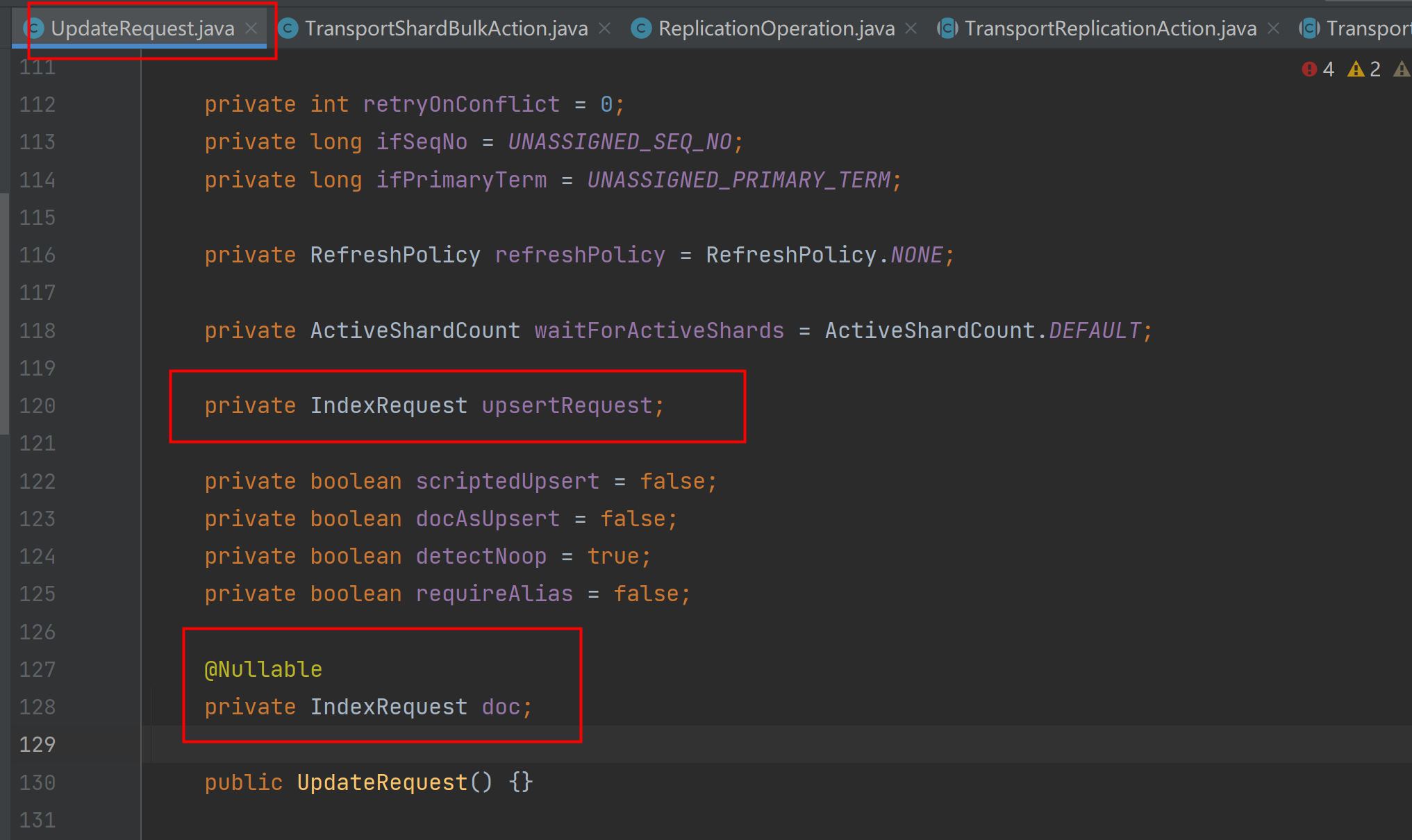
从以上日志可以模拟出es的插入DSL,可以正常同步数据,且经过索引设置的pipeline处理过的数据,正确同步到了es中。
----下面upsert中内容正常保存到了es中,符合预期。
POST _bulk
{"update":{"_id":"151","_index":"t_mountain"}}
{"doc":{"id":151,"name":"少华山","location":"34.497647,110.073028","latitude":"34.497647","logtitude":"110.073028","altitude":1200.0,"create_user":"111111","create_time":1710419563000,"update_user":null,"update_time":1710420074000,"ticket":0.0,"desc":"少华山在陕西渭南华州区","num_array":"aaaaaa,b,ccccccc"},"upsert":{"altitude":1200.0,"num_array":["aaaaaa","b","ccccccc"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1710420074000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"},"doc_as_upsert":false,"scripted_upsert":false, "detect_noop":true}
5.2、mysql update语句,同步到es日志,操作是update(下面日志中我也做了标记),可以看到数据分别存储在doc对象(未经索引设置的pipeline处理的原始数据)和upsert对象(经过索引设置的pipeline处理的原始数据)中:
[2024-03-22T05:49:56,606][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] send action [indices:data/write/bulk[s][p]] to local primary [[goods.goods.t_mountain][0]] for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [update {[goods.goods.t_mountain][_doc][151], doc_as_upsert[false], doc[index {[null][_doc][null], source[{"id":151,"name":"泰山","location":"34.497647,110.073028","latitude":"34.497647","logtitude":"110.073028","altitude":1200.0,"create_user":"111111","create_time":1710419563000,"update_user":"666666","update_time":1711086596000,"ticket":0.0,"desc":"少华山在陕西渭南华州区","num_array":"a,b,c,d,e,f,g,h"}]}], upsert[index {[null][_doc][null], source[{"altitude":1200.0,"num_array":["a","b","c","d","e","f","g","h"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711086596000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}], scripted_upsert[false], detect_noop[true]}]] with cluster state version [1927] to [NYz8ptioSBGMQoSB94VGew]
[2024-03-22T05:49:56,610][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] [[goods.goods.t_mountain][0]] op [indices:data/write/bulk[s]] completed on primary for request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][151], source[{"altitude":1200.0,"num_array":"a,b,c,d,e,f,g,h","create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711086596000,"update_user":"666666","name":"泰山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
[2024-03-22T05:49:56,613][TRACE][o.e.a.b.TransportShardBulkAction] [esserver001-9200] operation succeeded. action [indices:data/write/bulk[s]],request [BulkShardRequest [[goods.goods.t_mountain][0]] containing [index {[goods.goods.t_mountain][_doc][151], source[{"altitude":1200.0,"num_array":"a,b,c,d,e,f,g,h","create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711086596000,"update_user":"666666","name":"泰山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"}]}]]
从以上日志可以模拟出es的插入DSL:
----下面doc中内容正常保存到了es中,upsert中的内容未更新到es中,问题就出在这里!!!!!!
POST _bulk
{"update":{"_id":"151","_index":"t_mountain"}}
{"doc":{"id":151,"name":"泰山","location":"34.497647,110.073028","latitude":"34.497647","logtitude":"110.073028","altitude":1200.0,"create_user":"111111","create_time":1710419563000,"update_user":"666666","update_time":1711086596000,"ticket":0.0,"desc":"少华山在陕西渭南