解读分布式调度平台Airflow在华为云MRS中的实践
摘要:Airflow是一个使用Python语言编写的分布式调度平台,通过DAG(Directed acyclic graph 有向无环图)来管理任务。
本文分享自华为云社区《分布式调度平台Airflow在华为云MRS中的实践》,作者: 啊喔YeYe 。
介绍
Airflow是一个使用Python语言编写的分布式调度平台,通过DAG(Directed acyclic graph 有向无环图)来管理任务,不需要知道业务数据的具体内容,设置任务的依赖关系即可实现任务调度。其平台拥有和Hive、Presto、MySQL、HDFS、Postgres等数据源之间交互的能力,并且提供了hook,使其拥有很好地扩展性。
MapReduce服务提供租户完全可控的企业级大数据集群云服务,可轻松运行Hadoop、Spark、HBase、Kafka、Storm等大数据组件。Airflow对接MapReduce服务后,可依靠Airflow平台提供的命令行界面和一个基于Web的用户界面,可以可视化管理依赖关系、监控进度、触发任务等
环境准备
- 在华为云购买弹性云服务器ECS,用于安装运行Airflow,并绑定弹性公网IP,用于访问公网安装Airflow服务
- 已开通MRS 3.x普通集群
- 弹性云服务器ECS的虚拟私有云和安全组需与MRS普通集群一致,其公共镜像建议选择CentOS 8.2 64bit
安装Airflow
1. 登录已购买的Linux弹性云服务器,执行以下命令升级pip版本
pip3 install --upgrade pip==20.2.4
2. 安装Airflow以及创建登录Airflow的admin用户
使用vim 脚本名.sh新建脚本,写入如下内容并保存,使用sh 脚本名.sh执行脚本,执行完成后会创建登录Airflow的admin用户,并输入密码完成创建。本脚本会完成Airflow的安装以及创建登录Airflow的admin用户。脚本含义见注释。
# airflow needs a home, ~/airflow is the default,
# but you can lay foundation somewhere else if you prefer
# (optional)
export AIRFLOW_HOME=~/airflow AIRFLOW_VERSION=2.0.1
PYTHON_VERSION="$(python3 --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
# For example: 3.6
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# For example: https://raw.githubusercontent.com/apache/airflow/constraints-2.0.1/constraints-3.6.txt
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}" # initialize the database
airflow db init airflow users create \
--username admin \
--firstname Peter \
--lastname Parker \
--role Admin \
--email spiderman@superhero.org
3.执行以下命令启动Airflow WebServer
airflow webserver --port 8080 -D
4. 执行以下命令启动Airflow Scheduler
airflow scheduler -D

5. 访问Airflow WebUI
在本地浏览器输入“http://ECS弹性IP:8080”网址,进入Airflow WebUI登录界面
登录之后:
提交spark作业至MRS
1. 参考安装客户端在运行Airflow的弹性云服务器ECS上安装MRS客户端
例如安装客户端到/opt/client目录下,安装命令:
sh ./install.sh /opt/client/ -o chrony
2. 在安装Airflow的目录下新建目录"dags"
如Airflow安装目录是“/root/airflow”,新建目录“/root/airflow/dags”
3. 新建提交Spark作业的Python脚本
在新建目录下使用vim 脚本名.py新建python脚本并保存,脚本内容如下:
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago args = {
'owner': 'airflow',
} dag = DAG(
dag_id='spark-pi',
default_args=args,
start_date=days_ago(200),
schedule_interval='@once',
dagrun_timeout=timedelta(minutes=300),
tags=['spark'],
) run_this = BashOperator(
task_id='run_on_yarn',
# 其他组件命令参考MRS组件开发指南,将任务提交或运行命令替换到bash_command变量
bash_command='source /opt/client/bigdata_env;spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/client/Spark2x/spark/examples/jars/spark-examples_2.11-2.4.5-hw-ei-302023.jar 10',
#bash_command='echo "run"; echo 0 >> /tmp/test',
dag=dag,
) run_this
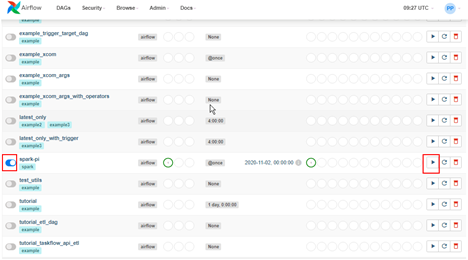
4. 登录Airflow WebUI,单击“spark-pi”左侧的开关按钮,然后单击右侧的三角按钮运行
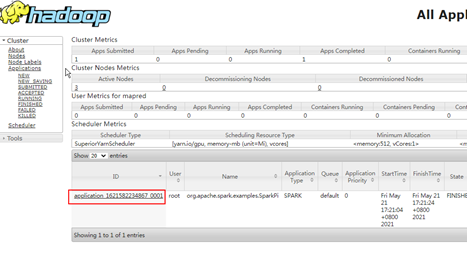
5. 登录Manager页面,选择“集群 > 服务 > Yarn > 概览”
6. 步单击“ResourceManager WebUI”后面对应的链接,进入Yarn的WebUI页面,查看Spark任务是否运行
解读分布式调度平台Airflow在华为云MRS中的实践的更多相关文章
- 华为云MRS支持lakeformation能力,打造一站式湖仓,释放数据价值
摘要:对云端用户而言,业务价值发现是最重要的,华为MRS支持LakeFormation后,成功降低了数据应用的成本,帮助客户落地"存"与"算"的管理,加快推进了 ...