华州区","num_array":"a,b,c,d,e,f,g,h"},"upsert":{"altitude":1200.0,"num_array":["a","b","c","d","e","f","g","h"],"create_time":1710419563000,"ticket":0.0,"latitude":"34.497647","logtitude":"110.073028","update_time":1711086596000,"update_user":"system","name":"华山","location":"34.497647,110.073028","id":151,"create_user":"111111","desc":"少华山在陕西渭南华州区"},"doc_as_upsert":false,"scripted_upsert":false, "detect_noop":true}
elasticsearch更新,doc里面的内容是部分更新,设置了几个字段就更新几个字段,不会覆盖doc未设置的字段。doc和upsert都存在的情况下,如果指定更新的文档不存在,则“If the document does not already exist, the contents of the upsert element are inserted as a new document.”,所以本例中5.1同步数据符合预期。如果指定的文档存在,doc和upsert都存在的情况下,则doc里面的内容更新到es中,所以本例中5.2同步数据不符合预期,upsert中经过索引设置的pipeline处理过的数据为正确同步更新到es中。这就是bug出现的原因。
总结:
1、合理设置参数,"write.method":"upsert" 、"write.method":"insert"
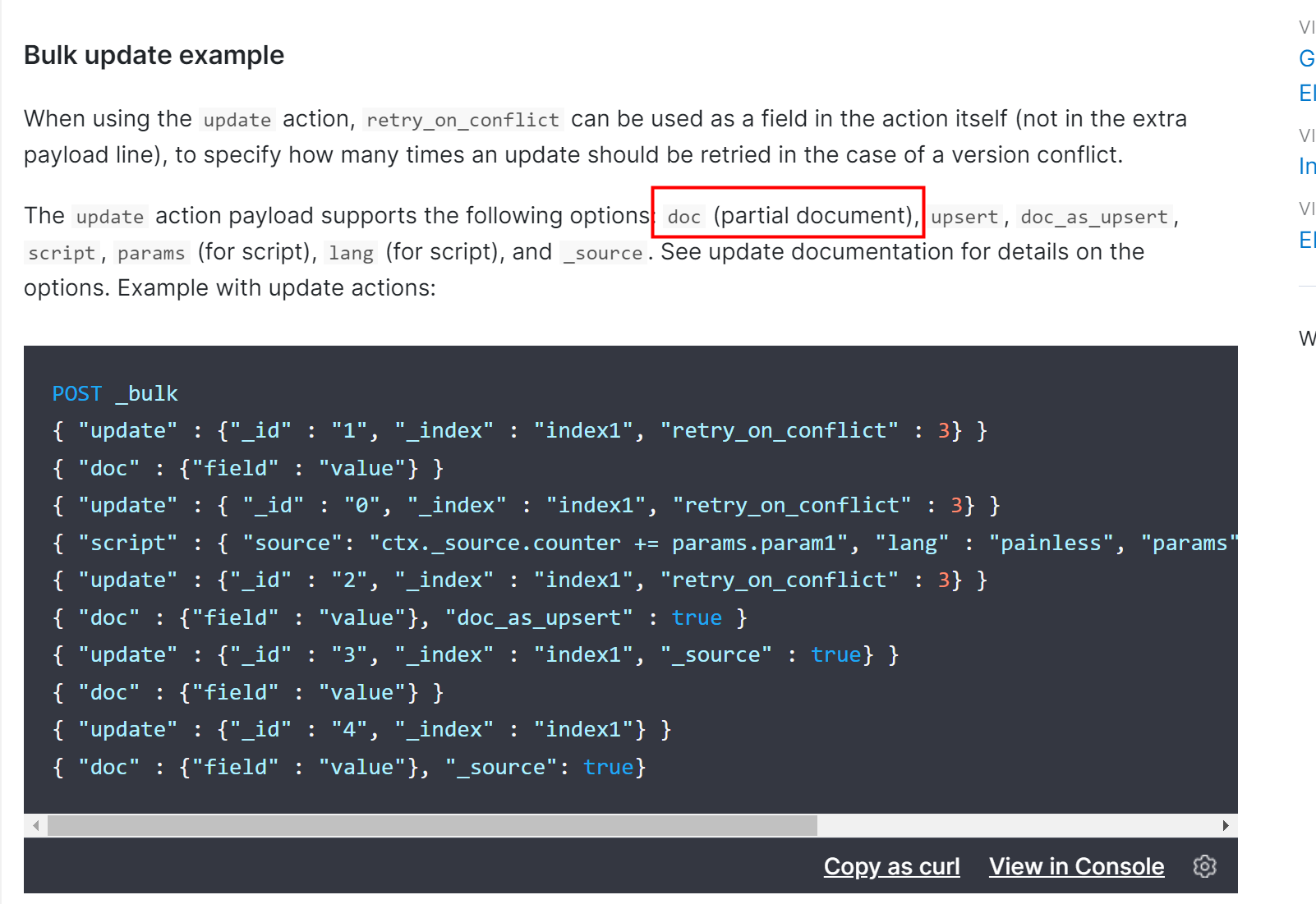
设置了参数"write.method":"upsert"。mysql的update语句执行到es就是走的bulk部分更新,就会导致索引设置的pipeline失效,官方文档没看到特殊说明,这一块描述不是很清晰,但仔细查看,能略显端倪。
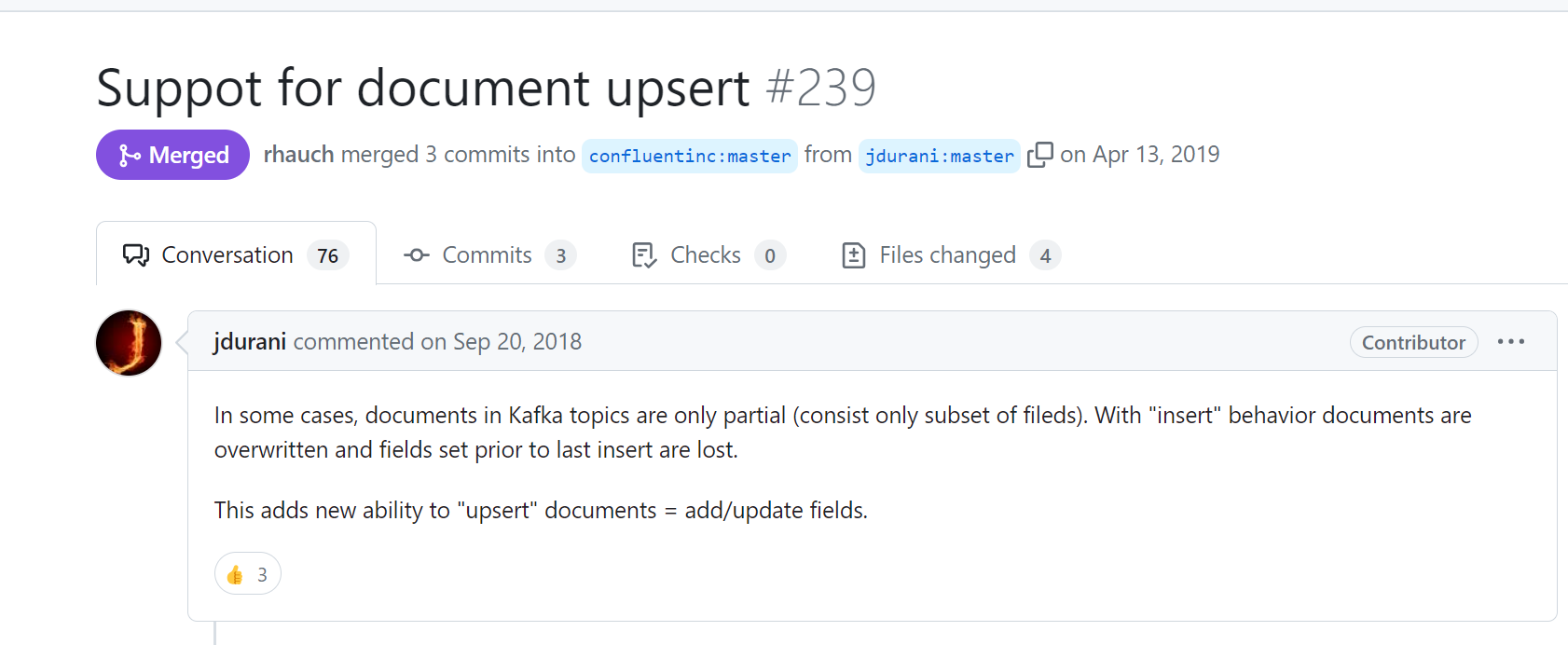
confluent这个设置看github上说的是为了避免数据被覆盖。所以部分更新的情况就设置为upsert。如果同步的时候不管是新增还是更新,source读取的数据都是包含完整字段的,就不存在数据被覆盖的问题,就可以设置成insert。
因为是通过debezium+kafka cnnect+confluent同步数据,无法设置elasticsearch批量更新的参数,因此在设置上述参数时要慎重,通常mysql同步数据到es设置成insert就可以了,不存在更新数据时旧数据被覆盖的情况。
如果不能修改sink脚本配置,那么可以创建一个单独的sink脚本只处理这一张设置了指定pipeline的索引,同时配合es索引设置的alias,亦可轻松解决问题。
2、如果是直接操作elasticsearch的更新,可以直接设置doc或者,upsert等对象。结合"doc_as_upsert"参数也可以完成数据的正确更新。
# 创建一个pipeline
PUT _ingest/pipeline/string_to_array_pipeline
{
"description": "Transfer the string which is concat with a separtor to array.",
"processors": [
{
"split": {
"field": "num_array",
"separator": ","
}
},
{
"set": {
"field": "update_user",
"value": "system"
}
},
{
"set": {
"field": "name",
"value": "华山"
}
}
]
} ##t_mountain
PUT /t_mountain
{
"settings": {
"default_pipeline": "string_to_array_pipeline"
},
"mappings" : {
"date_detection" : false,
"properties" : {
"altitude" : {
"type" : "float"
},
"create_time" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss || strict_date_optional_time || epoch_millis"
},
"create_user" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "long"
},
"latitude" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"location" : {
"type" : "geo_point"
},
"logtitude" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"num_array" : {
"type" : "keyword"
},
"ticket" : {
"type" : "float"
},
"update_time" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss || strict_date_optional_time || epoch_millis"
},
"update_user" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
# #A 部分buck更新t_mountain
POST _bulk
{"update":{"_id":"155","_index":"t_mountain"}}
{"doc":{"id":155,"name":"泰山4","location":"34.497647,110.073028","latitude":"34.497647","logtitude":"110.073028","altitude":1200,"create_user":"111111","create_time":1710419563000,"update_user":"777777","update_time":1711086596000,"ticket":0,"desc":"少华山在陕西渭南华州区","num_array":"a,b,c,d"}}
# #B buck插入新数据t_mountain
POST _bulk
{"index":{"_id":"155","_index":"t_mountain"}}
{"id":155,"name":"泰山3","location":"34.497647,110.073028","latitude":"34.497647","logtitude":"110.073028","altitude":1200,"create_user":"111111","create_time":1710419563000,"update_user":"777777","update_time":1711086596000,"ticket":0,"desc":"少华山在陕西渭南华州区","num_array":"a,b,c,d"}