- Elastic-Job 分布式调度平台
概述 referred:http://elasticjob.io/docs/elastic-job-lite/00-overview Elastic-Job是一个分布式调度解决方案,由两个相互独立的子 ...
- 中国DevOps平台市场,华为云再次位居领导者位置
摘要:华为云软件开发生产线DevCloud在市场份额和发展战略两大维度均排名第一,再次位居领导者位置. 9月21日 ,国际权威分析师机构IDC发布<IDC MarketScape: 中国 Dev ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
- 华为云的API调用实践(python版本)
一.结论: 1.华为云是符合openstack 社区的API,所以,以社区的API为准.社区API见下面的链接. https://developer.openstack.org/api-ref/net ...
- 华为云函数中使用云数据库的JavaScript SDK基础入门
背景介绍 使用云数据库Server端的SDK,此处我以华为提供的官方Demo为例,他们的Demo也已经开源放在了GitHub上,大家需要的可以自行下载. https://github.com/AppG ...
- 分布式调度平台XXL-JOB源码分析-执行器端
上一篇文章已经说到调度中心端如何进行任务管理及调度,本文将分析执行器端是如何接收到任务调度请求,然后执行业务代码的. XxlJobExecutorApplication为我们执行器的启动项,其中有个X ...
- 分布式调度平台XXL-JOB源码分析-调度中心
架构图 上图是我们要进行源码分析的2.1版本的整体架构图.其分为两大块,调度中心和执行器,本文先分析调度中心,也就是xxl-job-admin这个包的代码. 关键bean 在application.p ...
- 分布式调度平台XXL-JOB源码分析-时序图
整体流程 初始化 任务调度 任务执行 任务回调 注册心跳
- 全链路压测平台(Quake)在美团中的实践
背景 在美团的价值观中,以“客户为中心”被放在一个非常重要的位置,所以我们对服务出现故障越来越不能容忍.特别是目前公司业务正在高速增长阶段,每一次故障对公司来说都是一笔非常不小的损失.而整个IT基础设 ...
随机推荐
- hammer.js学习
demo:https://github.com/fei1314/HammerJs/tree/master 知识点: hammer--手势识别:点击.长按.滑动.拖动.旋转.缩放 方法: tap 快速的 ...
- 阿里发布AI编码助手:通义灵码,兼容 VS Code、IDEA等主流编程工具
今天是阿里云栖大会的第一天,相信场外的瓜,大家都吃过了.这里就不说了,有兴趣可以看看这里:云栖大会变成相亲现场,最新招婿鄙视链来了... . 这里主要说说阿里还发布了一款AI编码助手,对于我们开发者来 ...
- vscode编写keil工程项目
vscode 前言 1 安装vscode 2 安装插件 2.1 设置中文 2.2 安装Keil Assistant 2.3 常用安装 3 快捷键 前言 我使用vscode只是用来为了弥补keil编写的 ...
- 混合应用与Hybrid App开发上架流程透析
Hybrid App(混合 App)已经成为大家接触最为广泛的 App 形式,不管是我们用到的微信.支付宝还是淘宝.京东等大大小小的应用都非常热衷于Hybrid App 带来的研发效率提升和灵活性. ...
- Java——设计模式
一.概述 设计模式是历代程序员总结出的经验 二.分类 创建型模式:简单工厂模式 工厂方法模式 单例模式:饿汉式(开发) 懒汉式(面试) 行为型模式 结构型模式 三.简单工厂模式 一个工厂中可以创建很多 ...
- Java8新特性之FlatMap&Reduce
1.FlagMap // flatMap:接收一个T返回一个R,将一个元素转为一个新的流 ;R apply(T t); <R> Stream<R> flatMap(Functi ...
- EF Core助力信创国产数据库
前言 国产数据库作为国产化替代的重要环节,在我国信创产业政策的指引下实现加速发展,我们国产数据库已进入百花齐放的快速发展期,相信接触到涉及到政府类等项目的童鞋尤为了解,与此同时我们有一部分也在使用各种 ...
- 如何使用 Helm 在 K8s 上集成 Prometheus 和 Grafana|Part 1
本系列将分成三个部分,您将学习如何使用 Helm 在 Kubernetes 上集成 Prometheus 和 Grafana,以及如何在 Grafana 上创建一个简单的控制面板.Prometheus ...
- bash shell笔记整理——tail命令
作用 Print the last 10 lines of each FILE to standard output. With more than one FILE, precede each wi ...
- 华企盾DSC缩略图某些类型勾选取消不掉
案例:pdf取消勾选后,再次打开还是勾选的 解决方法:文件类型的其它分组也添加了pdf类型,所以默认会勾选回去,需要把其它的也取消勾选