GET t_mountain/_search?version=true
{
"query": {
"term": {
"id": {
"value": "155"
}
}
}
}
--上面例子说明:
1、先执行#B,正常写入,索引设置的pipeline生效,再执行#A,正常更新,但是索引设置的pipeline没有生效。(完美复现上面问题)
2、先执行#A,此时报错: "reason" : "[_doc][155]: document missing",因为默认的"doc_as_upsert":false设置是false,将这个修改为true,正常写入数据。且索引设置的pipeline正常执行。
3、先执行#B,正常写入,索引设置的pipeline生效,再执行#A,此时设置"doc_as_upsert":true,正常更新,索引设置的pipeline正常执行。
----在这个请求中,"doc_as_upsert":true指示Elasticsearch,如果指定的文档不存在,就将doc部分的内容作为新文档插入。这样,你就不会因为文档不存在而收到错误,而是会创建一个新的文档。
好了,"doc_as_upsert":true这个参数就可以帮助我们灵活处理elasticsearch更新相关的需求.
参考文档:
elasticsearch官方文档updateelasticsearch官方文档bulk
kafka-connect-elasticsearchconfluent文档
CDC实战:MySQL实时同步数据到Elasticsearch之数组集合(array)如何处理【CDC实战系列十二】的更多相关文章
- elasticsearch -- Logstash实现mysql同步数据到elasticsearch
配置 安装插件由于这里是从mysql同步数据到elasticsearch,所以需要安装jdbc的入插件和elasticsearch的出插件:logstash-input-jdbc.logstash-o ...
- mysql实时同步到mssql的解决方案
数据库在应用程序中是必不可少的部分,mysql是开源的,所以很多人它,mssql是微软的,用在windows平台上是非常方便的,所以也有很多人用它.现在问题来了,如何将这两个数据库同步,即数据内容保持 ...
- 使用Logstash同步数据至Elasticsearch,Spring Boot中集成Elasticsearch实现搜索
安装logstash.同步数据至ElasticSearch 为什么使用logstash来同步,CSDN上有一篇文章简要的分析了以下几种同步工具的优缺点:https://blog.csdn.net/la ...
- mysql 同步数据到 ElasticSearch 的方案
MySQL Binlog 要通过 MySQL binlog 将 MySQL 的数据同步给 ES, 我们只能使用 row 模式的 binlog.如果使用 statement 或者 mixed forma ...
- 利用logstash从mysql同步数据到ElasticSearch
前面一篇已经把logstash和logstash-input-jdbc安装好了. 下面就说下具体怎么配置. 1.先在安装目录bin下面(一般都是在bin下面)新建两个文件jdbc.conf和jdbc. ...
- 用canal监控binlog并实现mysql定制同步数据的功能
业务背景 写任何工具都不能脱离实际业务的背景.开始这个项目的时候是因为现有的项目中数据分布太零碎,零零散散的分布在好几个数据库中,没有统一的数据库来收集这些数据.这种情况下想做一个大而全的会员中心系统 ...
- Clickhouse单机部署以及从mysql增量同步数据
背景: 随着数据量的上升,OLAP一直是被讨论的话题,虽然druid,kylin能够解决OLAP问题,但是druid,kylin也是需要和hadoop全家桶一起用的,异常的笨重,再说我也搞不定,那只能 ...
- MYSQL5.7实时同步数据到TiDB
操作系统:CentOS7 mysql版本:5.7 TiDB版本:2.0.0 同步方法:使用TiDB提供的工具集进行同步 说明: 单机mysql同步时,可以直接使用binlog同步, 但mysql集群进 ...
- rsync简介与rsync+inotify配置实时同步数据
rsync简介 rsync是linux系统下的数据镜像备份工具.使用快速增量备份工具Remote Sync可以远程同步,支持本地复制,或者与其他SSH.rsync主机同步. rsync特性 rsync ...
- Mongo同步数据到Elasticsearch
个人博客:https://blog.sharedata.info/ 最近需要把数据从Mongo同步到Elasticsearch环境:centos6.5python2.7pipmongo-connect ...
随机推荐
- 轻松玩转makefile | 变量与模式
前言 本文通过简单的几个示例,以及对同一个Makefile进行几个版本的迭代,帮助快速的理解变量和模式规则的使用. 1.回顾 在上一篇文章中,我们使用Makefile编译fun.c和main.c这两个 ...
- 区间dp-Palindrome
Palindrome 题意:给一个字符串,问最少加上多少个字符,可以使这个字符串成为回文串 思路一.直接dp(会爆内存) dp[i][j]表示区间[i,j]之间有最少需要加上多少个字符 状态转移方程: ...
- 《系列二》-- 5、单例bean缓存的获取
目录 1 判断bean是否完成整个加载流程 2 判断当前bean是否被加载过,是否已作为提前暴露的bean 关于循环依赖 阅读之前要注意的东西:本文就是主打流水账式的源码阅读,主导的是一个参考,主要内 ...
- 机器学习策略篇:详解正交化(Orthogonalization)
正交化 这是一张老式电视图片,有很多旋钮可以用来调整图像的各种性质,所以对于这些旧式电视,可能有一个旋钮用来调图像垂直方向的高度,另外有一个旋钮用来调图像宽度,也许还有一个旋钮用来调梯形角度,还有一个 ...
- 内存管理机制 & 垃圾回收机制
内存管理机制 python是由c开发出来的. 看源码分析,下载python安装包tar包 解压后主要看Include和Objects这两个文件夹 # 分析 在创建对象时,如 v = 0.3 源码内部: ...
- Java是解释型语言么
基础概念 JVM虚拟机会将.java类文件编译成.class文件--字节码文件,这大家都知道. 代码运行时还需要将.class字节码文件翻译成机器码才能执行. 解释执行:将编译好的字节码一行一行地翻译 ...
- 【Azure Function App】本地运行的Function发布到Azure上无法运行的错误分析
问题描述 Azure Function部署后未执行,查看日志发现错误信息: 2023-12-19T11:12:27.145 [Verbose] Host configuration applied.2 ...
- 【Azure 微服务】记一次错误的更新Service Fabric 证书而引发的集群崩溃而只能重建
问题描述 错误的操作步骤: 1)更新Service Fabric 的证书,制定了次要证书(Secondary),但是只修改了Service Fabric Cluster证书,而没有指定VMSS(虚拟机 ...
- 【Azure 应用服务】在Azure上部署一套VUE框架的单页面应用,有什么可以参考的文档呢?
问题描述 在Azure上部署一套VUE框架的单页面应用,有什么可以参考的文档呢? 问题回答 Azure官方上并没有VUE框架的实例代码,但是可以参考Node JS项目,来进行设置. 在 Azure 中 ...
- 【Azure Redis 缓存】定位Java Spring Boot 使用 Jedis 或 Lettuce 无法连接到 Redis的网络连通性步骤
问题描述 Java Spring Boot的代码在IDE里面跑可以连上 Azure 的 Redis服务,打包成Image放在容器里面跑,就连不上azure的redis服务,错误消息为: Unable ...